HCatalog简介

Hive已经成为数仓管理的通用工具了, 其子项目HCatalog其实也很不错, 但是中文资料贼少. 下一步重构我们内部的一个数据分析平台的时候, 打算深入使用HCatalog, 所以了解记录一下.
HCatalog是什么
我们知道Hive是”A system for managing and querying structured data built on top of Hadoop”, 简单点说就是sql on hadoop:
- 文件是存在HDFS上的
- sql转换成MapReduce任务执行在yarn上
而HCatalog是Hive的一个子项目/子组件,”HCatalog is a table and storage management layer for Hadoop that enables users with different data processing tools — Pig, MapReduce — to more easily read and write data on the grid”, 中文说就是一个Hadoop上的表管理层, 让用户通过不同工具(mr, pig, spark等)轻松读写表格式的数据的.

Deploy architecture
我们通过内部结构或者说部署架构, 就能更好的理解HCatalog是什么了.
先看Hive, 下图是我从hive deployment modes文档中截取的几种模式:
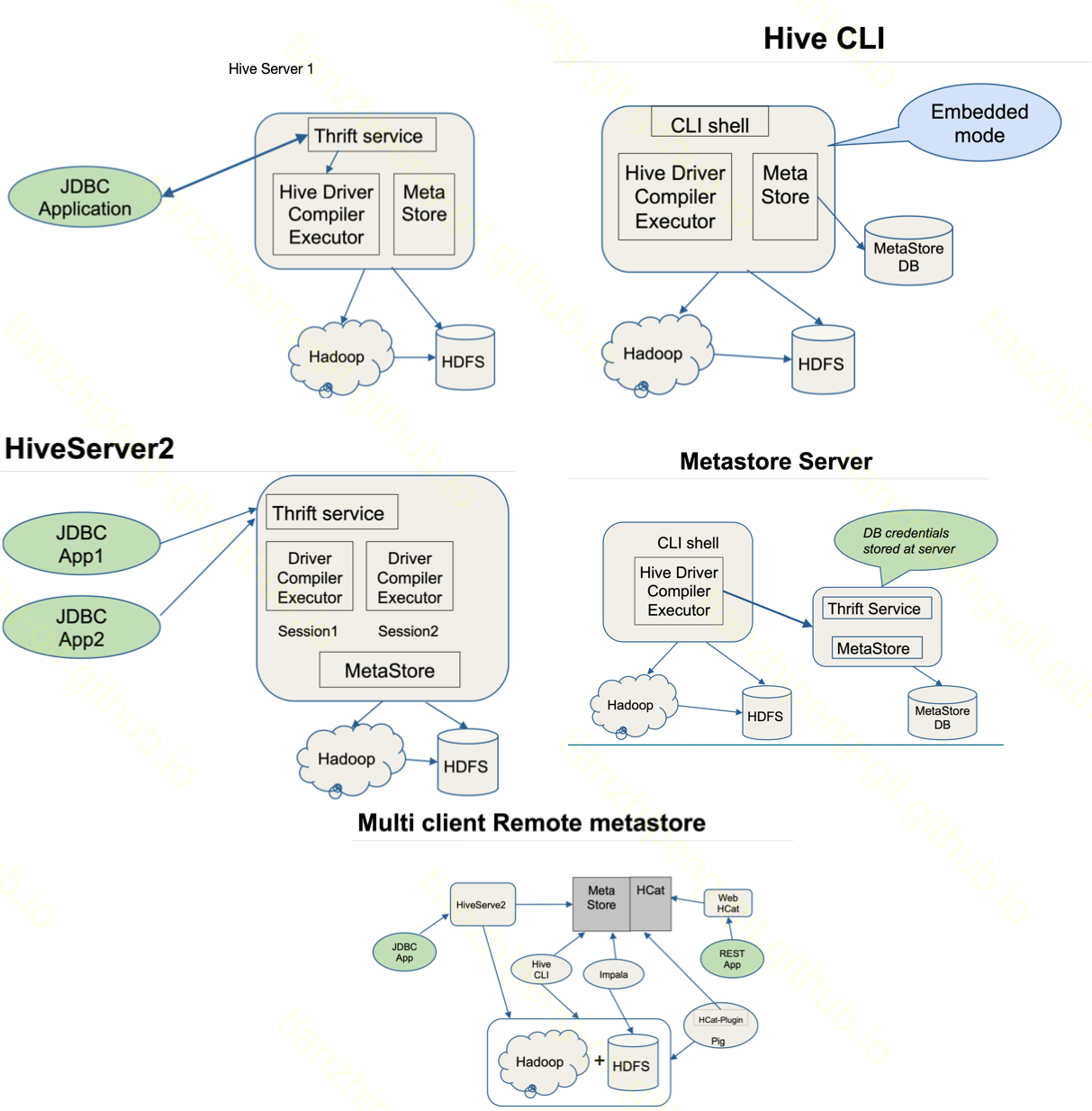
其中的MetaStore功能就Hive用来管理表元信息的, 比如数据库信息, 表信息, 各种参数, 字段信息, 分区信息等等, 这些信息都是存储在一个关系数据库中的, 比如默认的Derby, 我们一般用Mysql.
这个MetaStore的功能可以嵌入在Hive的Client/Server上, 也可以单独作为一个MetaStore Server来运行. 独立Server运行的好处是Server可以暴露Thrift接口供外部使用, 可以同时服务很多使用方, 使用方就不需要直连metaStore DB了, DB密码也自己知道就行, 安全且解耦. (见图中第4块)
说了这么多MetaStore, 其实真相就是HCatalog的server, 就是Hive MetaStore Server, 是一样的东西!!!(org.apache.hadoop.hive.metastore.HiveMetaStore).
而HCat的命令行的hcat, 说白了也就是连接这个server进行一些查询管理工作, 用hive的cli连接这个server也一样的. 能做的事情就对应Hive DDL的各项事情:
- Create/Drop/Alter Table
- Create/Drop/Alter View
- Show/Describe
- Create/Drop Index
- Create/Drop Function
Using HCatalog
我们通过HCatalog那短小的文档, 也可以了解它包含哪些功能:
- Installation from Tarball
- HCatalog Configuration Properties
- Load and Store Interfaces (Pig用的接口)
- Input and Output Interfaces (MR读写用的Input/OutputFormt)
- Reader and Writer Interfaces (程序直接读写用的)
- Command Line Interface (命令行hcat说明)
- Storage Formats (支持的文件格式)
- Dynamic Partitioning
- Notification
- Storage Based Authorization
总结起来就两点: 类似HiveDDL的表信息管理功能, 对接MR/Pig/Spark等的桥接器.
Data model
所谓的表元信息管理, 要管理的东西到底是什么呢? 其实Hive/HCatalog模仿传统的关系型数据库, 相关概念也基本很像, 整体上数据模型包含如下概念:
- Database. 抽象概念, 类似命名空间, 主要是将Table包含在Database里, 方便管理, 方便权限控制.
- Table. 真实对应数据文件.
- Record/Columns. Table中的数据分为行(row或record), 列(columns), 这和关系数据库一样. Column支持的数据类型, 除了基本的int,string之类的还支持嵌套, 这是关系数据库没有的.
- Partitions. 分区. Table中的数据可以根据用户指定的方式(如某列的hash), 进行分区, 实际上就是hdfs的文件也按分区分开存储. 另一个好用的分区方式的按日期分区, 比如一天一个分区.
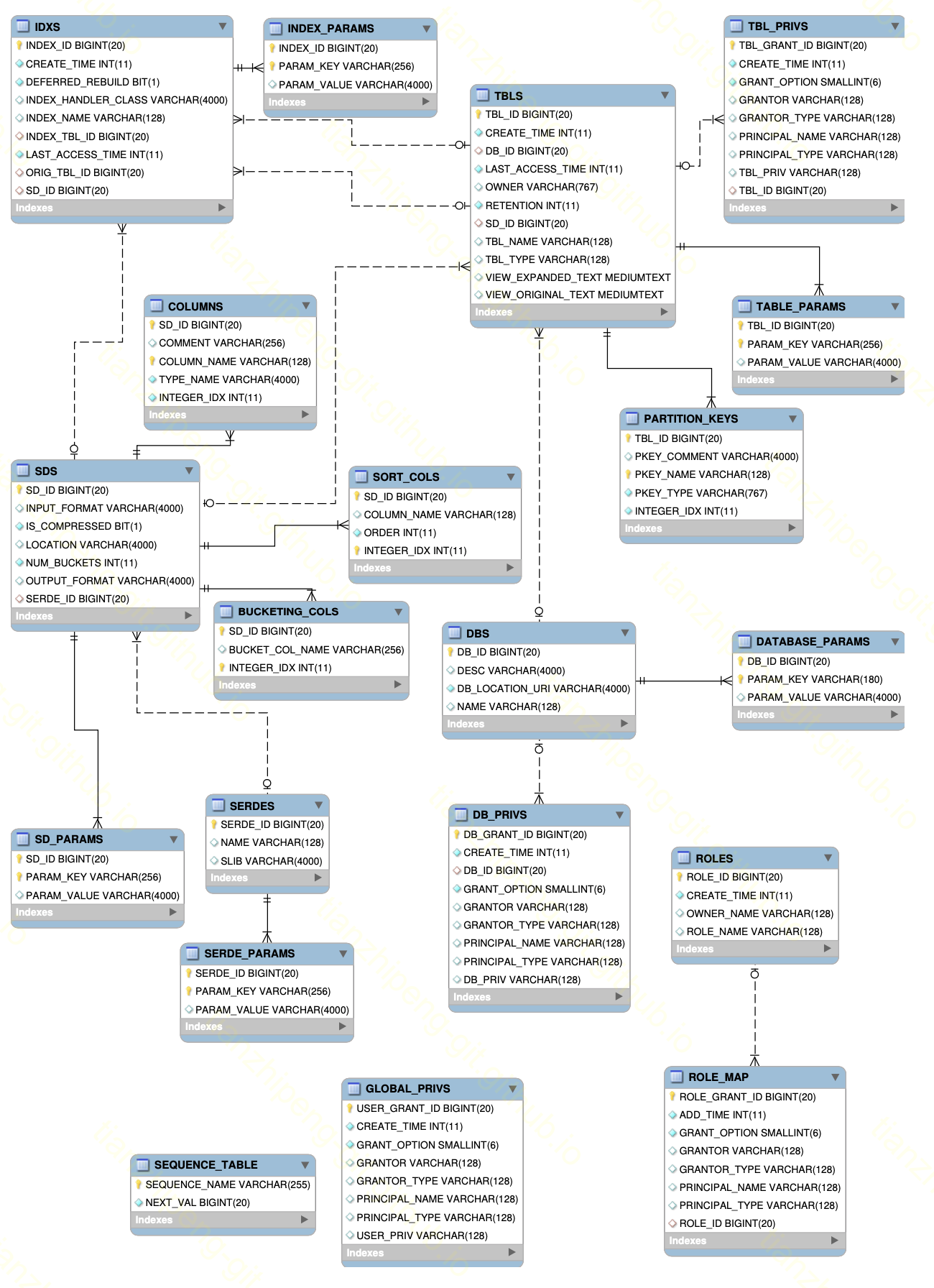
下图是MetaStore DB里的表结构(点击放大). 可以看出, 基本上就是存储上面几个东西的信息, 还有就是各种参数, 权限之类的.
如何使用 - 表信息管理
安装Hive的目录下自带HCatalog, 上面也展示了Hive部署架构, 具体的安装部署 略.
HCatalog通常的用法就是使用hcat命令, 执行各种DDL语句进行表元信息管理, 略.
这里说一下如何在程序中直接进行DDL表元信息管理.
Java HCatalog
如果有这样的需求, 要在程序内部通过代码对HCat的表进行管理, 而不是手动执行hcat, 那么该怎么做呢?
HiveConf hiveConf = new HiveConf();
hiveConf.addResource("/Users/tzp/xx/hive-site.xml");
//配置了这项, 则使用外部HMS, 否则embed
hiveConf.set("metastore.thrift.uris", "thrift://localhost:9083");
HCatClient client = HCatClient.create(new Configuration(hiveConf));HCatalog提供了一个java client, 可以如上直接连接使用. 记得在maven依赖中添加hive-webhcat-java-client, mysql-connector-java, hadoop-hdfs-client等依赖.
注意metastore.thrift.uris这个配置参数, 如果有这个参数, 则启动的HCatClient就是连接这个参数指定的外部hive metastore server; 如果没有这个参数, 启动的HCatClient则会内部启动一个嵌入的hive metastore, 就是一个embed模式.
有了这个client, hcat命令做的事就都能在程序里做了. 比如这样一个建表语句和对应的java代码:
// CREATE EXTERNAL TABLE test_table(
// prefix STRING,
// id STRING,
// xx INT)
// ROW FORMAT DELIMITED
// FIELDS TERMINATED BY '\t'
// LINES TERMINATED BY '\n'
// STORED AS TEXTFILE
// LOCATION '/hive-wksp/tmp1';
HCatTable test2 = new HCatTable("default", "test2");
HCatFieldSchema prefixFieldSchema = new HCatFieldSchema("prefix",
TypeInfoFactory.stringTypeInfo, "注释1");
HCatFieldSchema idFieldSchema = new HCatFieldSchema("id",
TypeInfoFactory.stringTypeInfo, "注释2");
HCatFieldSchema xxFieldSchema = new HCatFieldSchema("xx",
TypeInfoFactory.intTypeInfo, "注释3");
test2.cols(Arrays.asList(prefixFieldSchema, idFieldSchema, xxFieldSchema));
test2.fieldsTerminatedBy('\t')
.linesTerminatedBy('\n')
.fileFormat("textfile")
.location("/hive-wksp/tmp1");
client.createTable(HCatCreateTableDesc.create(test2, true).build());对于ORC那种嵌套的负责格式, 也可以这样
HCatTable test3 = new HCatTable("default", "test3");
String s = "id:string," +
"id_type:string," +
"spot_id:array<map<string,bigint>>," +
"region_small:array<map<string,bigint>>," +
"ip:array<map<string,string>>," +
"time_interval:map<string,bigint>";
HCatSchema schema = HCatSchemaUtils.getHCatSchema(s);
test3.cols(schema.getFields());
test3.fileFormat("orcfile")
.location("/hive-wksp/tmp2");WebHCat
除了上述的hcat命令, HCatClientjava客户端, 还有一种管理HCatalog的方式就是部署一个WebHCat服务, 通过REST接口来管理. 其内部也上用上述client做的, 对外提供的REST接口如下:
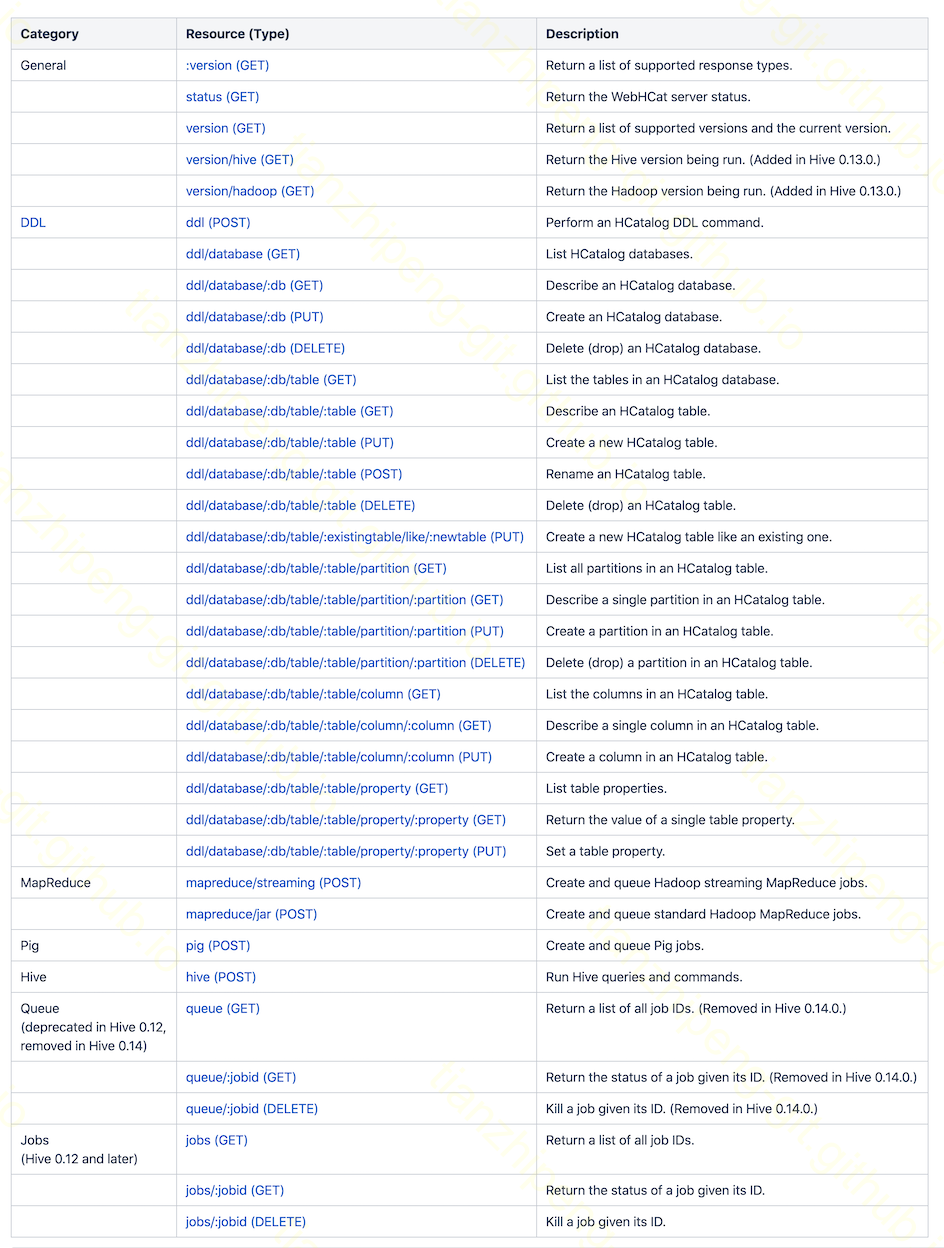
有趣的是WebHCat除了提供DDL的REST接口, 还提供了提交MR/Hive/Pig任务的REST接口, 之前怎么没发现这个好功能呢, 用这个提交MR也不错哦.
如何使用 - 对接/读写数据
我们知道MapReduce对输入输出的抽象就是InputFormat和OutpuFormat.
-
HCat的Table作为MR的输入.
这时候, 我们使用
job.setInputFormatClass(HCatInputFormat.class)作为输入format, 同时设置要读取的表名HCatInputFormatsetInput(job, dbName,inputTableName, null)使用这个HCatInputFormat, 在Mapper端我们的输入的类是HCat提供的
HCatRecord, 和我们之前读取ORC的OrcStruct不同的是, 从HCatRecord.get(xx)中获取到的东西是基本Java类型的(Integer/String), 而不像OrcStruct获取出来的Writable的对象. -
HCat的Table作为MR的输出.
也是要
job.setOutputFormatClass(HCatOutputFormat.class)设置输出format, 然后设置要输出的表名HCatOutputFormat.setOutput(job, OutputJobInfo.create(dbName,outputTableName, null))输出用的序列化类也是
HCatRecord. 输入输出的时候的key都可以忽略, value是HCatRecord. -
如果要连接远程的HCatalog Server, 主要在conf中添加
conf.set("metastore.thrift.uris", "thrift://localhost:9083");
本地执行MR-HCat遇到的一个libars的坑!
根据hive文档将需要的jar包(文档里也不全)用-libjars接到hadoop jar命令后, 依旧报错: ClassNotFoundException: org.apache.hive.hcatalog.mapreduce.HCatInputFormat
.
根据这篇SO问答 -libjars参数是将jar包发布到远程map/reduce任务的classpath下, 提交任务的本地是没有的! 本地classpath要想加这些jar包, 要通过HADOOP_CLASSPATH环境变量加!
所以完整的本地执行MR-HCat的命令这样:
export LIB_JARS=/myjarpath/hive-exec-3.1.2.jar,/myjarpath/hive-hcatalog-core-3.1.2.jar,/myjarpath/hive-metastore-3.1.2.jar,/myjarpath/jdo-api-3.0.1.jar,/myjarpath/libfb303-0.9.3.jar,/myjarpath/libthrift-0.9.3.jar,/myjarpath/datanucleus-api-jdo-4.2.4.jar,/myjarpath/datanucleus-core-4.1.17.jar,/myjarpath/datanucleus-rdbms-4.1.19.jar
export HADOOP_CLASSPATH=xxx原本的HADOOP_CLASSPATHxxx:/myjarpath/*
hadoop jar hivetutorial-1.0-SNAPSHOT.jar com.hh.xx.hcatalogmr.MyJob -libjars $LIB_JARS