[译]开源大数据OLAP系统对比: ClickHouse Druid Pinot

原文: Comparison of the Open Source OLAP Systems for Big Data: ClickHouse, Druid, and Pinot
preface
- 原文发布时间
Feb 1, 2018 - 文章很长, 可以直接读”总结”部分.
- 全文中”我”是指原作者. (译者: 为我的磨叨).
- 文中的很多外链都是关于三个系统的很好的学习资源.
- 作者提到的”黑盒对比”概念很有意思, 是一种很常见的误区.
信息来源
我是从ClickHouse的核心开发者之一的Alexey Zatelepin那里了解了ClickHouse的实现细节, 这个文档的后4章节是能找到的关于ClickHouse最好的英文资料了, 然而仍旧很少.
我本身是Druid的committer, 但是和这个项目并不是利益相关(实际上我可能马上要停止参与其开发过程了), 因此读者可以相信我对于Druid的说法是公正的.
本文中关于Pinot的内容都基于Pinot wiki上的架构说明和另一篇wiki页面的“Design Docs”章节.
这篇文章也经过了这几个项目的几个核心开发者的review, 十分感谢.
相似性
耦合数据和计算
这三个系统功能上十分相近, 因为他们都采用 在同一个节点进行存储和查询 的设计方案, 与Google BigQuery的解耦式架构不同. 最近我也描述了关于耦合架构的Druid中的一些问题, 目前还没有和BigQuery类似的开源项目(Drill可能是), 我在另一篇文章中探讨了如何设计这样的系统.
和大数据SQL系统的不同: 索引和静态数据分发
这些系统执行查询的速度要比SQL-on-Hadoop系的大数据系统要快, 如Hive, Impala, Presto, Spark等, 即使后者将数据存储在Parquet之类的列式存储格式中. 这主要因为:
- 这三个系统都有自己内部的数据格式, data和index紧密的和查询执行引擎相关, 而SQL-on-Hadoop的系统一般都是通用化设计, 对数据格式是不可知论(agnostic)的, 对数据存储后端是更少侵入的.(译者: 前者的定制化格式服务于自己的定制化查询需求, SQL-on-Hadoop的通用带来低效. 而且SQL-on-Hadoop不能讲自己的功能侵入到HDFS之类的里面)
- 这三个系统的数据都是相对静态的分发在集群的节点上, 分布式查询执行能够有效利用这个优势. 另一方面, 这三个系统不支持需要在节点间移动大量数据的查询, 例如两个大表join. (译者: 像Druid查询时会将查询根据Segment信息分拆给各个Historical执行, 结果再聚合) (译者: join这种操作在SQL-on-Hadoop是基本操作, 在这三个系统是基本不可实现的)
不可修改和删除
从数据库系统的另一方面看, 这三个系统都不支持对单个数据进行修改和删除(译者: 整个表做版本替换不算修改删除), 而相对的列式存储系统Kudu, InfluxDB等都支持这种操作. 这个特性使得Druid等系统能够设计更高效的压缩方案, 更激进的索引方案, 也就意味着资源效率高, 查询执行快.
ClickHouse开发者计划在未来支持修改和删除, 还不太确定.
大数据风格的数据摄入
这三个系统都支持从Kafka进行流式数据摄入. Druid和Pinot支持Lambda风格的流式和批量数据摄入. ClickHouse支持直接批量插入, 因此不像Druid那样需要一个额外的批处理摄入系统. 下面的章节会讨论更多细节.
大规模系统得到验证
这三个系统在大规模集群上都有实证, Yandex的ClickHouse集群大概有数万CPU cores, Metamarkets运行了一个相似规模的Druid集群, LinkedIn的一个Pinot集群有数千台机器.
不成熟
这三个系统对比商业数据库标准来讲, 都是不成熟的. 都缺少一些明显的优化, 缺少一些典型的功能, 还有很多bugs. 这引出了下面的章节:
性能比较和选择
我经常在网络上看到很多人是如何比较和选择大数据系统的: 从自己的数据中抽取一部分, 导入到对应的系统, 然后尝试衡量一些系统性能, 比如占用的磁盘和内存量, 查询执行速度等等, 这个过程中他们对这个系统内部几乎完全不了解. 然后他们使用这些性能信息和他们需要的功能列表来比较现有系统, 选择一个他们认为”更好”的系统出来.
我认为这种做法是错误的, 至少对于开源大数据OLAP系统来讲是这样是不行的. 问题在于, 打造一个通用的/在所有主要使用场景和功能上都ok的大数据OLAP是一个超巨大的工程, 我估计要100人年能做出来. 而ClickHouse, Druid和Pinot目前都是针对特定使用场景进行设计和优化的, 几乎只关注他们的开发者需要的功能特征. 如果要部署一个这种系统的大集群, 我保证有一天你的使用场景会遇到这个系统的特有瓶颈, 是这个OLAP系统开发者原来没有遇到过或者根本不care的(译者: 这时候咋办?).
而前面提到的”把一小部分数据丢进去跑一跑”的技术选型方案, 有很大几率让你遇到这些系统的瓶颈, 其中很多通过简单的修改配置文件/数据schema或者查询逻辑, 都能解决(译者: 剩下解决不了的瓶颈, 就是系统本身设计就不支持的吧).
CloudFlare做的对比
一个典型的例子是在Cloudflare’s choice between ClickHouse and Druid这篇文章中, 他们用4台ClickHouse解决的事, 估计说要100台Druid节点. 虽然文章作者承认这种比较是不公平的, 因为Druid本身缺少”主键排序”功能.
但他没意识到在Druid中可以实现相同的效果, 只要在“ingestion spec”中设置正确的dimensions顺序, 简单改造一下数据: 截断__time列到更大粒度(如小时), 如果需要的话将精确时间增加到一个“precise_time”的列中. 这是一个hack, 但是确实能让Druid根据一些维度对数据进行排序.
我不是在挑战他们关于ClickHouse的技术选型结果, 其实在他们的场景下, 10个节点的规模, 我认为ClickHouse确实是比Druid更好的选择(下面的章节会讨论更多细节). 但是他们关于ClickHouse对比Druid有数个量级的性能优势的结论是很荒谬的. 事实上在这三个系统中, Druid提供了最低廉的安装成本方案, 在下面的”Druid查询节点分层”中有讨论.
考虑改造成本而不是当前最优
当选择大数据OLAP系统时, 不要对比他们目前对于你的使用场景哪个是最优的. 他们目前都不是最优的. 而要考虑你的组织有多快能够将这个系统改造为对于你的场景最优的方向. (译者: 不要看目前是不是最好的, 看你有没有魔改能力).
因为三个系统架构上的相似性, 导致他们也有相似的性能优化极限. 没有什么魔法药丸能让其中一个比别的性能显著的快. 不要被他们的说法欺骗了, 这些系统在不同的benchmark上有完全不同的性能表现, 例如Druid目前不支持主键排序, ClickHouse目前不支持倒排索引. 这些缺失的功能和优化能在相应系统中轻松实现, 如果你有意愿和能力的话:
- 要么你公司的工程师们, 能够阅读, 理解, 修改对应系统的源码. 要注意: ClickHouse使用C++编写, 其他两个是Java.
- 要么你公司采购了对应系统的商业版服务, 有售后那种, 比如Imply和Hortonworks的Druid等.
其他的开发上的考量:
- ClickHouse的开发者在Yandex, 有50%的时间在构建他们公司内部所需的功能feature, 其余时间开发社区投票的功能feature. 如果你需要的feature是社区大多数人需要的, 那就比较好了.
- 在Imply的Druid开发者主要开发的是广泛使用的feature, 最大化他们的商业利益.
- Druid开发过程是Apache风格的(译者: 已进入Apache基金会管理), 已经有好多年是由多个公司一起开发, 而不被其中任一掌控. 而ClickHouse和Pinot离这个过程还很远, 他们基本是由Yandex和LindedIn一手开发和掌握的. 为Druid贡献代码, 由于偏离主要开发者的计划目标而被拒绝的可能性是最小的, Druid没有主要开发公司.
- Druid承诺支持开发者API, 允许提供自定义的数据类型, 聚合算法, 存储系统等, Druid在主干代码之外维护这些contribution. Druid开发者在主版本中维护这些开发者API的文档和兼容性. 然而这些API也是很不成熟的, 非常容易在发新版的时候broken. ClickHouse和Pinot目前没有维护类似API.
- 根据GitHub, Pinot的开发投入最多, 去年至少有10人年的投入, ClickHouse大约是6, Druid大约是7. 这意味着Pinot理论上提高改进的最快.
Druid和Pinot架构上是最像的, ClickHouse稍有不同. 接下来首先对比ClickHouse和Druid/Pinot通用的架构上的不同, 然后再讨论Druid和Pinot具体的区别.
ClickHouse和Druid/Pinot的区别
数据管理 - Druid/Pinot
在Druid/Pinot中, 所有表(或者叫其他类似的术语)中的数据都会被分区(partitioned). 通过时间维度, 数据也会被分为特定的时间间隔(interval). 然后这些数据片会被独立封装成一个自组织的实体中, 叫做segments. 每个segment都包含了表的元信息, 压缩列数据, 索引.
Segments被持久化在”deep storage”中(例如HDFS等), 可以被查询处理节点加载, 但是后者不负责数据的持久性(durability), 所以查询处理节点可以相对自由的被替换. Segments和节点不是严格绑定的, 可以被任何节点加载. 有一个专用的节点(Druid中叫”Coordinator”, Pinot中叫”Controller”, 下面统一都叫”master”)负责给节点分配segments, 如果需要的话还可以在节点中移动segments. 这和我上面提到的数据在节点间静态分布并不矛盾, 因为这种加载和移动是非常昂贵的操作, 通常耗时几分钟几小时, 不是为一个特定查询进行的.
Druid中segments的元信息直接存储在Zookeeper中, Pinot则使用Helix框架. Druid元数据也使用了SQL数据库, 之后Druid和Pinot区别中会介绍.
数据管理 - ClickHouse
ClickHouse中没有Segment概念, 没有”deep storage”, 集群中的节点既要负责查询执行, 也要存储数据和负责数据持久性(persistence/durability). 因此不需要部署HDFS之类的.
ClickHouse也有可分区的表, 由特定节点组成. 集群中没有授权中心或者元信息server这样的角色(没有”master”), table被分区到的所有节点, 都有完整一致的表元信息, 包含了这个表的各个分区所在的其他节点的地址.(译者: ClickHouse中有很多类型table engine可选, MergeTree系列是其中最重要的一种, MergeTree表是可以分区的)
分区表元信息中包含了分发新数据到各个节点的权重, 例如 40%的数据应该写到A节点, 30%数据写到B, 30%写到C. 通常情况下权重都是相同的, 只有在加入新节点的时候才需要倾斜, 目的是用新数据更快填充新节点. 更新节点权重需要管理员手动进行.
数据管理 - 对比
ClickHouse中的数据管理比Druid/Pinot中更简单, 不需要”deep storage”, 只有一种类型的节点, 不需要特殊的数据管理server. 但这种方案存在一些问题, 当表数据增长到很大, 需要分区到几十个或更多节点时, 查询的膨胀因子变得和分区因子一样巨大(query amplification factor becomes as large as the partitioning factor), 即使一个查询只需要覆盖一小段时间内数据.
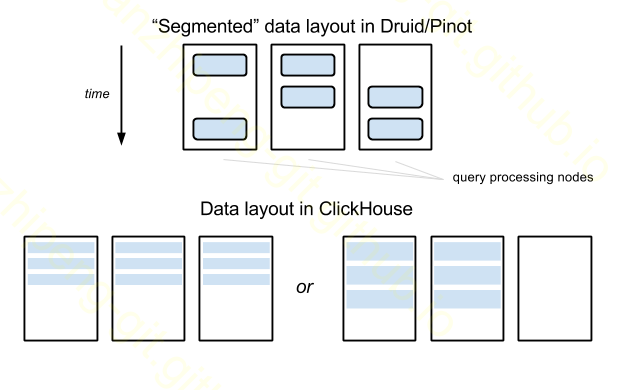
图中的例子, 表数据分布在Druid三个节点上, 但是一个查询可能只要一小个时间段的数据, 比如只hit到其中两个节点. 而ClickHouse中任何查询都需要这三台节点来执行. 这个例子可能还没有什么大的问题, 假设有100个节点呢, 在Druid中分区可能只用10个.
为缓和这个问题, Yandex的最大ClickHouse实际上被分为很多”子集群”, 每个中包含几十个节点. 这个ClickHouse集群被用来分析网站日志, 每条数据都包含一个website ID维度. 对于每个子集群都有严格分配的website ID, 对应的数据就分流到不同的子集群中. 这就在ClickHouse集群管理中引入了一些业务逻辑, 在数据导入和查询端都要处理. 还好在他们的需求中, 很少有查询需要涉及多个website ID, 而且这种查询也不是来自他们的顾客, 不需要实时SLA保证.
(译者: 非要说ClickHouse没有Druid中时间分段的设计, 我感觉时间分区本身也很有局限啊, 这也是我一直吐槽Druid的, 如果我数据本身没时间, 要怎么hack才能利用上分区这个优势呢?)
(译者: 是不是ClickHouse的默认分区策略, 比如类似key哈希取余数这种, 导致这个分区信息不能用于提前过滤? 最简单的查询都要走到所有分区上)
(译者: 这又让我联想到HBase的region)
ClickHouse这个方案的另一个缺点是, 当数据增长速度过快时, 数据不是自动rebalance的, 需要人工修改节点权重.
Druid查询处理节点分层Tiering
带有Segment的数据管理是容易推断的, Segment可以在节点间相对容易地移动. 这两个因素使得Druid实现了查询处理节点分层: 老的数据被自动移动到硬盘大但CPU和内存小的节点, 减少集群消耗. 这个功能帮助MetaMarket在Druid架构中每月节省数十万美元.
(译者: Druid tier我一直也没弄明白干啥的, 有这神奇功效??)
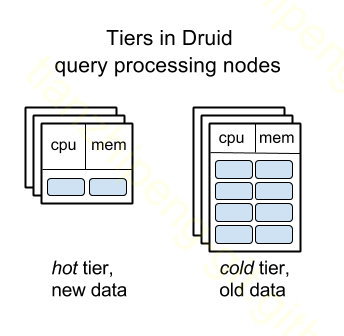
据我所知, ClickHouse和Pinot目前还没有相似功能, 但我觉得在Pinot中实现应该不难, 在ClickHouse中更困难一些, 因为Segment的概念对这类功能真的好用.
数据冗余 - Druid/Pinot
Druid/Pinot中进行数据冗余(replication)的单位是单个segment. Segment在”deep storage”和查询处理层都是冗余备份的, 在Druid/Pinot中一般每个Segment都被两个节点加载. “master”节点监控着各个segments的冗余级别, 如果冗余不足, 比如有的节点挂掉了, 就在其他一些机器上再加载这些segments.
数据冗余 - ClickHouse
ClickHouse中数据冗余的单位是表分区(a table partition on a server, i. e. all data from some table, stored on a server). 和分区相似, 在ClickHouse中数据冗余也是’静态的’, 节点知道他们互相之间的是谁的冗余(不同的表, 冗余配置是不一样的). 冗余同时提供数据耐久行和查询可用性. 当某些节点硬盘挂了, 数据也不会丢失, 因为在其他节点也有保存. 当一些节点下线, 查询也会被路由到其他冗余上.
在Yandex的最大ClickHouse集群中, 在不同数据中心上部署了两套相同的节点, 是成对的, 每一对节点互为冗余, 位于不同数据中心上.
ClickHouse依赖Zookeeper进行冗余的管理, 除此之外可以不使用Zookeeper, 也就意味着单节点ClickHouse部署不需要Zookeeper.
数据摄入 - Druid/Pinot
在Druid/Pinot中, 查询处理节点专门用于加载segments数据, 服务查询请求, 但不负责计算新插入的数据, 不负责产生新segments.
如果一个表可以接受小时级别或更长的延迟, 那么segments可以用批处理引擎来生成, 例如Hadoop或Spark. Druid/Pinot都直接支持Hadoop, 开箱即用. Druid有一个三方提供的Spark Indexing插件, 但目前不可用. 据我所知Pinot还没有这种Spark支持, 你可以自己贡献一个, 应该不是很难做.
如果一个表要实时更新, Druid/Pinot都引入了一种实时节点, 主要做三件事: 从kafka中接受新数据, 处理对于新数据的查询请求, 后台生成新segments然后推送到”deep storage”.
数据摄入 - ClickHouse
由于ClickHouse不需要准备segments来包纳一个时间段的所有数据, 所以可以有更简单的数据摄入架构. ClickHouse不需要像Hadoop这样的批处理引擎, 也没有实时节点. 常规的ClickHouse节点, 既负责存储和查询处理, 也直接接受批量数据写入.
如果一张表是分区的, 接受到写请求的节点(比如有1万行数据)会将数据根据分区信息中的节点权重分发出去.
一次批量写入的数据行形成一个小行组”set”, set会直接转化为列式格式. 每个ClickHouse节点有个后台进程负责将小行组合并为更大的行组. ClickHouse文档中称这个设计为合并树(MergeTree), 并且强调和LSM-Tree(log-structured merge trees)是相似的, 然而说实话这有些让人困惑, 因为数据根本不是组织成树形, 而是flat的列式格式.
(译者: 不知道是我还是原文作者的理解有问题, 我理解的LSM-Tree的重点是归并排序和分层/分级处理的思想, 比如HBase中内存有一个写缓存memstore, 硬盘有落地的数据HFile. 新数据来了先加入内存, 内存维护这排序后的数据, 当内存数据过多时, 落盘且归并排序. 这和数据本身是不是列式存储关系应该不大. HBase也可以理解为变向的列式存储.)
数据摄入 - 比较
在Druid/Pinot中, 数据摄入是一件很”重”的事, 由多个服务完成, 管理起来也很难.
在ClickHouse中就简单很多, 不过有一点要警告: 你需要自己有能力对数据进行”批”处理(“batch” data in front of ClickHouse). 自动批处理Kafka流是开箱即用的, 不过如有你有其他的实时数据, 比如其他的消息队列, 简单的HTTP接口消息等等, 你就需要自己创建一个”批”服务, 或者直接向ClickHouse贡献代码.
查询执行
Druid/Pinot有一类专门的节点叫”Broker”, 接受所有查询请求. 他们根据segments加载情况, 决定查询应该拆分到哪些”Historical”节点来执行. Broker在内存中保留这些segment映射的信息. Broker向下游查询节点发送子查询, 然后合并子查询结果返回最终结果给用户.
我只能猜一下Druid/Pinot设计时为什么要抽取出一类这样的节点, 现在看来很有必要, 因为随着集群segments超过千万, segment到节点的映射信息就会消耗上GB的内存, 每个查询节点都保存的话太浪费了. 这算是Druid/Pinot的segment数据管理方案的一个缺点吧.
在ClickHouse中没有必要分出一类这样的”query broker”节点. 在ClickHouse中有一个专门的”distributed”表类型, 可以在任何节点建立, 这个表做的事情就和Druid中broker负责的完全一样. 通常情况这种临时表在每个参与分区的节点上都有, 因此实际上, 每个节点都可以作为查询的入口. 这个节点会向其他分区发送必要的子查询, 合并局部结果.
当节点向其他节点发送子查询, 如果部分子查询失败了的话, ClickHouse和Pinot能正确的处理这个问题, 他们合并所有成功的子查询, 仍旧会返回给用户部分结果, Druid现在缺少这个特性, 如果任何子查询失败整个查询也就失败.(译者: 难道不是后者更合理么??)
ClickHouse vs Druid/Pinot 结论
Druid/Pinot的segment化的数据管理方式使得系统很多方面都与ClickHouse不同. 然而这些不同对数据压缩效率和查询执行速度上没有带来什么不同.
ClickHouse类似PostgreSQL这种传统关系型数据库. ClickHouse能够部署仅一台server, 在数据量相对小的时候, 比Druid/Pinot更简单, 后两者需要很多种不同节点.
Druid/Pinot类似于HBase这种大数据系统, 这么说不是因为性能因素, 而是他们都依赖Zookeeper, 依赖冗余的持久化存储(如HDFS), 他们关注克服单点故障, 自动化工作等.
对于大部分应用场景, 这三个系统中没有显著的胜者. 首先, 我觉得要最先考虑的是, 哪个系统的源码你能读懂, 理解, 修复bug, 增加特性等等. 前面的章节仔细讨论了这个问题.
其次, 我整理了下面这个表:
| ClickHouse | Druid or Pinot |
|---|---|
| The organization has expertise in C++ | The organization has expertise in Java |
| Small cluster | Large cluster |
| A few tables | Many tables |
| Single data set | Multiple unrelated data sets (multitenancy) |
| Tables and data sets reside the cluster permanently | Tables and data sets periodically emerge and retire from the cluster |
| Table sizes (and query intensity to them) are stable in time | Tables significantly grow and shrink in time |
| Homogeneity of queries (their type, size, distribution by time of the day, etc.) | Heterogeneity |
| There is a dimension in the data, by which it could be partitioned and almost no queries that touch data across the partitions are done (i. e. shared-nothing partitioning) |
There is no such dimension, queries often touch data across the whole cluster. Edit 2019: Pinot now supports partitioning by dimension. |
| Cloud is not used, cluster is deployed on specific physical servers | Cluster is deployed in the cloud |
| No existing clusters of Hadoop or Spark | Clusters of either Hadoop or Spark already exist and could be used |
注意: 以上每个格子描述的特性不代表着你一定要或者一定不能选择对应的系统. 例如, 如果你的集群规模很大, 不是说一定要选择Druid/Pinot而不能选择ClickHouse. 只是代表着Druid/Pinot更有可能成为一个好的solution, ClickHouse的其他一些特性可能使得某些时候即使是大集群也是ClickHouse是最佳方案.
Druid和Pinot区别
正如我前面多次提到的, Druid和Pinot有着相似的架构. 但是有一些特性是在一个系统中有在另一个没有的, 也有一些领域是一个系统比另一个系统的显著领先的. 这些我将要提到区别之处, 都是经过一定努力可以在另一个系统中可以实现的.
只有一个不同可能是短期内难以消除的, 就是在两个系统的”master”节点的segment管理的实现, 这个不同是难以替代的, 也是开发者不想要同质化的, 他们的实现方案都各有优缺点, 没有一个比另一个更强.
Druid的Segment管理
Druid的”master”节点不负责持久化数据segment的元信息, 也不负责持久化当前segment和查询处理节点的映射关系. 这些信息存储在Zookeeper中. 然而Druid还额外存储这些信息到SQL数据库中. 我不知道这个设计是最初就有的么, 反正目前看能带来以下好处:
- Zookeeper中要存的信息更少. 只有关于segment和查询节点的映射的最少量的信息存储在Zookeeper中. 其余的元信息, 比如segment的大小, 维度和指标的信息等等, 都存在SQL数据库中.
- 当segments因为比较老了要从集群中淘汰时(这是时序数据库的一个典型功能, 这三个系统都有), 他们会从查询节点卸载, 关于他们的元信息会从Zookeeper中删除, 但是不会从”deep storage”和SQL数据库中删除. 只要他们没有被手动的从这两个地方删掉, 当这些老数据被一些数据分析场景用到的时候, 他们能随时快速的被恢复出来.
- 虽然不大可能是早就设想好的, 但是目前Druid确实计划使得对Zookeeper的依赖变为非必须的. 当前Zookeeper被用来做三件事: segment管理, 服务发现, 属性存储库(
property store)(比如 用于实时数据摄入管理). 服务发现和property store功能可以用Consul来提供. segment管理可以用HTTP公告和命令来实现(HTTP announcements and commands), 实际上这个功能已经局部开启了, 在Zookeeper持久化功能由SQL数据库来进行后备可以看出(译者: 没看出啊).
(译者: 实际上减少对ZK的依赖或者替换ZK在Druid中被讨论了很久, 但是目前还是要用ZK, 没有Consul实现. 见这些帖子 1 2)
使用SQL数据库作为依赖的一个不好的地方是增加了很大运维成本, 支持Mysql和PostgreSQL, 有MSSQLServer的社区插件, 也支持各种云服务的RDBMS.
Pinot的Segment管理
Druid是完全自己实现的Segment管理, 依赖Curator框架和Zookeeper通信. 而Pinot不是如此, 它把segment管理和集群管理的大部分内容交给Helix框架来做.
一方面我认为这样能够让Pinot开发者更专注于系统其它方面的工作. Helix可能比Druid内部自己实现的东西bug更少, 因为他是一个在不同场景下经过测试的项目, 而且有人在该项目中投入更多的时间.
另一方面, Helix约束了Pinot的框架范围. Helix, 以及依赖它的Pinot, 可能要永久的依赖Zookeeper了.
接下来我将要列举一些Druid和Pinot更浅显的区别, 这里的浅显意味着这些区别可能很简单的在另一个系统中实现出来.
Pinot中的”谓词下推”
如果在摄入数据时, Kafka中的数据是按照一些维度进行分区1的, 那么Pinot生成的segment中会包含这些分区信息. 当执行一个带有对这些维度的断言(predicate)的查询时, broker就能够提前过滤segment, 因此有时只需要查询更少的segment, hit更少的查询处理节点. (译者: 这里1的提到的分区应该是Kafka中的分区. 原文: If during ingestion data is partitioned in Kafka by some dimension keys).
这个特性在有些应用场景下能带来很大的性能提升.
当前Druid对于Hadoop中生成segment支持基于Key的partition, 但实时数据摄入还不支持. Druid目前没有在broker上实现谓词下推.
可插入的Druid和固执的Pinot
因为Druid是由多个组织开发和使用的, 因此很长一段时间来它的各个组件和服务都有可替换选项:
- HDFS, 或者Cassandra, Amazon S3, Google Cloud Storage, Azure等等, 都可以作为”deep storage”.
- Kafka, 或者RabbitMQ, Samza, Flink, Spark, Storm都可以作为实时摄入的数据来源.
- Druid本身, 或者Graphite, Ambari, StatusD, Kafka都可以用来监测(telemetry)Druid集群(metrics).
由于Pinot几乎全是由LinkedIn开发, 满足于LinkedIn的需求, 目前它不支持这么多的用户选择: HDFS或者S3二选一作为”deep storage”, 只有Kafka可以实时摄入. 当然如果有的人需要, 我猜也不难为Pinot的各个组件引入多种替换选项. 或许这种情况在Uber和Slack开始使用Pinot之后有所改变.
Pinot中的数据格式和查询引擎更加优化
以下这些Pinot的segment格式拥有的特征是Druid目前缺乏的:
- bit粒度压缩已索引的列数据. Druid中是byte粒度.
- 每一列的倒排索引是可选的. Druid中是强制的. 有时候有些列不需要建倒排索引, 浪费了很多空间. Uber发现的Druid和Pinot空间消耗上的不同大概就归因于这个为问题.
- 数值列的最大最小值是在每个segment记录的.
- 开箱即用的支持数据排序. 在Druid中这个可以通过手动的, hackish的方式实现(前面章节描述的那样). 数据排序意味着更好的压缩效果, 因此这个区别可能也造成了两者空间效率上的不同.
- 在多值列上的优化格式, 比Druid的更好.
这些的东西在Druid中也都可以实现. 虽然目前Pinot的格式比Druid中的优化更好, 它也离真正的最优差的很远. 例如, Pinot中只使用了一些通用的压缩方法, 如Zstd, 而没有实现任何Gorilla论文中的压缩思路.
(译者: 卧槽, 了解到了一些新的压缩算法名词) (译者: 简单看过Druid的的数据格式, 虽然一知半解, 但是设计的有点乱是真的)
考虑查询执行过程, 很不幸Uber主要使用了count (*)查询来对比两个系统的性能: 在Druid中这个查询目前要进行一波呆傻的全表扫描, 虽然能很简单的替换为一个O(1)复杂度的实现. 所以如前文所说, 这是一种没什么意义的黑盒对比.
我认为Uber观察到的group by查询性能区别, 也归因于前面提到的Druid缺少数据排序的问题.
Druid的segment分配算法更智能
Pinot的算法的策略是, 将segment分配给目前加载segment数量最少的查询节点. Druid的算法更加复杂, 它把每个segment的table和time考虑进去, 使用一个复杂的公式计算一个分数, 通过给查询节点的分数排序, 选择一个最佳的节点分配segment. 这个算法在Metamarket的线上环境中带来了30%-40%的查询性能提升. 然而Metamarket对这个算法仍不满意, 可以看看这篇博客的”historical节点的巨大性能变化”的那一段的内容.
我不知道为什么LinkedIn竟然满足于Pinot如此简单的分配算法, 但是如果他们愿意花时间改善这个算法, 应该会有很大的性能提升在等待着.
此处省略两个前面已经提到过的Druid/Pinot功能特性:
- Pinot is More Fault Tolerant on the Query Execution Path
- Tiering of Query Processing Nodes in Druid
总结
ClickHouse, Druid和Pinot有者基本相似的架构, 他们有自己的舒适区(适用范围), 有别于通用的大数据处理框架如Impala, Presto, Spark, 也有别于支持数据更新的列式数据存储库如InfluxDB.
因为架构的相似性, 三者有着近似的优化极限, 但是目前来讲, 三者都很不成熟, 离这个优化极限很远. 大量的性能提升工作要耗费数月的工程开发. 我不推荐对这种系统进行性能上的对比评测, 选择一个你能看懂能修改源码的.
这三个系统中ClickHouse和其他两个更为不同. 后两个几乎是一样的, 好像是同一个系统独立开发出的两个实现.
ClickHouse类似PostgreSQL这种传统关系型数据库. ClickHouse能够部署仅一台server, 在数据量相对小的时候, 比Druid/Pinot更简单, 后两者需要很多种不同节点.
Druid/Pinot类似于Hadoop生态的大数据系统. 他们在很大规模上仍旧能够”self-driving”, 而ClickHouse需要更多专业的SRE工作. 而且Druid/Pinot更能节省一些大集群的硬件成本, 也比ClickHouse更适合在云环境中部署.
Druid和Pinot唯一较大的不同是Pinot依赖Helix框架, 也将继续依赖于Zookeeper, 而Druid正计划逐步减少对Zookeeper的依赖. 另一方面Druid的安装仍旧要依赖关系型数据库.
当前Pinot比Druid性能优化的更好(但要注意我上面说的, 我完全不推荐对这些系统进行性能对比).