Druid源码结构和查询执行过程

遇到一个Druid查询的问题, 想着看源码找找原因, 所以有了本篇源码解读的记录 (虽然最后问题不是靠这个解决的)
写本文时, druid的github地址中的/apache/incubator-druid悄悄变成/apache/druid, 应该是要毕业了. 本文基于Druid 0.14.0版本.
#0 Druid源码结构
Druid架构
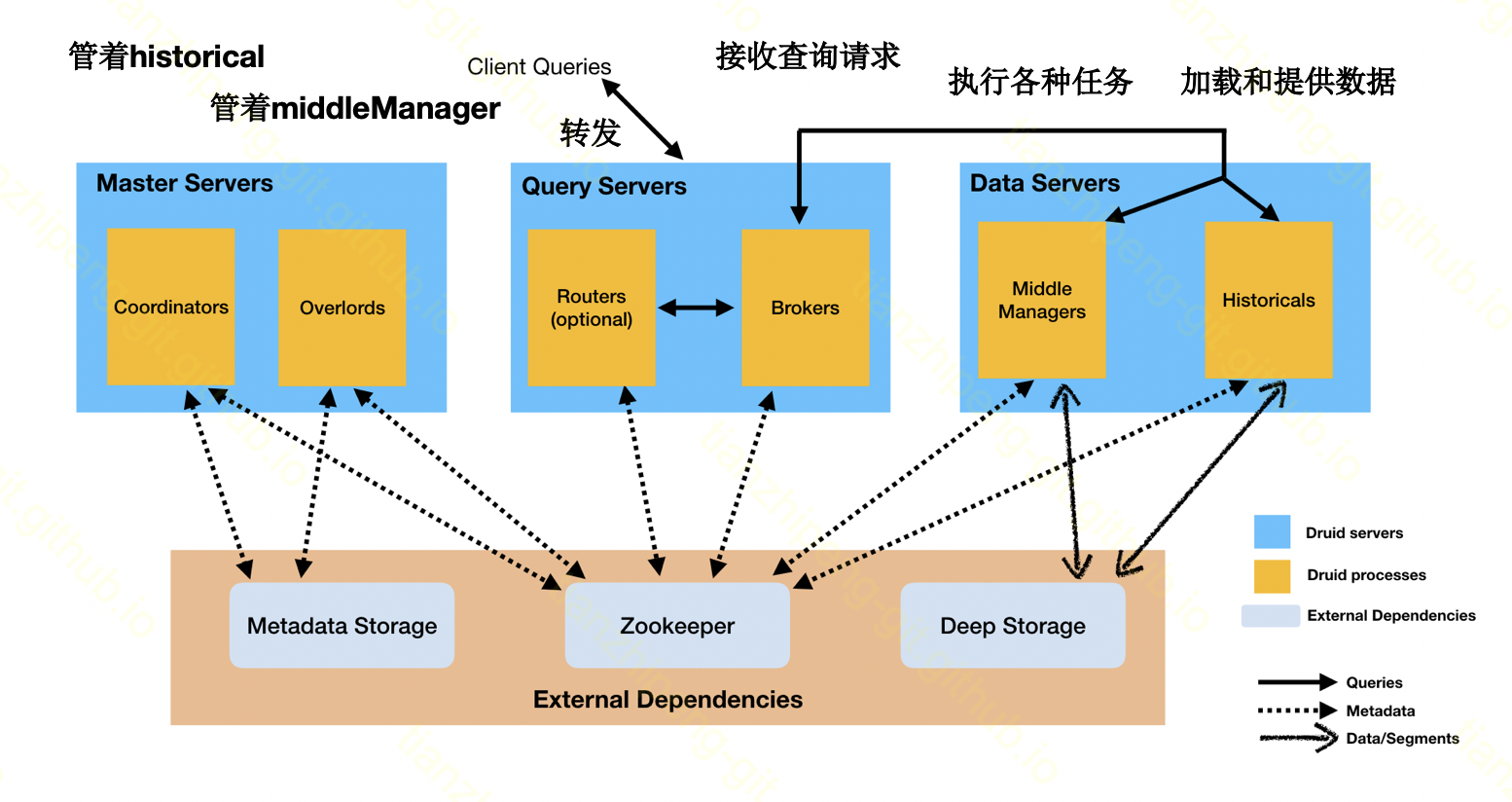 先简单过一下druid的一个架构. 从图中可以看出, druid共有6种内部节点, 3种外部依赖.
先简单过一下druid的一个架构. 从图中可以看出, druid共有6种内部节点, 3种外部依赖.
先说简单的, Metadata就是一个数据库, 存储一些元信息, ZK大家都知道, 在hadoop生态圈, 只要用它, 就是作分布式一致性的, DeepStorage就是文件底层存储, 我们一般都用HDFS, 有一点注意的是, 无论数据是怎么进来的, 都要先到deepStorage, 再从deepStorage加载到historical节点.
上面这6个节点从右往左看,
- Historical节点, 是真的提供数据服务的, 所有供我们查询的数据都是加载在historical节点的内存里的
- MiddleManager, 负责数据接入的节点, 无论是实时任务还是批量任务, 都是交给MiddleManager来处理的, 当然middleManager内部不同任务会启动子进程来处理啊. 有一点注意的是, 实时任务的时候, 由于数据还没来到- historical节点上, 所以查询请求要从这个实时节点查实时数据
- Broker节点负责接收外部的查询请求, 像刚才所说, 将查询交给底层的middle或historical来查询
- Overlord节点负责分配任务, 他和middleManager是合作的, 但是如图所示并不直接通信, 而是用zk来交互信息
- Coordinator负责分配segment, 他和historical是合作的, 这两个主要是管理的节点
- Router是一个可选的节点, 可以理解为nginx, 因为整个druid有coordinator, orverlord和broker三种节点对外提供的接口, 而且还有个web界面, router将这些统一做个转发
这里面节点虽然多, 但确实是分工合作的, 互相之间也没有多少耦合, 我曾经试验了一下, 这六个节点我只启动historical一个, 也能从这个节点查询数据. 这体现了druid所说的CQRS设计(命令查询职责分离).
Druid数据模型
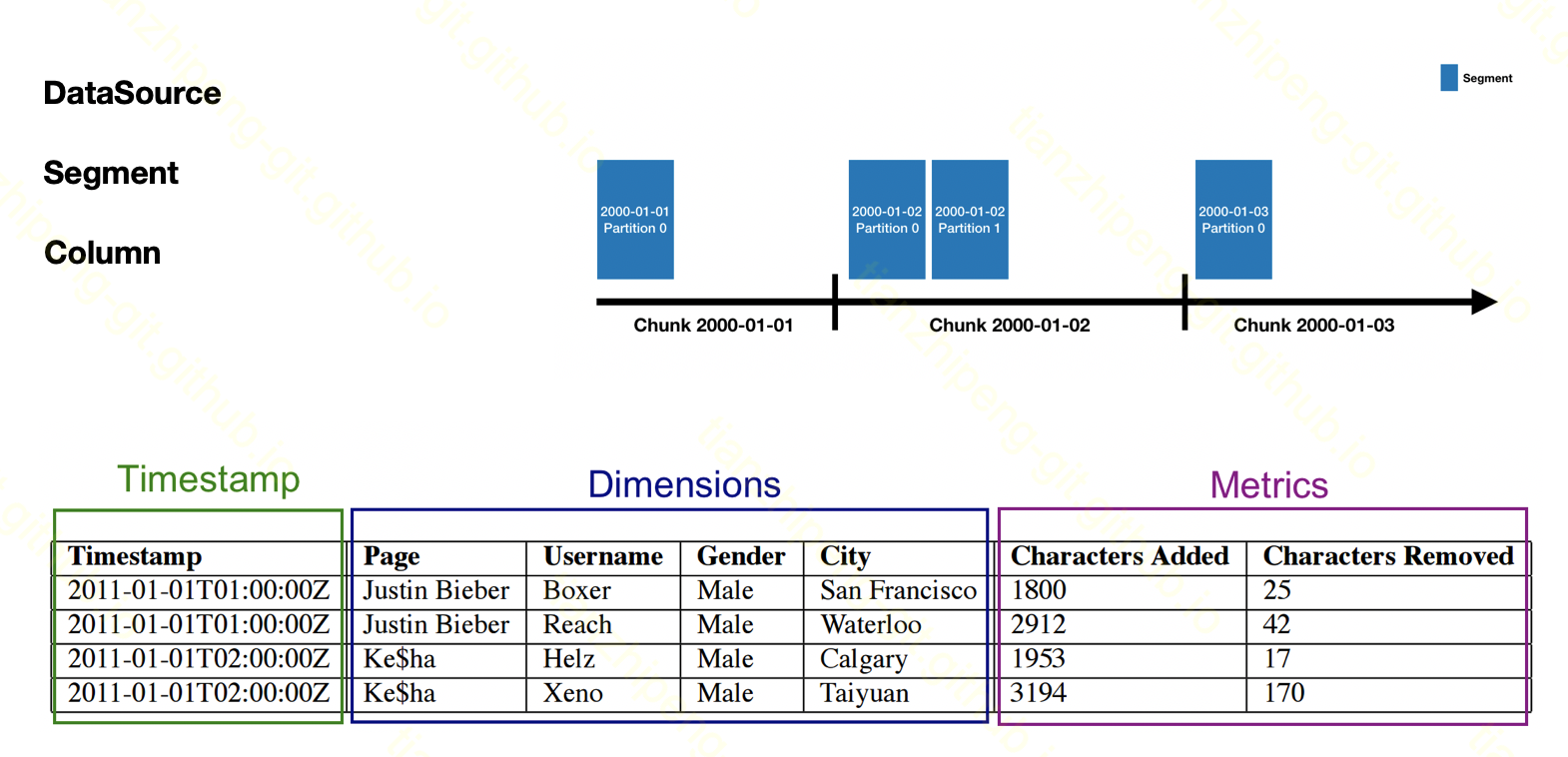
接着回忆一下druid的数据形式:
- 所有数据是分DataSource存储,
- DataSource根据时间划分为segment,
- 而到具体的数据, 分行分列, 和关系数据表很像, 但是列被分为三种, 时间列(必须),维度列(必须),指标列(可选)
Druid源码目录结构

如图是druid源码的最外层目录结构, 我把其中关键的模块标记了出来. 其他无关的除非有需要, 否则也不用关注.
这里说一下拿到这个源码我首先做的一些事吧:
- 大型Java项目基本采用Maven子模块的组织形式
- Idea作为一个项目整体打开
- Idea各个子模块单独打开
- 有些依赖(尤其是SNAPSHOT版本) 不在Maven中央仓库, 需要添加其他三方仓库
- 将无关依赖从Idea中移除, 有助于编译通过
- 参考druid发行版中的启动脚本, 为Idea本地调试搭建环境, 配置Idea的run参数
- Druid分节点的好处, 可以用打好的包跑其他节点, 只用Idea跑我关心的historical节点
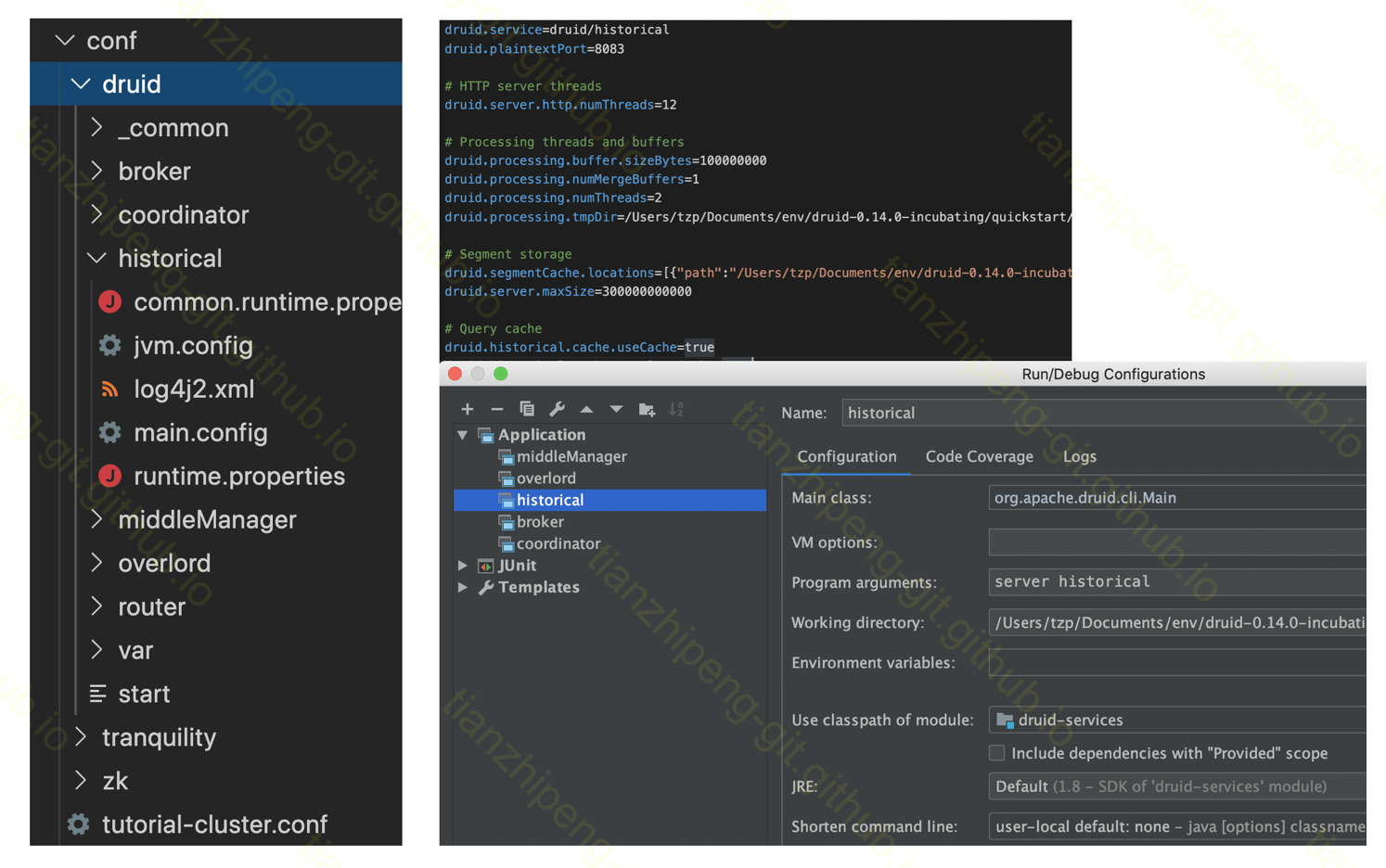
然后终于能编译通过run起来了, 图中是需要修改的配置和idea的run配置
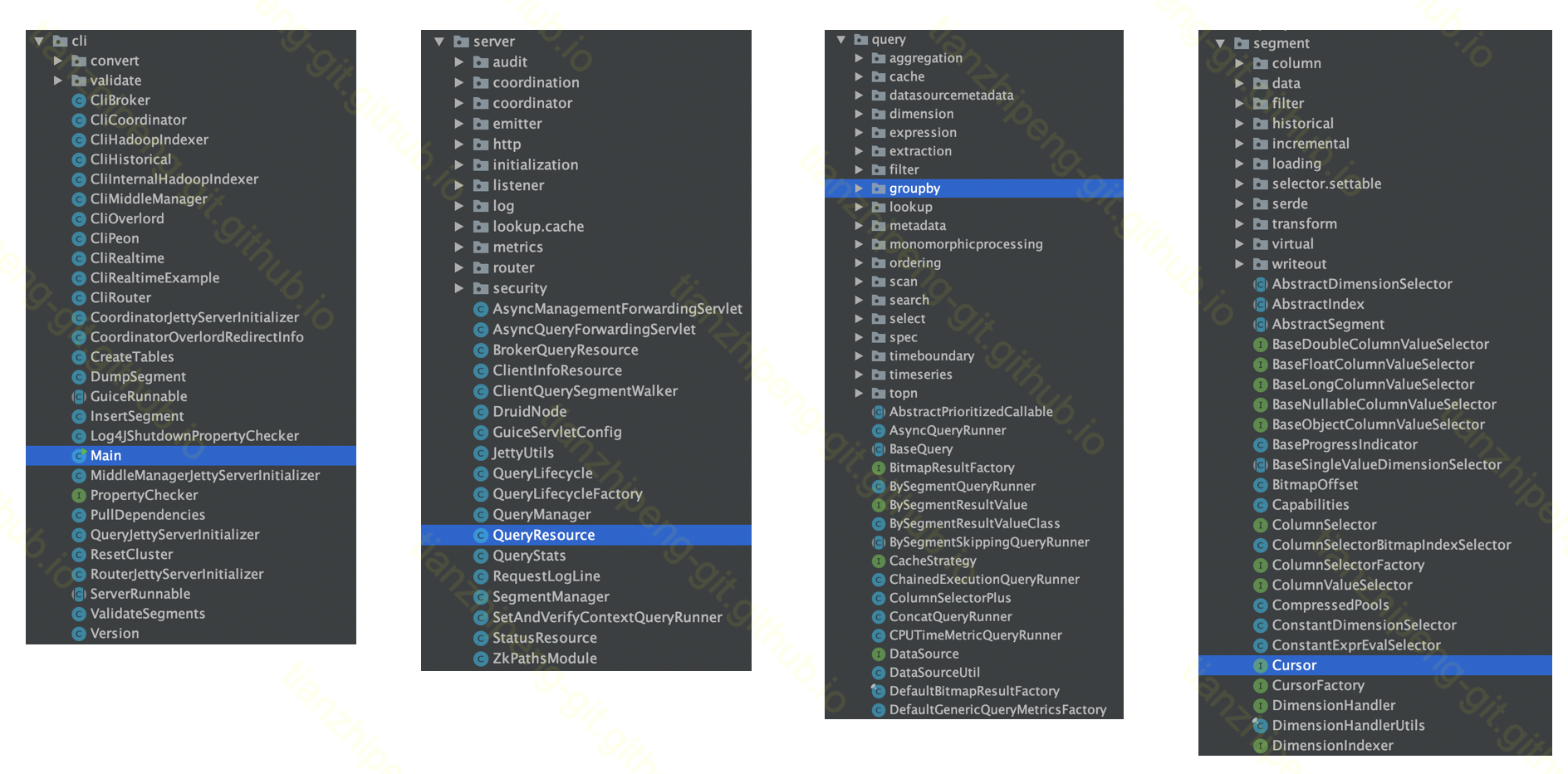
图中是一些重要的package, 从左到右分别是:
- cli: 各种节点的启动相关的类.
- server: 各个节点的功能的相关类.
- query: 各种查询语句的逻辑的相关类.
- segment: segment, column等的数据, 序列化, IO等的相关类.
不过这里可以看出, 刚才提到的broker,historical等等节点, 代码基本上是混在一起的, 并不是按节点分package, 这个给我们看代码造成了一定障碍.
#1 5个Druid源码细节
光从外面看结构还是不知道Druid是什么样的, 这一Part我挑了5个具体的技术点来看.
(其实这几个点, 是我看源码的过程中发现, 和我们日常项目中的情况不一样, 所以我自己看的时候就是障碍, 就在这里讲一下)
使用Jersey构建HTTP接口
首先我刚才提到了, 整个Druid无论查询还是管理, 都是通过http接口对外提供服务的, 作为一个写过web的选手, 我第一想法肯定是从请求发给Druid开始入手.
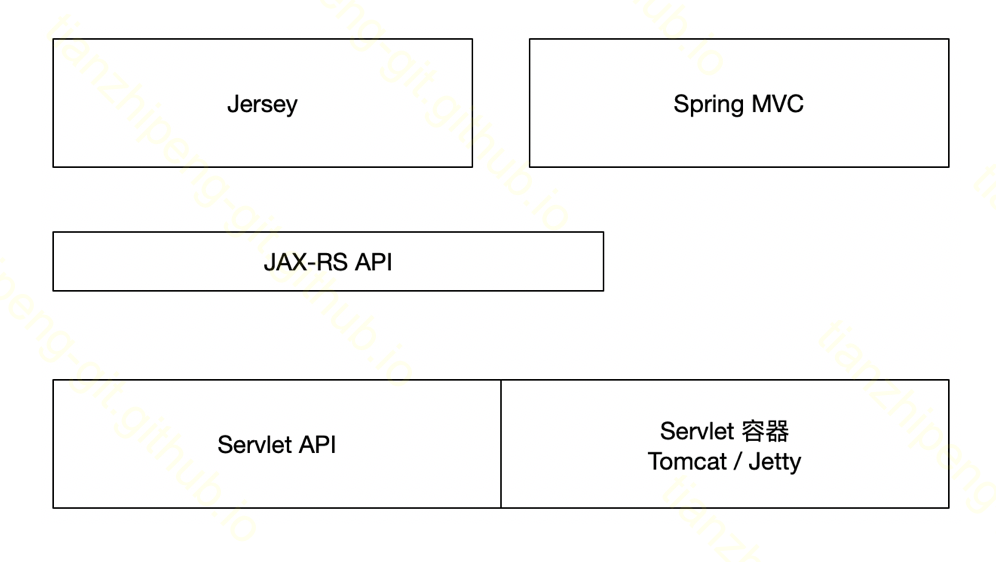
Druid肯定不是用的SpringMVC这类的大型框架来做的, 但是在java里做web基本都是基于servlet的, 如图最下层就是servlet包, 定义了一套接口, 像Tomcat和Jetty是Servlet容器, 是真的实现逻辑. 而向上有一个我们不常用的接口层, 叫jax rs, java api for restful web servcies, 就是在servlet基础上, 定义了一套RESTFUL服务的api
而完整实现了jax-rs的框架, 就是druid中使用的jersey, 我们常用的SpringMVC也部分实习了jax rs. 我们可以理解为Jersey是一个轻量级的SpringMVC的类似的项目.
@LazySingleton
@Path("/druid/v2/")
public class QueryResource implements QueryCountStatsProvider {``
...
@Inject
public QueryResource(...) {...}
@POST
@Produces({MediaType.APPLICATION_JSON, SmileMediaTypes.APPLICATION_JACKSON_SMILE})
@Consumes({MediaType.APPLICATION_JSON, SmileMediaTypes.APPLICATION_JACKSON_SMILE, APPLICATION_SMILE})
public Response doPost(
final InputStream in,
@QueryParam("pretty") final String pretty,
@Context final HttpServletRequest req // used to get request content-type,Accept header, remote address and auth-related headers
) throws IOException {
final QueryLifecycle queryLifecycle = queryLifecycleFactory.factorize();
Query<?> query = null;
String acceptHeader = req.getHeader("Accept");
if (Strings.isNullOrEmpty(acceptHeader)) {
//default to content-type
acceptHeader = req.getContentType();
}
...
Response.ResponseBuilder builder = Response
.ok(
...
)
.header("X-Druid-Query-Id", queryId);
return builder
.header("X-Druid-Response-Context", responseCtxString)
.build();
...
}
}这就是一个Jersey的HTTP请求接收的类, 可以看出, 和我们基于Spring的web接口大同小异, 里面管这个叫Resource, 只要找XXResource作为HTTP请求的入口即可. Jersey项目比较小而轻量.
使用Guice管理依赖注入

依赖注入是干什么的大家应该都知道, Guice(发音同juice)是谷歌开源的一个依赖注入框架, 图是guice介绍视频里的, 觉得有点意思.
Guice这个依赖注入框架也是很简单轻量, 只需要弄懂4个概念就行.
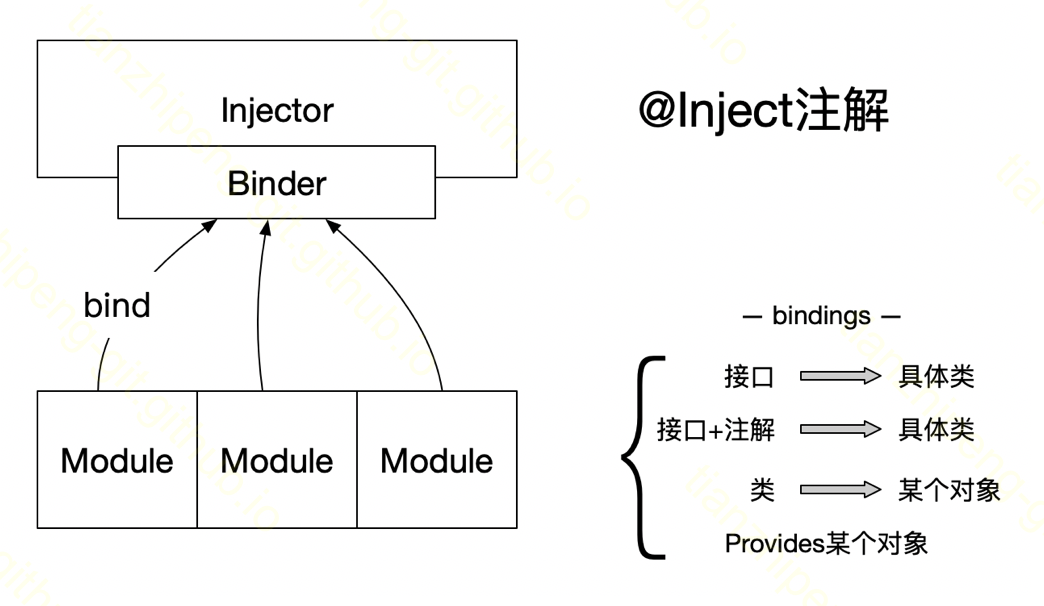
-
我们知道依赖注入这个事就是管理一堆类和对象. 在guice中,
Injector这个类就是guice管理对象的大管家, 使用guice都要获取一个injector, 它和Spring里面的ApplicationContext很像 -
@Inject注解, 是需要我们注在自己的类的需要依赖的地方, 是为了告诉Guice这个东西需要你给我注入进来. 类似Spring的@Autowired -
接下来还有个问题, 就是你说你需要一个什么对象, Guice如何知道我给你注入哪个对象呢? 如果你需要的这个东西没有歧义还好, 如果有歧义呢; 如果你需要自定义一个需要注入的对象呢? 这些都是由
bindings指定的. -
最后一个概念,
Module是一个只有一个方法的接口, 是用户配置bindings的地方.
了解这4个概念后, guice使用起来就比较简单了, 直接看代码.
//两个没啥特别的类, 注意Zoo中使用了@Inject注解
public class ZooManager {
public ZooManager() {
System.out.println("creating a new zoo manager");
}
}
public class Zoo {
@Inject
ZooManager manager;
public void haha() {
System.out.println("haha");
}
}
//最简单用法展示
public static void main(String[] args) {
Injector injector = Guice.createInjector();
Zoo zoo = injector.getInstance(Zoo.class);
zoo.haha();
}
//带Module的用法展示
public static void main(String[] args) {
Injector injector = Guice.createInjector(
new Module() {
@Override
public void configure(Binder binder) {
ZooManager myManager = new ZooManager();
binder.bind(ZooManager.class).toInstance(myManager);
binder.bind(SomeInterface.class).to(SomeImpl.class);
binder.bind(String.class).annotatedWith(Names.named("managerName")).toInstance("Jack");
}
}
);
Zoo zoo = injector.getInstance(Zoo.class);
zoo.haha();
}使用Jackson管理JSON解析
Jackson是一个json框架, 再次安利一下, 功能丰富, 质量有保障, 各种你用过没用过的功能特别多. 只说一点, 某fastjson有很多东西都是从这个库借鉴的.
这里我提一个在druid里用到的非常关键的功能, 动态子类对象解析功能
我们知道给一个字符串, json库可以帮我们解析成一个对象. 这里这个功能吊在哪里呢, 可以动态的确定解析成哪个类的对象, 如下有个Animal接口, 有俩实现类, Cat和Dog, 各只有一个成员变量name.
@JsonTypeInfo(use = JsonTypeInfo.Id.NAME, property = "type")
@JsonSubTypes(value = {
@JsonSubTypes.Type(name = "cat", value = Cat.class),
@JsonSubTypes.Type(name = "dog", value = Dog.class)
})
public interface Animal {
String getName();
}
//------------- 1
Animal animal = new Dog().setName("Bluto");
System.out.println(jsonMapper.writerWithDefaultPrettyPrinter().writeValueAsString(animal));
//------------- 2
Animal animal1 = jsonMapper.readValue(s, Animal.class);
System.out.println(animal1.getClass());上面1处的animal对象序列化成json时是这样的:
在里面多加了一个type: dog. 重点是什么, 比如这个json字符串, 反序列化的时候, 只需要告诉Jackson, 你给我反序列化成Animal, Jackson会根据type自动给到你的是一个Dog对象!!
用过druid的同学可能会想到, druid的查询用的就是json, 他的查询有多种查询(Query接口有多个实现类如GroupByQuery, ScanQuery), 有多种过滤方式(Filter接口有多个实现类如LikeFilter, SelectorFilter), 等等, 都是用的Jackson的这个功能方便的处理的.
这里再提第二个Jackson的重要feature: Jackson module. (和前文guice的module无关)
module是让用户对jackson进行扩展的配置点:
- 序列化器, mapkey序列化器
- 反序列化器, ..
- 序列化修改器
- 混入注解
- 注册子类
最后一条和刚才提到的动态子类结合起来的效果就是, 一开始我编码Animal的时候只有俩实现类, 但是支持动态的添加:
SimpleModule myModule = new SimpleModule("myTestModule");
myModule.registerSubtypes(new NamedType(Pig.class, "pig"));
//myModule.addSerializer(ser);
//myModule.addDeserializer(der);
ObjectMapper jsonMapper = new ObjectMapper();
jsonMapper.registerModule(myModule);
System.out.println(jsonMapper.writeValueAsString(new Pig()));模块化/插件化设计
其实说完上面的三个技术点, 我们就能很好的理解druid的插件化设计是怎么实现的了, 我觉得有这样几点吧:
- Jersey的Resource机制
- Guice的module机制
- Jackson的module机制
- Java Service Provide机制
- Java类加载和隔离机制
一个MySql作为MetaStore的扩展就像这样:
public class MySQLMetadataStorageModule extends SQLMetadataStorageDruidModule implements DruidModule
{
public static final String TYPE = "mysql";
public MySQLMetadataStorageModule()
{
super(TYPE);
}
@Override
public List<? extends Module> getJacksonModules()
{
return Collections.singletonList(
new SimpleModule()
.registerSubtypes(
new NamedType(MySQLFirehoseDatabaseConnector.class, "mysql")
)
);
}
@Override
public void configure(Binder binder)
{
super.configure(binder);
JsonConfigProvider.bind(binder, "druid.metadata.mysql.ssl", MySQLConnectorConfig.class);
PolyBind
.optionBinder(binder, Key.get(MetadataStorageProvider.class))
.addBinding(TYPE)
.to(NoopMetadataStorageProvider.class)
.in(LazySingleton.class);
...
}
}函数式 + continuation代码风格
函数式编程虽然没怎么用过, 但也知道意思. 有一种函数式风格的写法: continuation, cps, 之前没有用过, druid查询里用到了, 看起来很费劲, 我借用一个知乎回答解释一下cps吧:

他提到了cps风格的多种好处, 我只理解了其中的惰性求值, 假定这样一代码流程:

最左侧一列是我们需要的处理流程. 中间一列是我们一般情况下的代码写法, 先把所有数据读进来放到内存里, 比如一个list结构中, 然后一遍遍的遍历和处理最后写出. 这里的问题在于, 如果数据量特别大, 这种方式就特别消耗内存.
而如果用了cps风格, 像最右一列的写法, 我第一部的时候并没有把数据读进来, 只是返回一个空的seq, 并包进去了读取/生成元素的函数, 接下来的每层处理, 也没有真的拿到元素去遍历和执行, 只是有将处理逻辑作为函数由一次次的用闭包之类的函数式写法带入进去, 直到最终我们要向流里写出输出时, 这时才需要从最开始的源头读入seq的第一个元素, 然后调用各层的function, 然后写出, 然后再读下一个元素, 如此循环. 可以看出, 整个过程中内存中只需要保留一个元素, 消耗非常小.
这也就是所说的惰性求值, 表面上返回值了, 其实还没有真的执行, 非常的懒, 直到最后不得不用了时才开始计算.
#2 groupBy查询执行过程
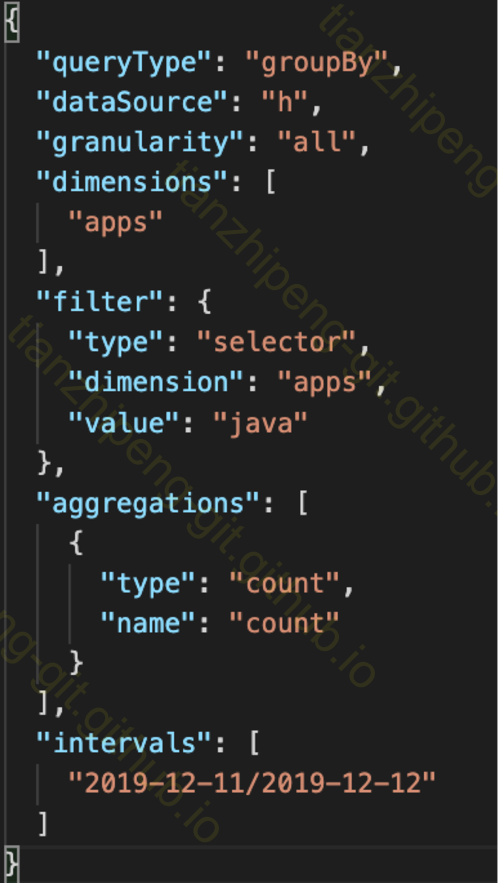
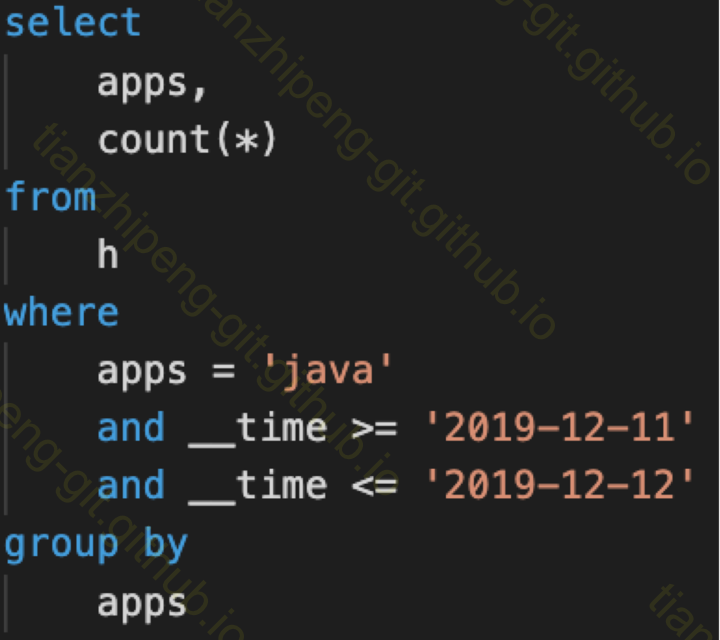
全文啰嗦半天, 到这里才是查询执行过程, 然而尴尬的是, 真讲执行过程, 全是源码, 在idea里面的断点, 一步步在哪个类做了什么, 很难在文章里些出来, 这里只能简略说一下.
查询相关的关键类
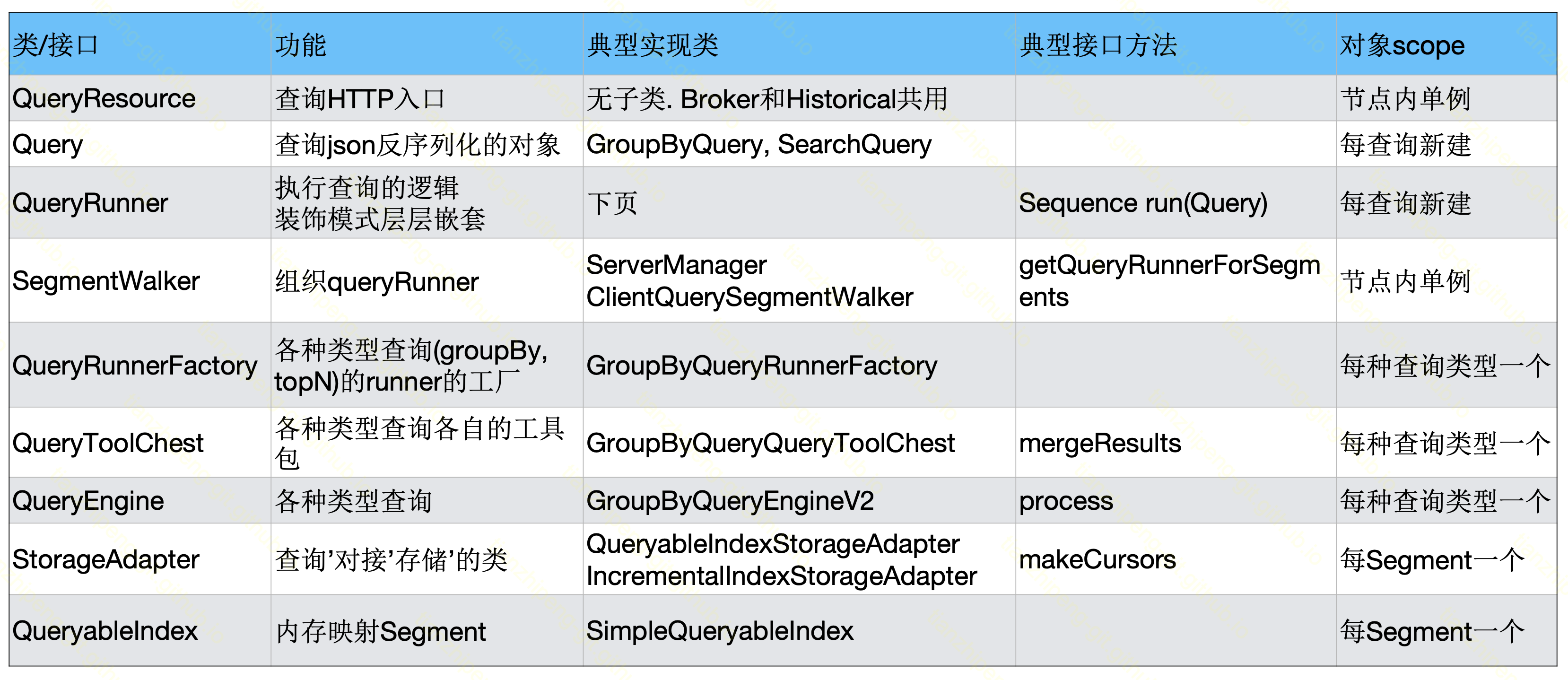
这里列了一下我觉得重要的类, 简单说明了功能, 实现类, 重要的接口方法, 和该类对象的生命周期和作用域.
QueryResource和Query对象的功能也很好理解, 在刚才的5个Druid源码细节一part都有提到.
QueryRunner是各种真实的逻辑, 有各种超多的runner, 见下面的图. SegmentWalker是组织queryRunner的. 比如查询刚来的时候,broker和historical是一样的,但其实之后的逻辑不一样就是在这里变化的. 这两个主要是和查询类型无关的, 和节点类型(Historical还是Broker)有关的逻辑.
QueryRunnerFactory, QueryToolChest, QueryEngine这三个, 是和具体某种查询类型有关的, 从他们的子类也可以看出.
最后StorageAdapter和QueryableIndex是和存储, 和Segment有关的逻辑.
各种runner:

查询时Broker的逻辑
前面提到过, broker的功能是将查询转发给真正持有数据的Historical或者middleManager, 所以本身的逻辑较为简单.

查询时Historical的逻辑
Historical端逻辑比较长, 也是QueryResource接到请求, 接下来是ServerManager(segmentWalker的实现类)包装各种runner. 这里是通用的逻辑.
然后执行groupBy相关的逻辑, 主要在QueryRunnerFactory, QueryToolChest, QueryEngine类中.
然后是真实数据访问相关的逻辑, StorageAdapter + QueryableIndex
- 根据能否使用bitmap索引, 将filter分为pre-filter和post-filter
- 前者先使用bitmap过滤得到offset
- 后者每行进行判断是否满足filter
- 根据granularity时间粒度, 将interval分组进行查询
- 各个filter自己的逻辑由自己实现(见Filter接口, 用/不用bitmap)
- 各列的值都在queryableIndex里面的ColumnSupplier(列式存储 字典编码)
具体的执行逻辑都在代码里, 其中的几个重点类的重点位置, 我进行注释了, 在这里可以看到.
#3 如何阅读源码
一些个人想法
为什么要阅读源码
- 深入了解内部原理, 有助于解决实际的项目问题
- 读书破万卷, 下笔如有神
在哪阅读源码
- by case的阅读: “哪里不会点哪里”
- 完整框架/项目阅读: “Druid”
这里我就把读源码分为两种
 一种是遇到某个功能就看某个部分的源码, 叫哪里不会点哪里. 开发过程, 调试过程中, 遇到了什么问题, 随手就点开源码看一看. 希望右侧这个按钮大家都比较眼熟, 如果看着不眼熟回去面壁
一种是遇到某个功能就看某个部分的源码, 叫哪里不会点哪里. 开发过程, 调试过程中, 遇到了什么问题, 随手就点开源码看一看. 希望右侧这个按钮大家都比较眼熟, 如果看着不眼熟回去面壁
 第二种我叫完整框架 完整项目的阅读, 比如druid这种, 首先他不是作为一个库供我项目使用, 而是独立的框架运行, 我没法在自己项目中看到, 其次如果想对整个druid有了解, 还是要整体看一下, 所以就来到github, 复制地址, clone下来, 这次的场景就属于第二种.
第二种我叫完整框架 完整项目的阅读, 比如druid这种, 首先他不是作为一个库供我项目使用, 而是独立的框架运行, 我没法在自己项目中看到, 其次如果想对整个druid有了解, 还是要整体看一下, 所以就来到github, 复制地址, clone下来, 这次的场景就属于第二种.
Some tips
- 先整体, 再局部
- by模块读, by功能点/执行路径读
- 本地(Idea)把项目跑起来