一条scp命令能有多曲折

今天执行了一条scp -P 8014 xx.zip root@10.10.100.228:/data的命令, 突发奇想: 这条命令的网络旅程也是真够曲折了.
这条命令是从我本地将一个文件拷贝到k8s集群中一个容器里.
应用层角度
首先说一个简单的, 从应用层角度看, scp即secure copy:
- scp copies files between hosts on a network.
- It uses ssh for data transfer,
- and uses the same authentication and provides the same security as ssh
通过ssh的网络通道进行文件传输, 对向负责接收的是服务器上的sshd进程.
具体的scp/ssh/tsl等协议, 以及IP层的路由等就不细说了, 老生常谈.
IP包的旅行
先看完整图示再挨个解释.
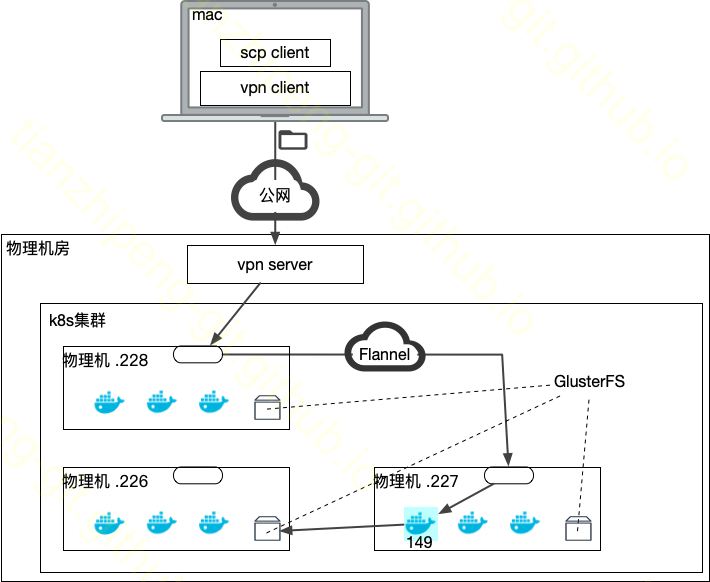
OpenVPN
接下来具体分析数据包是怎么走的.
命令中的远端ip10.10.100.228是一个内网ip, 但是他并不是存在于我笔记本所在网络的内网之中, 而是我们机房内的一台机器的内网ip, 那如何从我的电脑上连接一个’不知道在哪’的内网ip呢? 是因为我开启了一个vpn:
- vpn client会在我电脑上配置虚拟网卡.
- 会改变我的路由表, 将要走这个vpn的ip的数据转交给它 netstat -nr:
10.10.100/24 172.100.0.1 UGSc tap0. - vpn对端有一个有外网暴露的服务器, 上面部署有vpn的server.
-
vpn client从我这将数据包重新组装之后通过外网发给那台设备.
IP包在vpn client和server之前必定经过了修改和还原, 因为原始的IP包的目标地址是10.x要改成server的外网ip
- 那台设备位于机房, 可以找到
10.10.100.228在哪
具体OpenVPN的协议和设计的网络概念, TODO留坑待填.
K8S&Docker
VPN的server将数据包转发给10.10.100.228这台机器, 到这里进入了k8s网络的范围了. 结合上一篇k8s网络的文章分析一下.
已知如下事实:
- 我的容器内在22端口启动的sshd服务, 然后通过
NodePort类型的service将端口交给k8s, k8s启用了8014的NodePort端口做映射. - 对于这个NodePort类型的service, k8s会在集群每个节点(本例中是裸金属物理机)上, 启动8014端口.
- k8s的servcie的路由, 主要靠每台节点上的kube proxy控制器配合iptabels规则来实现的.
通过sevice可以看到更多信息:
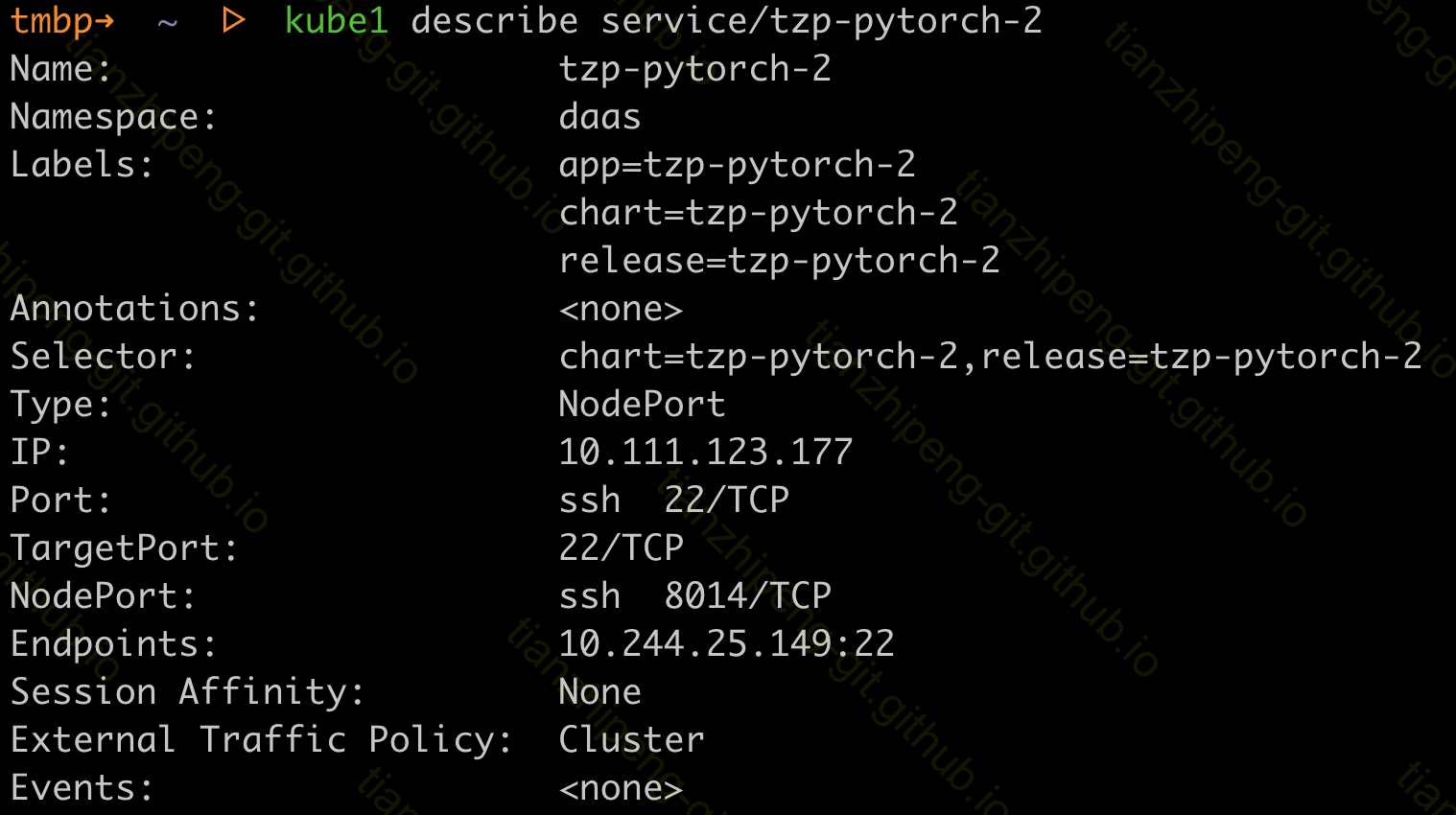
包到达之后的处理顺序:
- 228这台机器收到IP包, 这个包的目标ip地址确实就是它, 所以开始进行处理.
- iptables中的规则, 根据8014端口可以判断是
tzp-pytorch-2这个servcie的转发端口, 所以将ip包修改为发往service的ip和端口的(即CluserIP 10.111.123.177和端口22). - 对于CluserIP 10.111.123.177, iptables还需要根据规则, 从对应的pod列表中选择一个pod(就是k8s的service负载均衡在这里发生), 本例中只有一个pod, 所以将包改为发往pod IP 10.244.25.149和端口22
- 目标ip是pod ip的包”离开”228这台机器
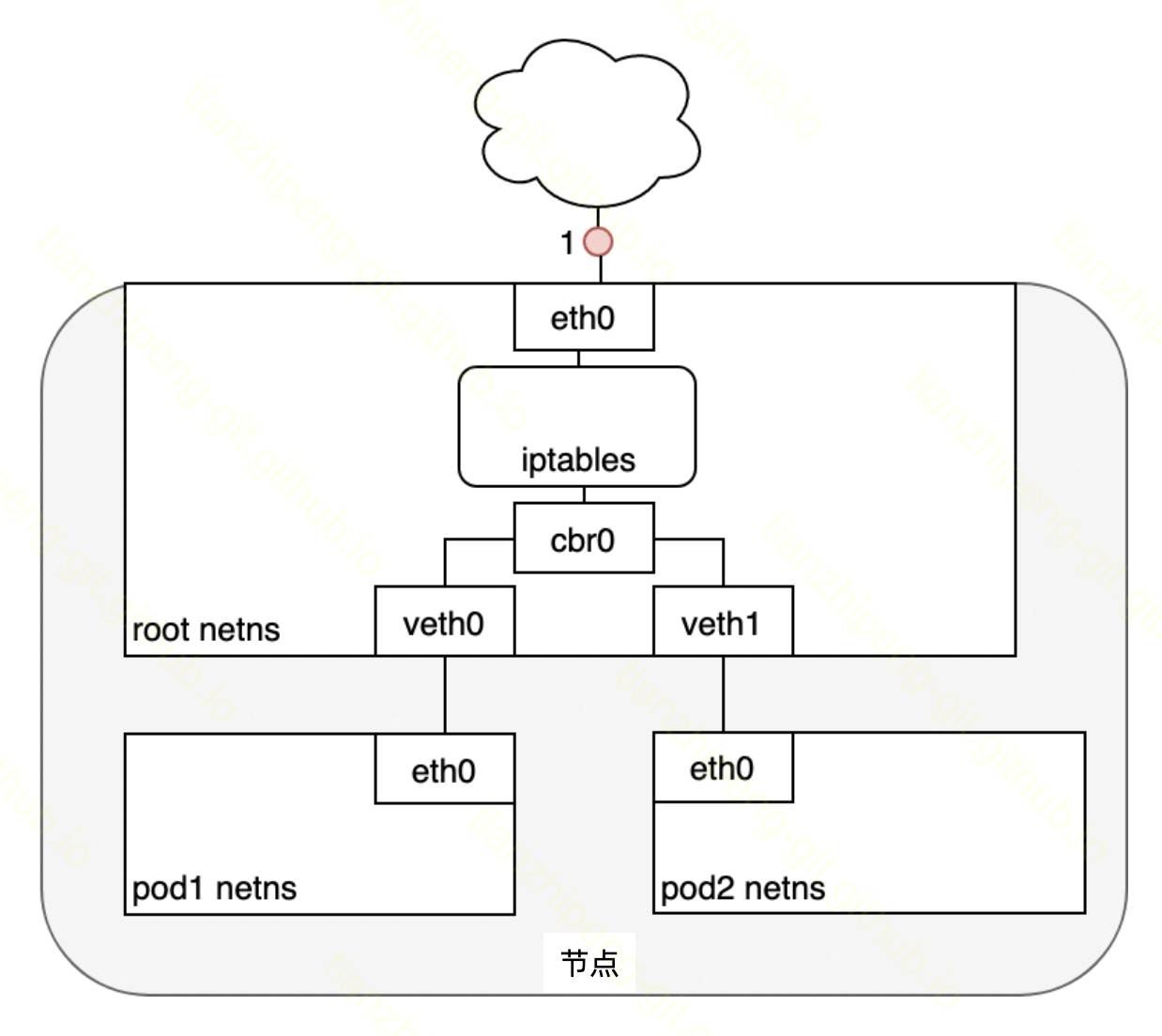
这步的具体细节我的理解可能有偏差,下面开始碎碎念. 因为k8s节点的主机内部, 借助网桥,虚拟网卡,veth pair等功能管理网络, 所以网桥以下是否参与呢? 有如下可能.
- 上步改为ClusterIP后, iptables又根据规则直接改为pod ip,
iptables知道这个pod ip不在本机(可能性不大)iptables不知道pod ip在哪, 所以直接向上通过eth0离开228这台机器. - 上步改为ClusterIP后, iptables又根据规则直接改为pod ip, iptables不知道pod ip在哪, 但是向下发给了网桥, 网桥上对于这个ip没有对应路由, 默认发回eth0离开228这台机器.
- 上步改为ClusterIP后, 向下发往了网桥, 网桥上对于这个IP没有对应路由, 默认发回eth0, 经过iptables时根据规则改为pod ip, 通过eth0离开228这台机器. 事实1: 网络插件Flannel哪里, 不知道service ip在哪, 因为是proxy和iptables负责负载均衡的, 发到Flannel那里时, 已经改为pod ip了. 3和上面的区别是, 是否iptables直接进行cluster ip到pod ip的负载均衡选择和ip修改. 为什么iptables会在input的时候简单cluster ip呢, 根据上一条, 只有NodePort类型会出现这种情况. 所以他可以在这直接做了, 没必要多走一步. 所以3排除. 1和2相比, 如果pod恰好在本机的话, 1方案浪费步骤, pod不在本机的话2方案浪费步骤. 2的可能性大.
- iptables中的规则, 根据8014端口可以判断是
- 目标ip是pod ip的包”离开”228这台机器, 为什么要加引号呢, 因为pod ip也是虚拟的, 并不是任意一台物理机的真实ip, 这里就需要k8s网络插件工作的地方了, 它来保证根据pod ip可以路由到正确的节点上.
- 比如Flannel插件, 使用VXLAN技术处理k8s集群节点间的网络.
- 目标ip是pod ip的包到达227这台机器, 我的pod真实运行在这个节点. 数据包经过真实网卡eth0, 网桥cbr0, veth对, 虚拟网卡eth0, 最终到达在我容器中运行的sshd进程!
-
具体过程参考上一篇文章. 结构如下图示
-
GlusterFS
然而, 事情到这里还没有结束, 我的容器中的/data目录不是简单的容器文件系统目录, 而是挂载的pvc数据卷, df -h:
10.10.100.226:vol_e9ca393523aba1090b11164400f69349 5.0G 1.6G 3.4G 32% /data
我们机器配置的是GlusterFS的分布式文件系统, 挂载到容器中作为数据卷的, 这是一个网络文件系统. sshd收到数据包, 要保存成文件的时候, 又要发送到另一台机器!
关于GlusterFS以及GlusterFS如何配合k8s, TODO留坑待填.