Kong+Consul微服务API网关实践-2

Kong+Consul的API网关 part2. 续前文.
核心模块
日志报表
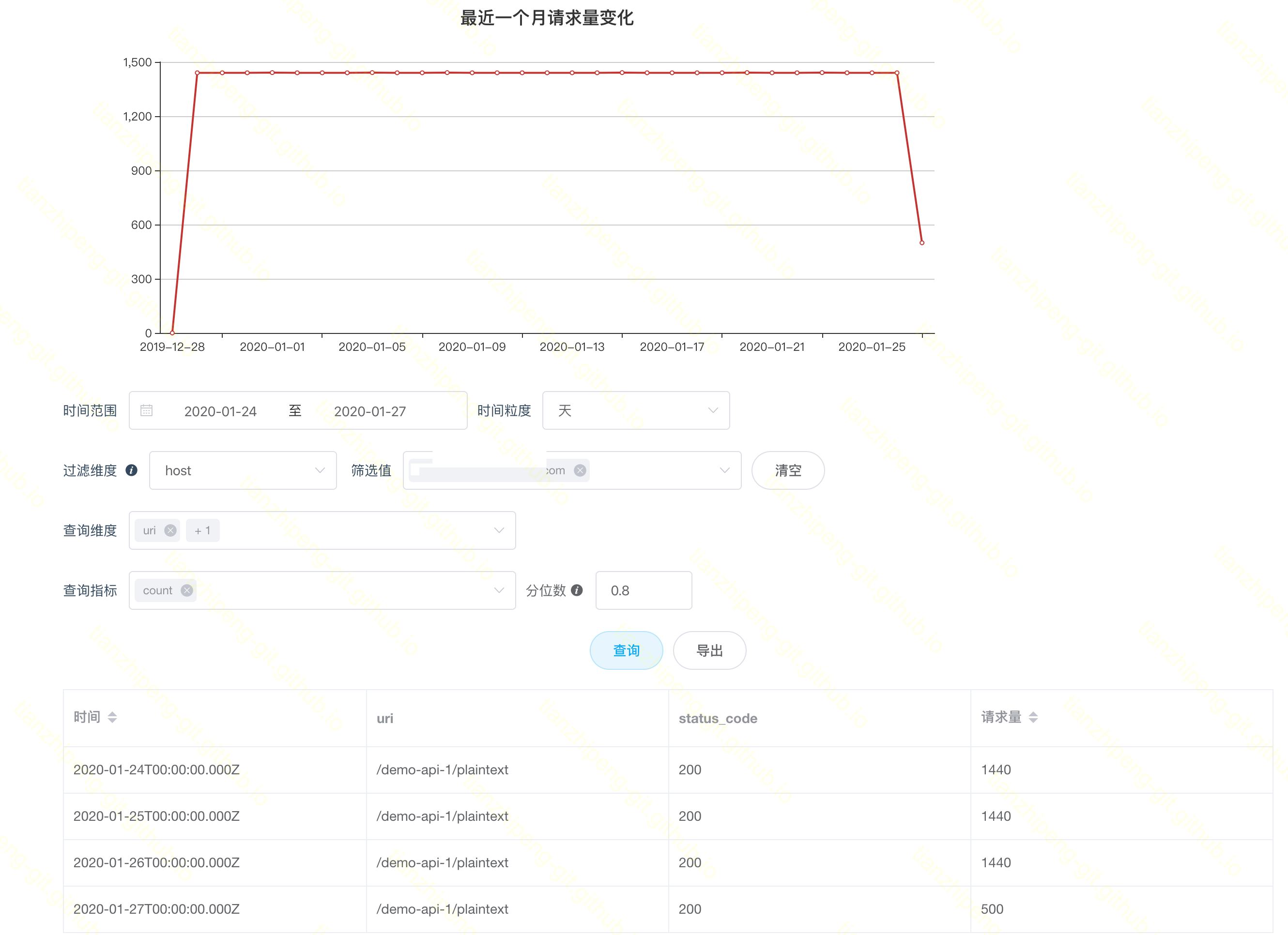
如图是Aster日志报表页面. 上面是一个月查询量变化, 下面是自定义查询表.
整体结构
监控和日志包括对这个系统本身的监控和日志和对所管理服务的监控和日志. 对本系统本身监控靠外部系统来实现, 对管理的服务的监控的Consul来做. 日志只做了网关转发的请求日志.
考虑日志收集搬运与查询处理, 会有很多开源项目可供选择:
- ELK技术栈. 其中有负责日志收集搬运的logstash, beats, 有负责日志查询的ES.
- Kafka. 相当成熟可靠的消息中间件, 大数据量下可靠性有保障, 且我司有专门的集群.
- Flume.
- Fluentd.
- syslog(rsyslog). 大多数Linux发行版都预装的一个服务(像我们用的CentOS预装了rsyslog, 是syslog的进阶版). 其功能是在服务器开启一个标准的日志中转进程, 其他进程可以将日志丢到syslog这, 它配置了将日志怎么处理. 像systemd管理器, nginx等等, 都可以将日志发到syslog中. 然后syslog又可以讲日志写入到文件, 写入到Kafka等.
- Druid. 阿帕奇基金下的数据聚合分析的MMP项目, 我司有专门的集群.
基于以上调研, 设计了一个符合我们场景的日志收集搬运方案.
+-------+
|request|
+---+---+
| +-------+
| +----------------+ aster +----------------+
| | +-------+ |
v v v
+---+-----------------+ +-------+ +---+---+
| kong |----> rsyslog |----->+ kafka +----->+---->+ druid |
+---+-----------------+ +-------+ | +-------+
| |
| | +---------------+
| +---->+ elasticsearch |
v +---------------+
+---+----+
|upstream|
+--------+- 首先所有kong节点机器上默认都是有的rsyslog的, 需要用yum安装omkafka, 用于写Kafka.
- Kafka是我司有专门的集群, 只需要申请一个队列即可.
- Druid上启动一个实时消费Kafka的任务. 到Druid中的日志会挑选一些重要的字段, 然后聚合, 用于报表查询的需求. 由于格式特殊, 我写了一个自定义的parser(后面介绍).
- 启动一个Kafka到ES的消费, 用于具体日志的查询, 由于需求不明显, 这块没有开发.
整体看我所有的选型思路都是, 开发量小, 运维量小, 哈哈
Kong的配置
kong的日志分为两块:
- syslog插件打印的请求日志
- errorlog记录的失败请求和插件日志
前者是syslog插件的功能, 生成的日志要通过Kafka导入Druid和ES. 后者比较简单, 打算是通过Kafka导入ES用于调试的.
由于Nginx默认支持errorlog写入syslog, 所以后者只需要配置proxy_error_log = syslog:server=unix:/dev/log,facility=user,tag=kong_error,nohostname即可.
前者需要安装一个kong的插件, 在kong的插件列表页面可以找到. 这个插件将请求和响应的信息转为json格式发送给syslog. 日志长这个样:
rsyslog的配置
rsyslog的配置就是根据$programname == “kong”, 将日志转到kafka和文件中, 不再赘述.
module(load="omkafka")
template (name="onlyMsg" type="string" string="%msg%\n")
if ( $programname == "kong" ) then {
action(type="omfile" file="/data/log/kong/rsyslog-kong.log")
action(type="omkafka"
topic="aster-kong-log"
broker=["10.10.100.192:9092"]
template="onlyMsg"
errorFile="/data/log/kong/rsyslog-kong-kafka-error.log"
)
stop
}
if ( $programname == "kong_error" ) then {
action(type="omfile" file="/data/log/kong/rsyslog-kong-error.log")
stop
}Druid自定义parser和配置
Druid新版是有消费Kafka的实时数据摄入功能的, 只需要配置一个这样的任务即可.
Druid数据是分维度和指标的, 对于我们这种请求日志, 可以看到配置中metricsSpec定义了指标: 请求量(count), 请求大小(request_size), 响应大小(response_size), 请求时间/延迟(request_latency), kong处理延迟(kong_latency).
而维度有些特殊, 默认定义的维度有: 请求服务名(service), 请求域名(host), uri, 响应状态码, 请求方法, 后端服务ip端口等, 除了这些固定的维度, Aster还支持将3个用户自定义的参数作为报表维度, 如下图的配置.
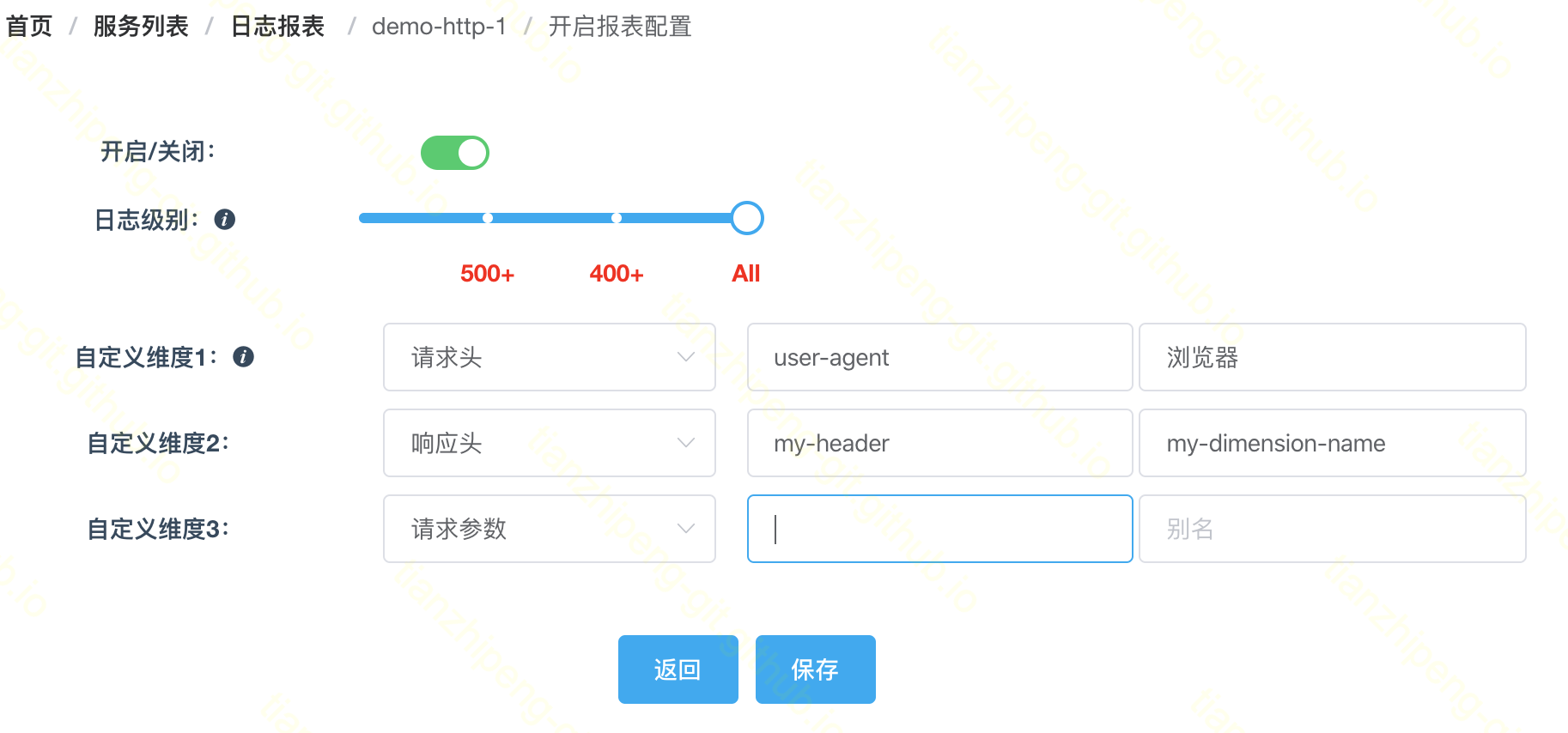
也就是说, 用户在页面上定义将请求头/响应头/请求参数中的某一个作为自定义维度, 就会对应到Druid配置中的custom1/custom2/custom3三个维度上. 其他解析都是Druid默认支持的, 这个自定义维度功能需要我们开发一个Druid扩展.
自定义Druid扩展需要弄一个这样的类作为扩展和Druid的连接点:
public class DynamicJsonParseModule implements DruidModule {
@Override
public List<? extends Module> getJacksonModules() {
return Collections.singletonList(
new SimpleModule("DynamicJsonParseModule")
.registerSubtypes(
new NamedType(DynamicJsonParseSpec.class, "dynamic-json")
)
);
}
@Override
public void configure(Binder binder) {
}
}然后再实现自己的逻辑, 我这里是实现了一个parser, 就是在Druid解析一条数据时执行的. 具体逻辑就是定时从Aster获取三个动态维度的配置, 然后json解析数据而已.
整合管理系统
.
├── BUGREPORT.MD
├── CHANGELOG.MD
├── CONTRIBUTING.MD
├── README.MD
├── ROADMAP.MD
├── aster-config
├── aster-core
├── aster-kong
├── aster-reports
│ ├── README.MD
│ ├── aster-report-query-druid
│ ├── druid-dynamic-json-parser
│ └── kong-rsyslog-kafka.conf
├── aster-sd-consul
├── aster-server
├── aster-ui
├── docs
├── opts
│ ├── OPTS.MD
│ ├── ansible
│ └── deploy.md
├── pom.xml
└── target管理系统就是一个基于Spring搭建的后端应用, 开发时尽可能的按照标准和规范来做, 模仿开源项目的亚子(实际执行的时候也给弄得很乱…).
文档尽量齐全
- README 说明文档, 各个子模块又分别有自己的README.
- CONTRIBUTING 开发人员贡献文档, 开发规范等.
- CHANGELOG 版本更新和功能变化文档.
- BUGREPORT BUG记录
- ROADMAP 路线规划
- OPTS 部署和运维文档
部署安装
由于模块较多, 部署安装本来想的是打包成rpm之类的, 由于时间原因没弄, 最后写了些ansible的脚本.
模块拆分
项目代码本身, 做了模块化拆分, 用了maven子模块功能, 整体目录结构就是上面那个.
- 父级是一个packaging为pom类型的maven项目, 收纳下属所有modules.
- 核心公共代码作为core模块, 被大多数其他模块引用.
- aster-server里面代码很少, 是Spring Boot应用启动的入口, 引用其他所有模块.
- aster-consul, aster-kong等是各个功能模块.
前后端分离
项目也采用前后端分离的方式, 前端aster-ui用Vue开发. 为了使整体统一一致, aster-ui也是一个maven项目, 也会被maven打成jar包, 然后被server模块引用, 以达到前后端分别开发, 统一打包部署的目的. 是通过一个maven前端打包的插件实现的:
<build>
<resources>
<resource>
<directory>target/dist</directory>
<includes>
<include>static/</include>
<include>index.html</include>
<include>favicon.ico</include>
</includes>
<targetPath>public</targetPath>
</resource>
</resources>
<plugins>
<plugin>
<groupId>com.github.eirslett</groupId>
<artifactId>frontend-maven-plugin</artifactId>
<version>${frontend-maven-plugin.version}</version>
<executions>
<!-- Install our node and npm version to run npm/node scripts-->
<execution>
<id>install node and npm</id>
<goals>
<goal>install-node-and-npm</goal>
</goals>
<configuration>
<nodeVersion>v10.10.0</nodeVersion>
</configuration>
</execution>
<!-- Install all project dependencies -->
<execution>
<id>npm install</id>
<goals>
<goal>npm</goal>
</goals>
<!-- optional: default phase is "generate-resources" -->
<phase>generate-resources</phase>
<!-- Optional configuration which provides for running any npm command -->
<configuration>
<arguments>install</arguments>
</configuration>
</execution>
<!-- Build and minify static files -->
<execution>
<id>npm run build</id>
<goals>
<goal>npm</goal>
</goals>
<configuration>
<arguments>run build</arguments>
</configuration>
</execution>
</executions>
<configuration>
<downloadRoot>https://mirrors.tuna.tsinghua.edu.cn/nodejs-release/</downloadRoot>
</configuration>
</plugin>
</plugins>
</build>所以实际上还是用前端的npm将vue编译打包成静态html+css+js文件, 然后maven将这个文件打包到jar文件public目录下, 然后利用Spring默认的ViewResolver会将public目录下的文件默认响应HTTP资源请求, 效果达成.
其他功能
配置管理
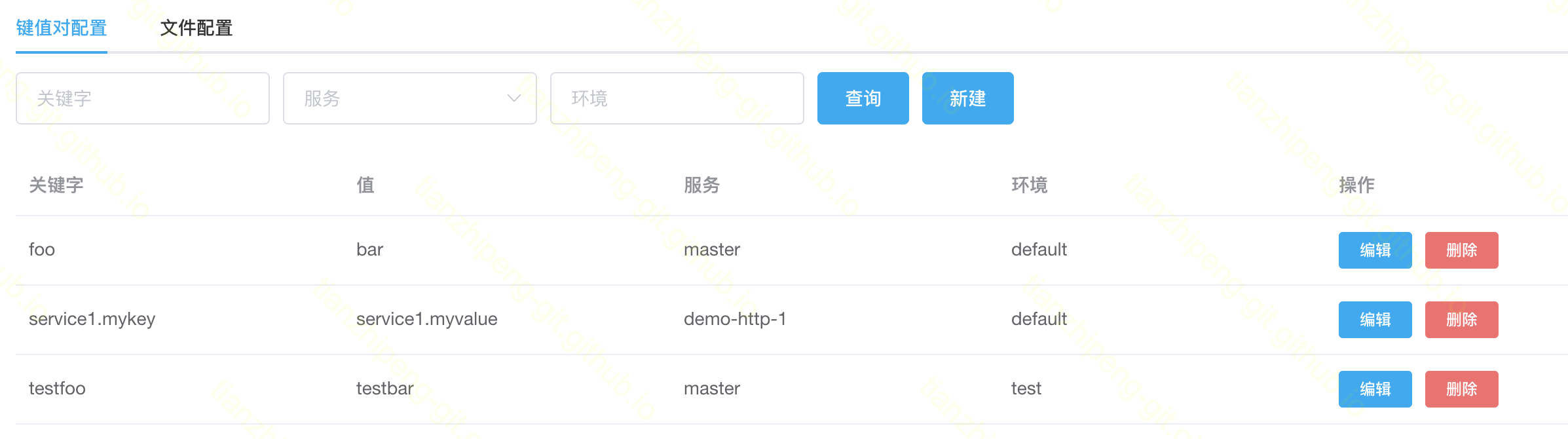
配置管理功能是基于Spring Cloud Config包装的集中式配置管理Server, 在原项目基础上, 增加了使用JDBC方式存储配置的功能以及一些方便使用的HTTP接口.
配置分为kv和文件两种格式, 支持加密, 支持占位符替换.
可以使用SpringCloud的sdk或者普通http的方式使用, 可以获取单个配置项, 可以用yaml/json等格式批量获取配置.
配置由project, service, profile, key(fileName)这四项来唯一确定一个配置.
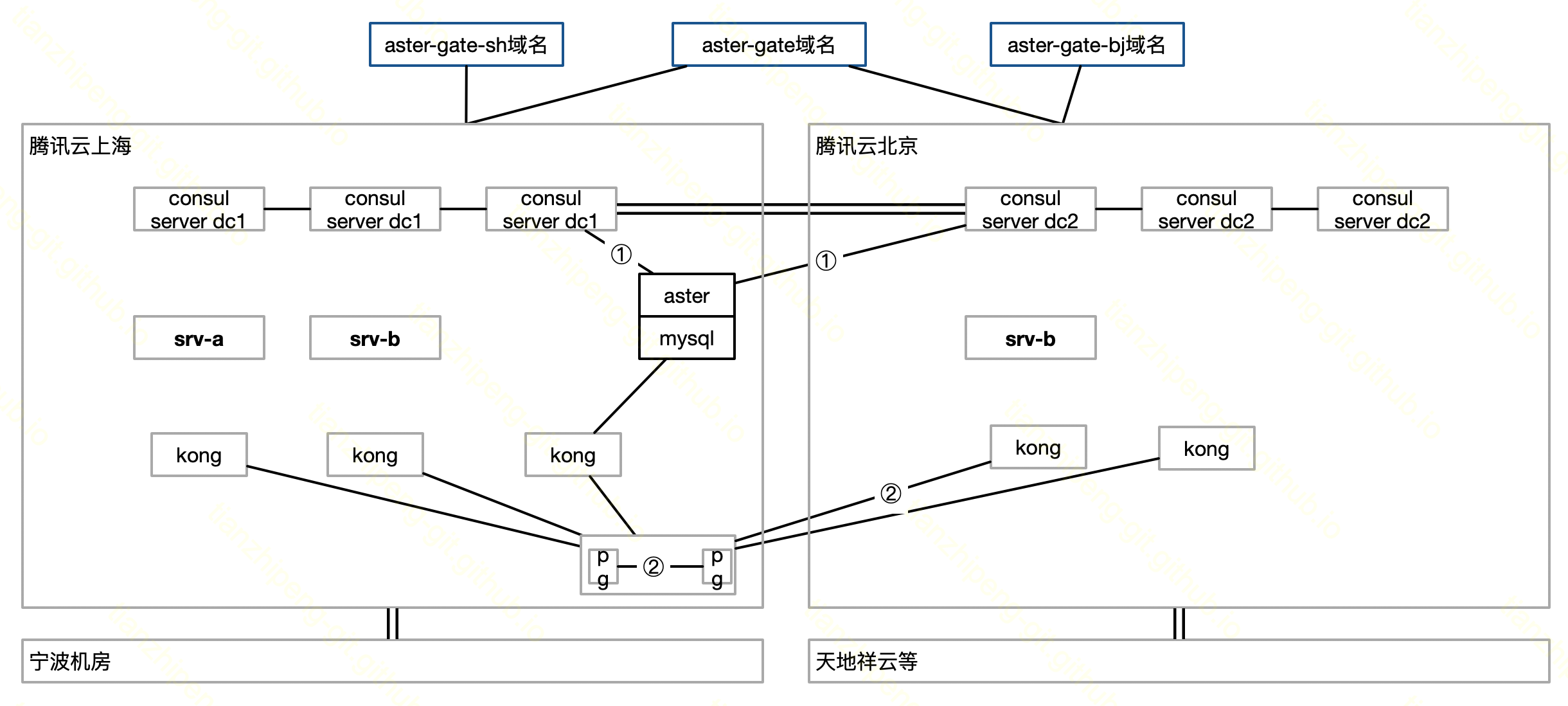
多可用区
参考和总结
其实这个项目如果投入更多精力做, 应该是不错的, 功能上和设计上我觉得是我目前的水平能做到的比较好的了. 不过一是我团队有其他更重要的业务KPI要完成, 这种为程序员服务的内部项目自然没法投入太多精力, 二是另一个团队基于K8S相关生态做了类似的一套东西, 虽然现在和这个系统功能上重叠不大, 不过从大趋势来讲, 可能云原生是正道. 所以这个项目最终要下线的.
参考资料为各开源项目文档.