[译]spark-sql分桶最佳实践

spark sql中使用分桶能极大提高join/采样/聚合等操作的效率, 这里翻译一篇实践文章. 原文, (机翻+人工修订).
Bucketing 是 Spark 从 2.0 版本开始支持的一个特性.这是一种如何组织文件系统中的数据并在后续查询中利用这些数据的方法.有很多资源可以解释bucketing的基本思想,在本文中,我们将更进一步,更详细地描述bucketing,我们将看到它的各个不同方面,并解释它在底层是如何工作的,它是如何演变的, 最重要的是如何有效地使用它.
我们将从两个不同的角度来看待bucketing - 作为数据用户的数据分析师的角度,以及负责准备数据并将其公开给数据用户的数据工程师的角度. 同时我们将讨论 Spark 3.1.1(撰写本文时的最新版本)中对分桶的最新增强功能.
什么是分桶?
让我们从这个简单的问题开始.Spark 中的 Bucketing 是一种以特定方式组织存储系统中的数据的方法,以便后续的查询可以变得更加高效.如果分桶设计得当,它可以避免 连接(join)和聚合(group/reduce)中的shuffle.
使用 sort-merge join 或 shuffle-hash join 和聚合、窗口函数的查询, 需要通过join/分组key重新分区数据.更具体地说,所有具有相同join/分组key值的行必须在同一个分区中.为了满足这一要求,Spark 必须对数据进行重新分区,为了实现这一点,Spark 必须将数据从一个执行器物理移动到另一个执行器——即进行所谓的 shuffle(另请参阅我与此主题密切相关的另一篇文章).
使用bucketing,我们可以提前对数据进行shuffle,并将其保存在这个pre-shuffled状态.从存储系统读回数据后,Spark 会知道这个分布,而不必再次 shuffle!
如何使数据分桶
在 Spark API 中有一个函数bucketBy可用于此目的:
df.write
.mode(saving_mode) # append/overwrite
.bucketBy(n, field1, field2, ...)
.sortBy(field1, field2, ...)
.option("path", output_path)
.saveAsTable(table_name)
这里有四点值得一提:
- 我们需要将数据保存为table(简单的保存文件是不够的),因为有关分桶的信息需要保存在某处.调用saveAsTable将确保元数据保存在元存储中(如果 Hive 元存储设置正确),并且当访问表时 Spark 可以从那里选择信息.
- 与bucketBy一起,我们也可以调用sortBy,这将按指定的字段对每个桶进行排序.调用sortBy是可选的,分桶也可以在没有排序的情况下工作.反过来是行不通的——如果你不调用bucketBy,你就不能调用sortBy.
- bucketBy的第一个参数是应该创建的桶数.选择正确的数字可能很棘手,最好考虑数据集的整体大小以及创建的文件的数量和大小(请参阅下面更详细的讨论)
- 粗心使用bucketBy函数可能会导致创建过多的文件,并且在实际写入之前可能需要对DataFrame 进行自定义重新分区——请参阅下面有关此问题的更多信息(在从数据工程师的角度进行存储部分).
数据在bucket之间是如何分布的?
所以我们知道分桶会将数据分布到一些桶/组中.您现在可能想知道这些桶是如何确定的.假定有一个行数据,我们知道它最终会在哪个桶中吗?是的!粗略地说,Spark使用一个哈希函数,该函数应用于分桶字段,然后计算哈希值对桶数取模(hash(x) mod n).此模运算可确保创建的桶数不超过指定数量.为简单起见,我们首先假设在应用哈希函数后我们得到这些值: (1, 2, 3, 4, 5, 6 ) 并且我们要创建 4 个桶,因此我们将计算模4.模函数返回整数除法后的余数:
1 mod 4 = 1 # 整数除法后的余数
2 mod 4 = 2
3 mod 4 = 3
4 mod 4 = 0
5 mod 4 = 1
6 mod 4 = 2
计算出的数字是最后一个桶.如您所见,我们只是将这六个值分配到四个桶中.
更准确地说,Spark 使用的不是简单的模函数,而是所谓的正模,它确保最终的存储桶值为正数.
Spark 使用的哈希函数是通过 MurMur3 哈希算法实现的,该函数实际上公开在 DataFrame API 中(参见文档),因此如果需要, 我们可以使用它来计算相应的存储桶:
from pyspark.sql.functions import hash, col, expr
(
spark.range(100) # this will create a DataFrame with one column id
.withColumn("hash", hash(col("id")))
.withColumn("bucket", expr("pmod(hash, 8)"))
)
(注意pmod函数是在expr内部调用的,因为该函数在 PySpark API 中不直接可用,但在 SQL 中可用)
分桶的优势
分桶的主要目标是加快查询速度并提高性能.分桶可以在两个主要方面提供帮助,第一个是避免在带有连接和聚合的查询中shuffle,第二个是通过称为”存储桶修剪(bucket pruning)”的功能减少 I/O.让我们在以下小节中更详细地了解这两种优化机会.
Shuffle-free joins
如果您要join两个表并且它们都不是特别小,Spark 将必须确保两个表以相同的方式分布在集群上(根据join键),因此将shuffle数据(两个表都将被shuffle). 在查询计划中, join的两个分支中都可以看到一个Exchange运算符. 看一个例子:
tableA.join(tableB, 'user_id')
如果最终使用了sort-merge join, 则执行计划将如下所示:
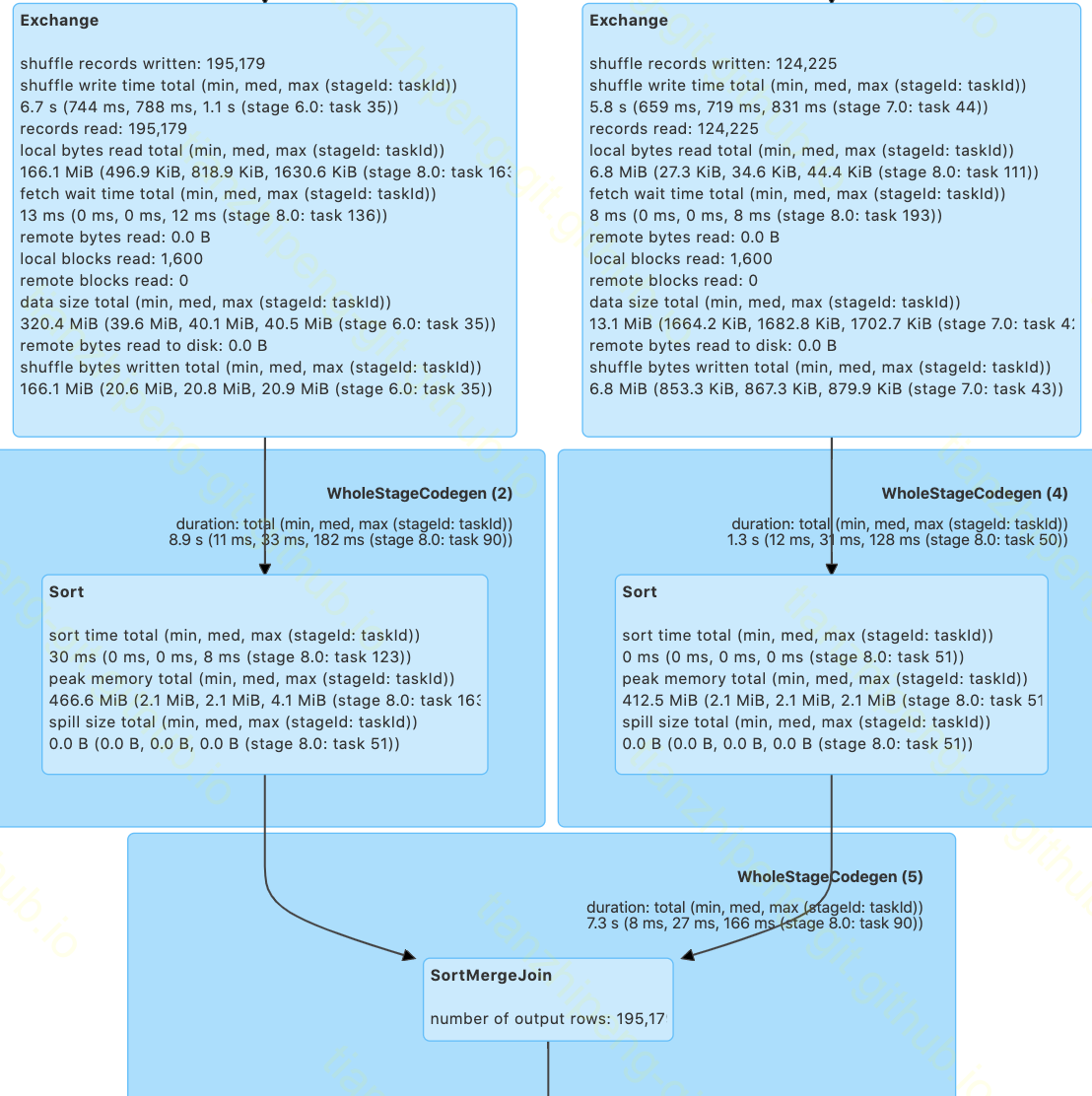
如您所见,join的每个分支都包含一个表示shuffle的Exchange运算符(请注意,Spark 不会总是使用sort-merge join来连接两个表 - 查看有关 Spark 用于选择join的逻辑的更多详细信息算法,请参阅我的另一篇 关于join的文章).
但是,如果这两个表通过join key字段, 插入相同数量的分桶时,spark将根据这种分布去读取集群上的数据,因此不需要额外的重新分区和重新shuffle-上述Exchange将不再出现在执行计划:
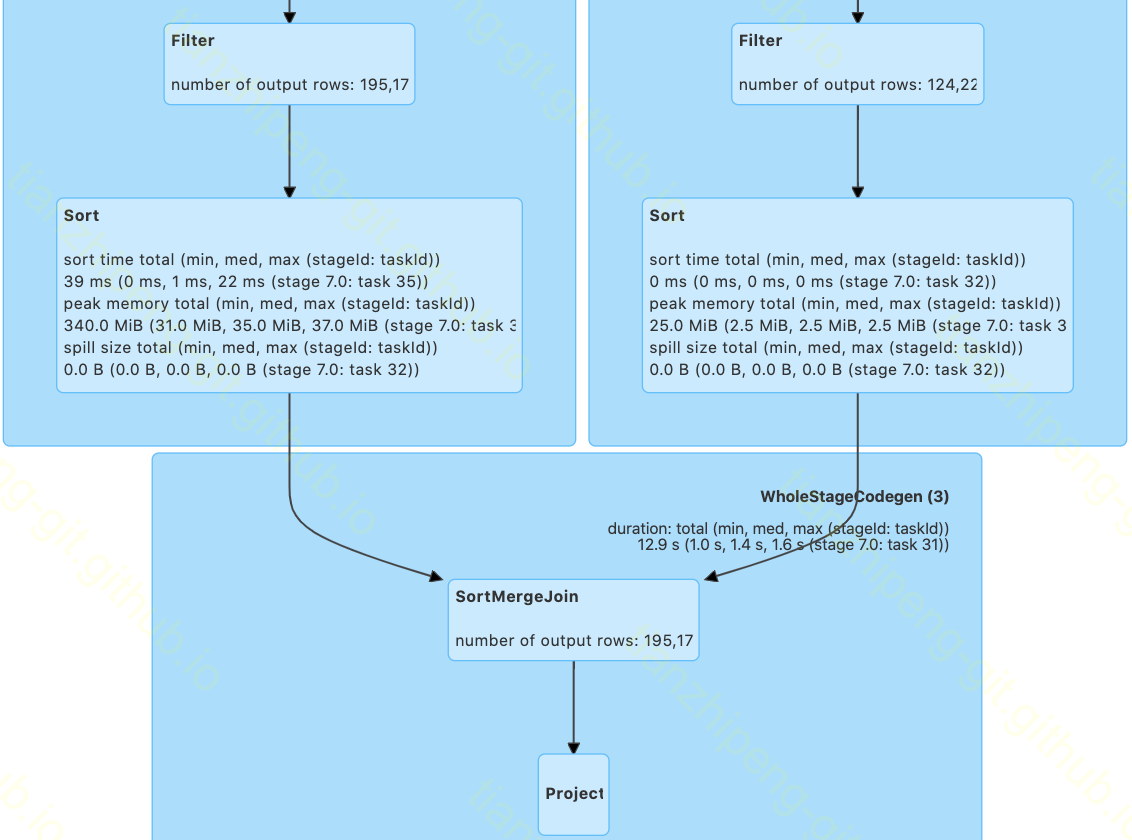
One-side shuffle-free join
一个有趣的问题是,如果只有一个表被分桶而另一个没有被分桶会发生什么。答案实际上取决于桶的数量和 shuffle 分区的数量。如果桶的数量大于或等于 shuffle 分区的数量,Spark 将只对连接的一侧进行 shuffle - 没有被分桶的表。但是,如果桶的数量少于shuffle分区的数量,Spark 将shuffle两个表,并且不会利用其中一个表已经分布良好的事实。shuffle 分区的默认数量为 200,可以使用以下配置设置进行控制:
spark.conf.set("spark.sql.shuffle.partitions", n)
为了确保tableA的分桶被利用,我们有两个选项,要么我们将 shuffle 分区的数量设置为桶的数量(或更小),在我们的示例中为 50,
# 如果 tableA 被分到 50 个桶中而 tableB 没有被分桶
spark.conf.set("spark.sql.shuffle.partitions", 50)
tableA.join(tableB,joining_key)
或者我们通过显式调用repartition 将tableB重新分区为 50 个分区,如下所示:
tableA.join(tableB.repartition(50,joining_key),joining_key)
这两种技术都将导致单侧无shuffle的join,这也可以从查询计划中看出,因为Exchange运算符将仅位于join的一个分支中,因此只会对一张表进行混洗。
Tables with different bucket numbers
我们可以在这里考虑另一种情况。如果两个表都被分桶,但分到不同数量的桶中怎么办?会发生什么取决于 Spark 版本,因为在 3.1.1 中针对这种情况进行了增强。
在 3.1 之前,这种情况实际上类似于之前的情况,只有一个表被分桶,另一个没有. 换句话说,当shuffle分区和桶数满足特定条件,会对一张表进行shuffle, 我们将获得One-side shuffle-free join, 否则两张表都会shuffle。这里的条件与之前类似——shuffle partitions的数量必须等于或小于较大表的bucket数量。让我们通过一个简单的例子来更清楚地看到这一点:
- 如果tableA有50个桶,tableB有100个,并且shuffle分区的数量是200(默认),在这种情况下,两个表都将被 shuffle 为200个分区。
- 如果 shuffle partitions 的数量设置为 100 或更少,则只有tableA将被改组为 100 个分区
- 同样,我们也可以将其中一个表重新分区为另一个表的桶数,在这种情况下,在执行过程中也只会发生一次 shuffle。
在 Spark 3.1.1 中,实现了一项新功能,如果桶号是彼此的倍数,则可以将较大数量的桶合并为较小的桶。此功能默认关闭,可以通过此配置设置spark.sql.bucketing.coalesceBucketsInJoin.enabled进行控制。因此,如果我们打开这个配置并再次将tableA放入50个桶中,将tableB放入100个桶,则连接将是无shuffle的. 因为Spark会将tableB合并到50个桶中,两个表将具有相同的分区数量,无论shuffle partitions数量如何,都会是shuffle-free的。
What about the sort?
我们已经看到,通过分桶,我们可以从sort-merge join的计划中消除Exchange。该计划还包含Sort运算符,就在Exchange之后,因为必须对数据进行排序才能正确merge。我们也可以消除排序吗?您可能会说是,因为分桶也支持排序,我们可以在bucketBy之后调用sortBy并对每个桶进行排序,因此应该可以在连接期间利用它。但是,sort 的情况更为复杂。
在 Spark 3.0 之前,如果每个存储桶都由一个文件组成,则可以从join执行计划中消除Sort运算符。在这种情况下,Spark能够确信它从集群的数据是已排序的, 所以最终的计划是sort-free的。但是,如果每个存储桶有更多文件,Spark 无法保证数据是全局排序的,因此将Sort运算符保留在计划中——数据必须在join执行期间进行排序。(请参阅下面从数据工程师的角度进行分桶一节,了解如何为每个存储桶实现只有一个文件。)
在 Spark 3.0 中,情况发生了变化,默认情况下,即使每个存储桶只有一个文件,也会存在Sort。进行此更改的原因是列出所有文件以检查每个存储区是否只有一个文件过于昂贵(如果文件太多),因此决定关闭此检查并始终将排序放在计划中(sort-merge join)。正如您所看到的,这是一种权衡,一种针对另一种优化的优化。还引入了一个新的配置项spark.sql.legacy.bucketedTableScan.outputOrdering,您可以将其设置为True以强制执行 3.0 之前的行为,仍然利用一个文件的排序存储桶.
Shuffle-free aggregations
与连接类似,聚合也需要在集群上正确分配数据,通常 Spark 必须为以下查询打乱数据
# 如果 tableA 没有被分桶,这需要部分 shuffle:
(
tableA
.groupBy('user_id')
.agg(count('*'))
)
# 如果 tableA 没有被分桶,这需要完全 shuffle:
(
tableA.withColumn('n', count('*').over(Window().partitionBy('user_id')))
)
但是,如果tableA由字段user_id分桶,则两个查询都将是shuffle-free的。
Bucket pruning
Bucket pruning是Spark 2.4中发布的一个特性,它的目的是在表被分桶的字段上使用过滤器的情况下减少I/O。让我们假设以下查询:
spark.table('tableA').filter(col('user_id') == 123)
如果表没有分桶,Spark 将不得不扫描整个表来找到这条记录,如果表很大,它可能需要启动和执行许多任务。另一方面,如果表被分桶,Spark 将立即知道该行属于哪个桶(Spark 使用模计算哈希函数以直接查看桶号)并且只会从相应的桶中扫描文件。Spark 如何知道哪些文件属于哪个桶?好吧,每个文件名都有一个特定的结构,不仅包含有关它所属的存储桶的信息,还包含生成该文件的任务的信息,如下图所示:
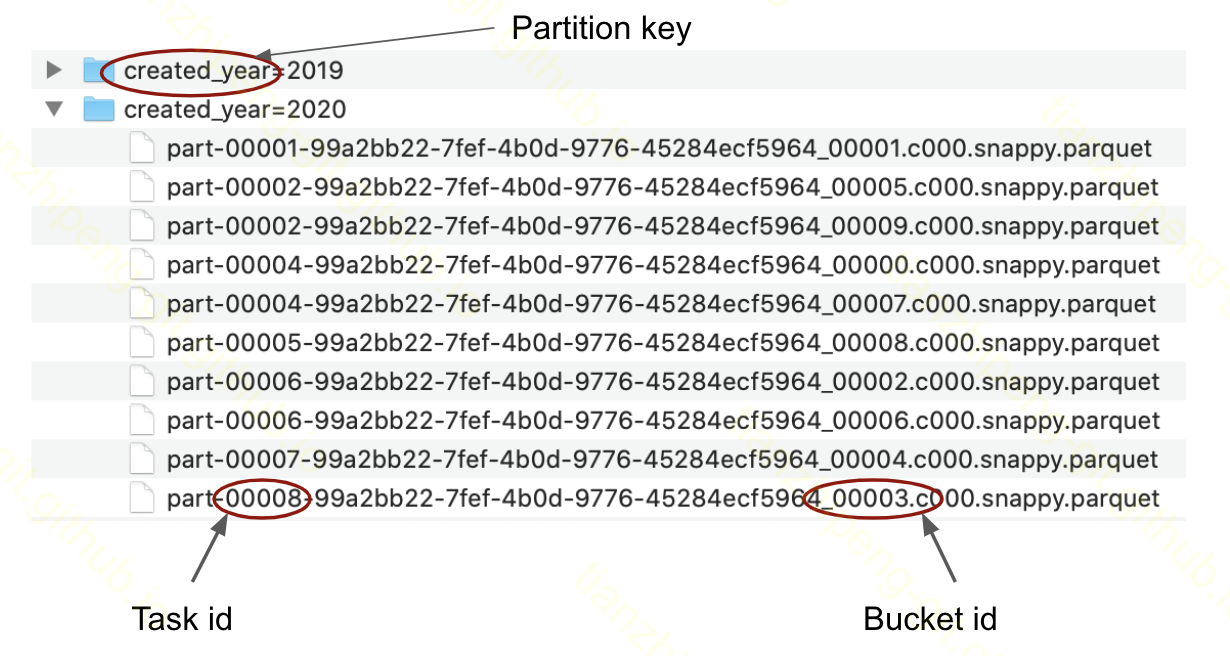
如果表非常大,桶修剪会导致巨大的加速。
分桶的缺点
我们刚刚描述了分桶可以提供的优势。您可能想知道是否也有一些缺点,或者只是在某些情况下最好避免它。实际上确实有一点需要牢记, 分桶的一个后果是执行期间的并行化。如果你要查询的一个表被分到n个桶中,那么会导致作业的第一阶段将有n个任务, 如果表没有分桶或分桶被关闭,许多任务可能会有很大不同,因为Spark会尝试将数据拆分为每个分区大约 128 MB 的分区(这是由配置控制的, spark.sql.files.maxPartitionBytes), 所以任务有合理的大小并且不会遇到内存问题。
如果一个表被分桶并且随着时间的推移它的大小增加并且桶变大,那么关闭分桶以允许 Spark 创建更多分区并避免数据溢出问题可能会更有效。这在不执行任何可以直接利用分桶提供的分布的操作时尤其有用(就是执行不需要join/aggr的查询时, 关闭分桶可能效率更好)。
在Spark 3.1.1中实现了一个新功能,它可以基于查询计划(无连接或聚合)识别出分桶没有作用的情况,并且会关闭分桶,它将丢弃分布并扫描数据, 和没有分桶时一样。此功能默认开启,可以通过spark.sql.sources.bucketing.autoBucketedScan.enabled配置控制。
从数据分析师的角度来看
数据分析师想要查询数据,在理想情况下,他不想关心表如何存储在数据湖中的细节。好吧,我们并不生活在一个理想的世界中,有时了解有关表的一些详细信息以利用更快的执行并获得更好的性能仍然很有用。重要的是至少能够检查在查询中是否利用了分桶,或者是否可以利用它,换句话说,是否有一种方法可以轻松实现查询的某些性能改进。
Is the table bucketed?
要查看表是否以及如何分桶,我们可以通过调用 SQL 语句简单地检查有关表的详细信息
spark.sql("DESCRIBE EXTENDED table_name").show(n=100)
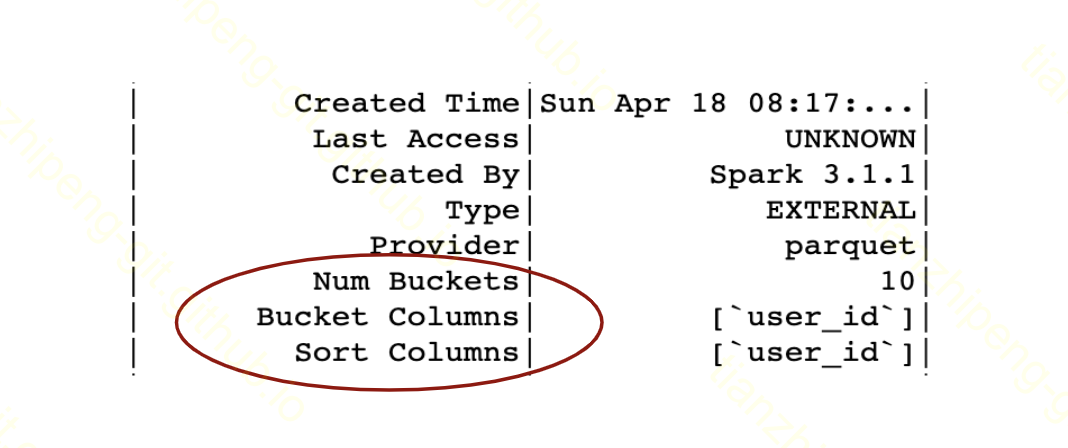
从中,您可以看到该表是否被分桶,哪些字段用于分桶以及该表有多少个桶。(注意我们这里调用show(n=100)是因为show函数默认只显示20行,但是如果表的schema很大,前20行不会出现bucketing的信息,所以要注意根据表,可能需要显示更多行以查看分桶信息)
Is the bucketing leveraged in my query?
首先必须启用bucketing,这是默认的,但如果你不确定,可以如下检查
spark.conf.get("spark.sql.sources.bucketing.enabled")
# 它应该返回True。此配置设置可用于控制存储桶是打开还是关闭。
如果表被分桶,则有关它的信息将保存在 Metastore 中。如果我们希望 Spark 使用它,我们需要以表的形式访问数据(这将确保 Spark 从 Metastore 获取信息):
# Spark 将使用来自 Metastore 的关于分桶的信息:
df = spark.table(table_name)
# Spark 不会使用关于分桶的信息:
df = spark.read.parquet(path_to_data)
请注意,在我们直接从路径访问数据的第二种情况下,Spark 不会与 Hive 元存储通信,也不会获取有关分桶的信息——不会使用分桶。 最后但并非最不重要的一点是,我们可以检查查询计划,看看计划中是否有我们想要避免它们的地方有Exchange操作符。
Can I help Spark?
通常,如果表在相同数量的桶中进行分桶,则分桶将开箱即用。但在某些情况下,Spark 将无法利用分桶,而我们实际上可以帮助使其发挥作用。让我们看看其中的一些情况。
列不同名
在Spark 3.0之前,如果我们想要join的两个表中的分桶列具有不同的名称,并且我们将 DataFrame 中的列重命名为具有相同的名称,分桶将停止工作。在以下查询中不会完全利用分桶:
# The bucketing information is discarded because we rename the
# bucketed column and we will get extra shuffle:
(
tableA
.withColumnRenamed('user_id', 'userId')
.join(tableB, 'userId')
)
# Here bucketing will work:
(
tableA
.join(tableB, tableA['user_id'] == tableB['userId'])
)
此问题已在 Spark 3.0 中修复.
列不同类型
另一件需要注意的事情是连接列的数据类型必须相同。让我们假设这个例子:tableA被user_id分桶,它是整数类型,tableB也被user_id分桶,但它是长类型的,两个表都被分到 50 个桶中。在这种情况下,每个表中连接列的数据类型都不同,因此 Spark 将不得不对其进行强制转换,将丢弃分桶信息并且两个表都将被shuffle:
尽管如此,我们可以帮助 Spark 实现至少单侧 shuffle-free join,如下所示;
tableA
.withColumn('user_id', col('user_id').cast('long'))
.repartition(50, 'user_id')
.join(tableB, 'user_id')
如您所见,我们将两个表中的数据类型显式转换为相同,然后将更改后的表重新分区为与另一个表相同数量的分区。shuffle 只会发生在我们重新分区的这一侧,另一个 table 将是 shuffle-free。这基本上等同于只有一个表被分桶而另一个没有被分桶的情况。
如您所见,我们将两个表中的数据类型显式转换为相同,然后将更改后的表重新分区为与另一个表相同数量的分区。shuffle 只会发生在我们重新分区的这一侧,另一个 table 将是 shuffle-free。这基本上等同于只有一个表被分桶而另一个没有被分桶的情况。
连接中带有UDF
本节中的最后一个示例与在带有连接的查询中使用用户定义函数 (UDF) 相关。我们需要记住,UDF 会丢弃有关bucketing 的信息,因此如果我们在join之前调用UDF,会导致与只有一张表被bucket相同的情况。两个表都将被打乱,或者如果我们重新分区表或将打乱分区的数量设置为桶的数量,我们将有单边无混洗连接:
# Spark 会因为 UDF 对两个表进行混洗
(
tableA.withColumn('x', my_udf('some_col'))
.join(tableB, 'user_id')
)
# One-side shuffle-free join:
(
tableA.withColumn('x', my_udf('some_col'))
.repartition(50, 'user_id') # 假设我们有 50 个桶
.join(tableB, 'user_id')
)
# One-side shuffle-free join:
# 将 shuffle 分区的数量设置为桶数(或更少):
spark.conf.set('spark.sql.shuffle.partitions', 50)
(
tableA.withColumn('x', my_udf('some_col'))
.join(tableB, 'user_id')
)
如果我们想完全避免shuffle,我们可以在join后调用UDF
tableA
.join(tableB, 'user_id')
.withColumn('x', my_udf('some_col'))
从数据工程师的角度来看
数据湖中的表通常由数据工程师准备。他们需要考虑如何使用和准备数据,以便为数据用户(通常是数据分析师和科学家)提供服务。分桶是一种需要考虑的技术,与分区类似,分区是如何在文件系统中组织数据的另一种方式。现在让我们看看数据工程师通常必须面对的一些问题。
如何创建分桶表
我们已经在上面的查询看到了bucketBy函数的使用. 实践中的关键问题变成了如何控制创建文件的数量。我们需要记住,Spark作业最后阶段(stage)的每个任务(task)都会为其承载数据的每个存储桶创建一个文件。让我们假设在这个例子中,我们处理一个 20 GB 的数据集,我们在最后一个阶段将数据分配到 200 个任务中(每个任务处理大约 100 MB),我们想要创建一个包含 200 个存储桶的表。如果集群上的数据是随机分布的(这是一般情况),这 200 个任务中的每一个都将携带这 200 个桶中的每一个的数据,因此每个任务将创建 200 个文件,导致 200 x 200 = 40 000 个文件,其中所有最终文件都将非常小。您可以看到结果文件的数量是任务数量与请求的最终存储桶数量的乘积!
我们可以通过在集群上实现我们希望在文件系统(存储)中拥有的相同分布来解决这个问题。如果每个任务只有一个桶的数据,在这种情况下,每个任务只会写入一个文件。这可以通过在写入之前自定义重新分区来实现
df.repartition(expr("pmod(hash(user_id), 200)"))
.write
.mode(saving_mode) # append/overwrite
.bucketBy(200, 'user_id')
.option("path", output_path)
. saveAsTable(table_name)
这将为每个存储桶创建一个文件。正如您所看到的,我们完全按照 Spark 在后台使用的相同表达式对数据进行重新分区,以在存储桶之间分配数据(有关其工作原理的更多详细信息,请参阅上面的相关部分)。您实际上可以在这里使用更简单的df.repartition(200, ‘user_id’)具有相同的结果,但上述方法的优点是,如果您想同时将文件系统中的数据分区,它也可以使用另一个字段如下
df.repartition(200, "created_year",expr("pmod(hash(user_id), 200)"))
.write
.mode(saving_mode)
.partitionBy("created_year")
.bucketBy(200, "user_id")
。 option("path", output_path)
.saveAsTable(table_name)
这里每个文件系统分区将恰好有 200 个文件(每个桶一个文件),因此文件总数将是桶数乘以文件系统分区数。请注意,如果您只调用df.repartition(200, “created_year”, “user_id”),达不到这种效果。
如何确定合理的桶数
这可能很棘手,取决于多种情况。考虑最终bucket的大小很重要——记住,当你读回数据时,一个bucket会被一个task处理,如果bucket过大,task会遇到内存问题,Spark会必须在执行期间将数据溢出到磁盘上,这将导致性能下降。根据您将对数据运行的查询,每个存储桶 150-200 MB 可能是一个合理的选择,如果您知道数据集的总大小,您可以从中计算要创建多少个存储桶。
在实践中,情况更为复杂,面临以下挑战:
- 表不断地被追加,它的大小随着时间的推移而增长,桶的大小也是如此。在某些情况下,如果数据集也按某个日期维度(例如年和月)进行分区并且桶在这些分区中均匀分布,则这可能仍然没问题。如果典型的查询总是只询问最近的数据,例如最近 6 个月,我们可以设计桶,使合理的大小对应于 6 个月的数据。桶的总大小会增加,但没关系,因为我们永远不会要求整个桶。
- 数据是倾斜的——如果桶键的特定值的记录比键的其他值多得多,就会发生这种情况。例如,如果表按user_id 进行分桶,则可能有一个特定用户有更多的交互/活动/购买或数据集代表的任何内容,这将导致数据倾斜——处理这个更大桶的任务将花费更长的时间。
分桶功能的演变
- Spark 2.4 中的改进 Bucket pruning(请参阅Jira)——使用过滤器减少 I/O。
- Spark 3.0 中的改进
丢弃有关排序的信息(请参阅Jira)——这实际上并不是对分桶的改进,而是相反。在此更改之后,
sort-merge join始终需要排序,无论桶是否已排序。这样做是为了有一个更快的解释命令,该命令需要执行文件列表以验证每个存储桶是否只有一个文件。有一个配置设置可以恢复原始行为(spark.sql.legacy.bucketedTableScan.outputOrdering,默认情况下它是False所以如果你想在连接期间利用排序的桶,你需要将它设置为True)。另外,请参阅上面相关部分中有关排序的讨论。 尊重输出分区中的别名(请参阅Jira)——即使我们重命名分桶列,它也可以确保sort-merge join对于分桶表是无随机的。 - Spark 3.1 中的改进 合并分桶表以进行连接(请参阅Jira)——如果两个表具有不同数量的存储桶,则启用无随机连接。请参阅上面相关部分中有关该功能的讨论。 通过规则启用/禁用分桶(请参阅Jira)——如果无法在查询中利用分桶,则该规则将关闭分桶。
- 未来的改进
以下列出了在撰写本文时(2021 年 4 月)尚未实现的几个功能:
- 添加桶扫描信息来解释(见Jira)——如果在查询计划中使用桶,请参阅信息
- 读取多个已排序的存储桶文件(请参阅Jira)——即使每个存储桶有更多文件,也可以利用已排序的存储桶进行
sort-merge join - Hive 分桶写入支持(请参阅Jira)——启用与 Hive 分桶的兼容性(因此 Presto 也可以利用它)
与分桶相关的配置
我们已经在整篇文章中看到了一些,在此处统一列出它们:
spark.sql.sources.bucketing.enabled— 控制分桶是否开启/关闭,默认为True。spark.sql.sources.bucketing.maxBuckets— 可用于表的最大桶数。默认情况下,它是 100 000。spark.sql.sources.bucketing.autoBucketedScan.enabled— 如果没有作用,将丢弃分桶信息(基于查询计划分析)。默认情况下它是True。spark.sql.bucketing.coalesceBucketsInJoin.enabled— 如果两个表具有不同数量的桶,它将合并具有较大数量的表的桶以与另一个表相同。只有当两个数字都是彼此的倍数时才有效。它也受下一个配置设置的约束。默认情况下它是False。spark.sql.bucketing.coalesceBucketsInJoin.maxBucketRatio— 进行合并工作的两个桶号的最大比率。默认为 4。也就是说,如果一个表的桶数是另一个表的 4 倍以上,则不会进行合并。spark.sql.legacy.bucketedTableScan.outputOrdering— 使用 Spark 3.0 之前的行为来利用来自分桶的排序信息(如果我们每个桶有一个文件,这可能很有用)。默认情况下它是False。spark.sql.shuffle.partitions— 控制 shuffle 分区的数量,默认为 200。
译者补充
与hive的分桶
目前spark的分桶与hive的分桶是两个不同的东西, 不兼容:
- 不可读hive分桶表, 不可写hive分桶表!
- spark分桶表, 在hive中是普通表, 只不过表的TBLPROPERTIES能看出, spark保存了自己的分桶信息.