DDIA读书笔记-复制

重读«数据密集型应用系统设计»的第五章复制, 并给组内同学做了分享. 复制是分布式数据中必需的一个环节, 本文结合书中内容以及几个常见开源系统中复制的实例, 找了大量图片, 更好了解复制过程. 各架构图来源见文后参考.
What & Why
定义:
- 复制(replica)意味着在通过网络连接的多台机器上保留相同数据的副本
目的:
- 使得数据与用户在地理上接近(从而减少延迟)
- 即使系统的一部分出现故障,系统也能继续工作(从而提高可用性)
- 扩展可以接受读请求的机器数量(从而提高读取吞吐量)
难点:
- 如果复制中的数据不会随时间而改变,那复制就很简单:将数据复制到每个节点一次就万事 大吉。
- 复制的困难之处在于处理…..复制数据的变更(change)
How
书中将复制方法分为几类:
- 单主复制
- 多主复制
- 无主复制
每种复制中又涉及各种问题, 单主复制比较简单直接, 重点看这部分. 另外两个较难还没理解好.
①单主复制
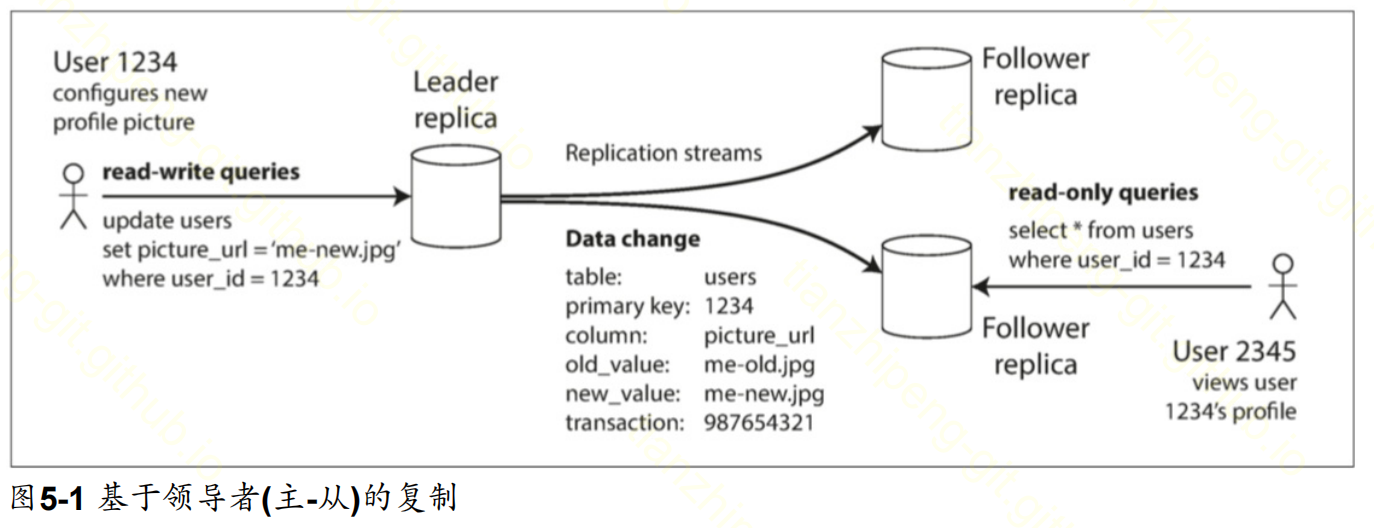
单主复制最为简单, 我觉得也是最有效的. 是指在数据的多个副本节点中, 有一个角色特殊, 作为主节点.
客户端对数据的修改请求, 都要由主节点来处理, 再将更新同步到从节点上.
同步/异步复制
上述将数据变更发送到从节点的过程, 可以是同步或者异步的.
- 同步一般是串行的, 阻塞等待的.
- 同步比较稳妥, 但是很慢
- 异步一般是并行的, 不等待的, 异步一般会需要ACK机制, 确认收到了
- 异步比较快, 但是会丢失和不一致
下图中绿色线是同步复制, 红色线是异步复制.
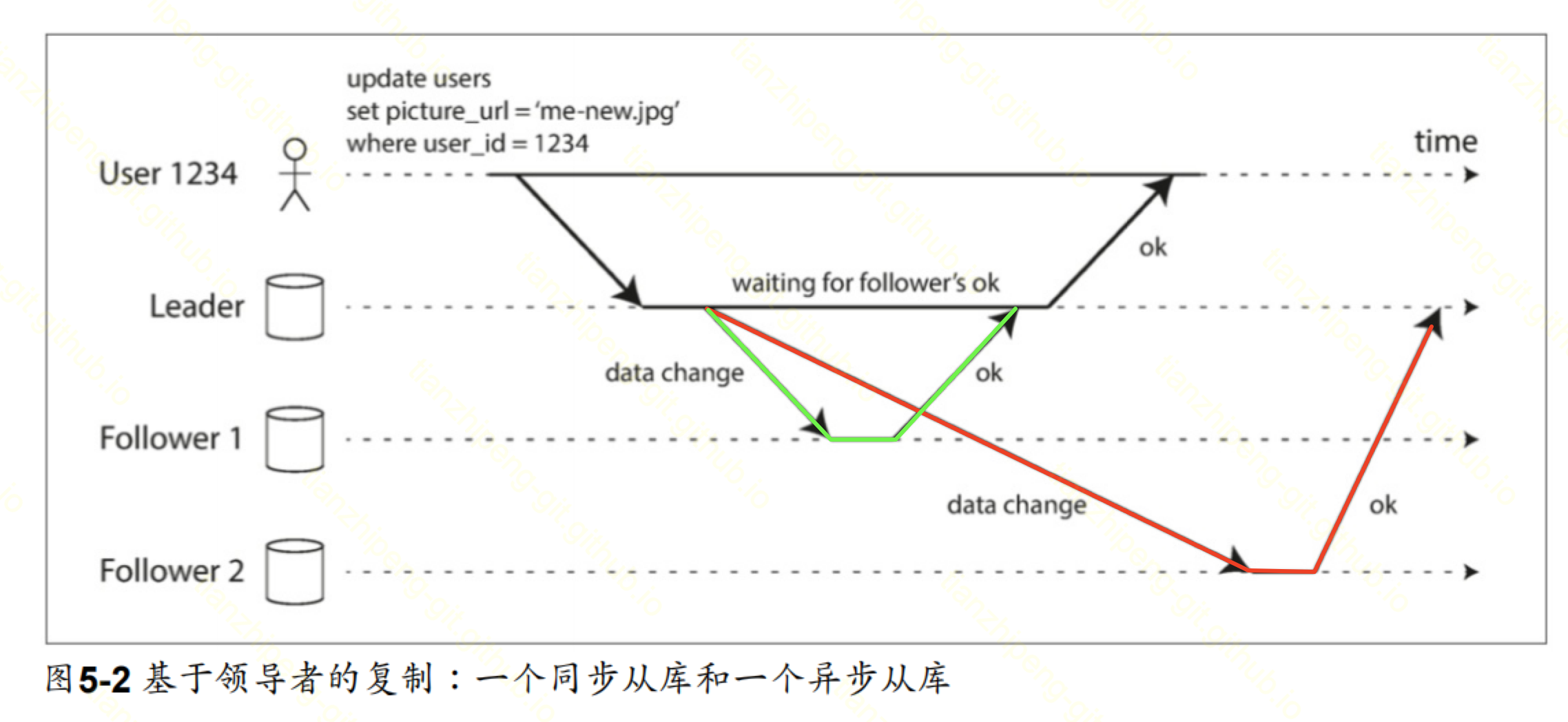
(这种一个库有同步节点也有异步节点, 一般称为半同步复制)
实例 - MySQL主从异步复制
MySQL数据库中, 最基本的多节点部署方式, 就是主从异步复制.
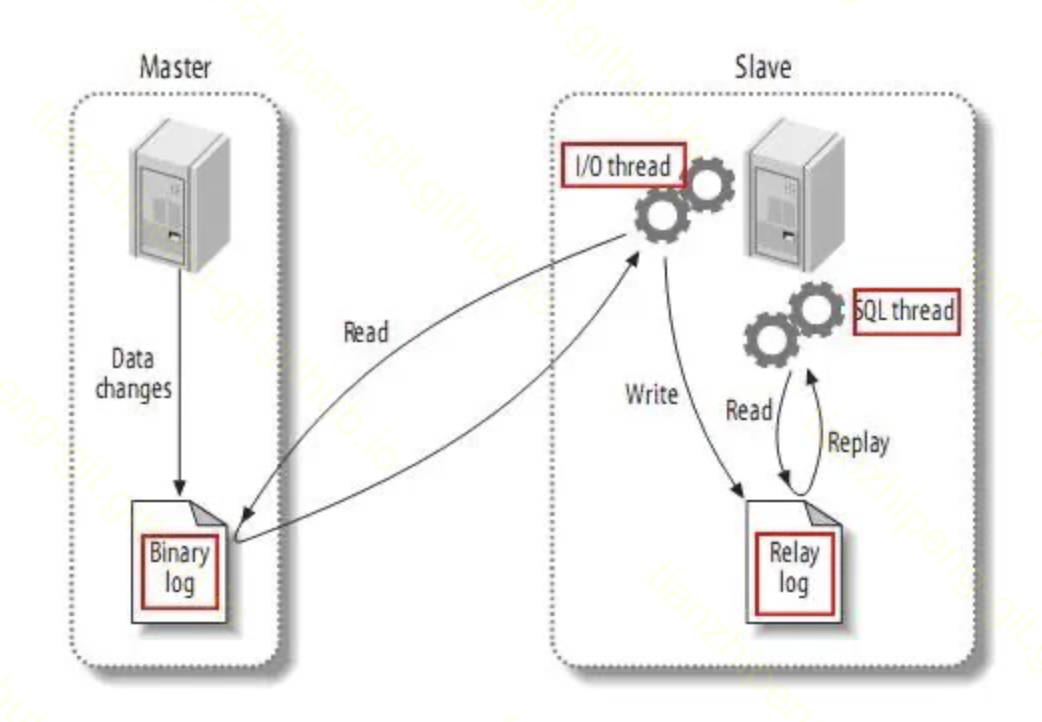
- Master节点将数据变更写到binlog
- Master不会等待Slave的任何动作, 写完binlog直接commit并返回
- Slave节点将binlog同步到自己的节点, 形成replay log
- Slave节点重放这个日志, 实现数据同步
时序图如下:
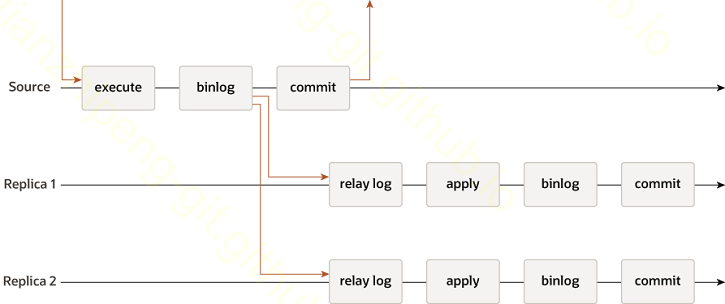
实例 - MySQL主从半同步复制
MySQL后续版本中, 提供了新的半同步复制方式. 时序图如下:
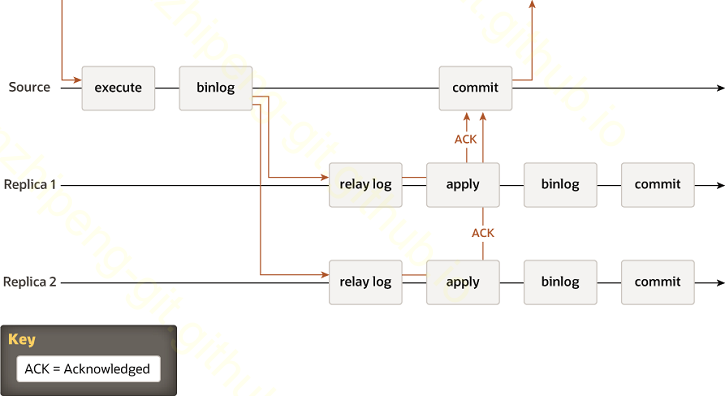
可以看出, 主节点在commit之前, 需要等待x个从节点发来的ack消息.
实例 - HDFS并行同步复制
HDFS也是有三备份的, 当然HDFS数据是不可修改的, append only的. 也可以从它的写操作流程了解它的复制过程.
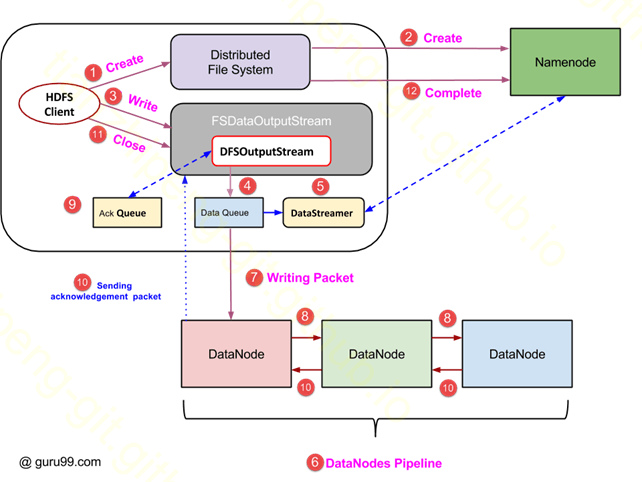
主要关注⑦⑧⑨⑩这几个动作.
- ⑦ 将data队列中的packet写到第一个HDFS节点上, 可以称之为主节点
- ⑧ 三个datanode的节点已组成一个pipeline, 数据依次复制到两位两个节点上
- ⑩ packet成功写入后, 按照反着的顺序依次返回ack, 最终返回给客户端这个packet已写好三份
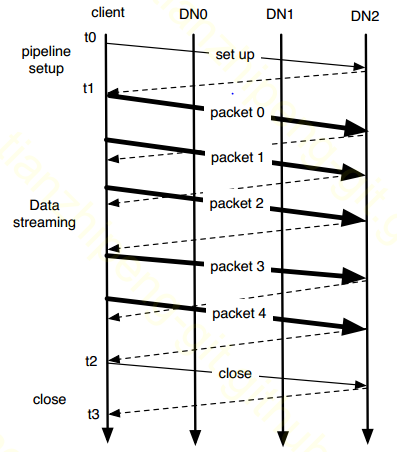
⑨ 这里需要注意的是, 客户机写完packet不是直接丢掉, 而是放到一个ack队列中等待返回的ack. 同时这里不是等第一个packet全部流程走完再写第二个packet, 这样太慢, 而是第一个packet写完放到ack队列, 直接就写后续packet. 我称之为并行复制. 时序图如下:
实例 - HBase同步复制
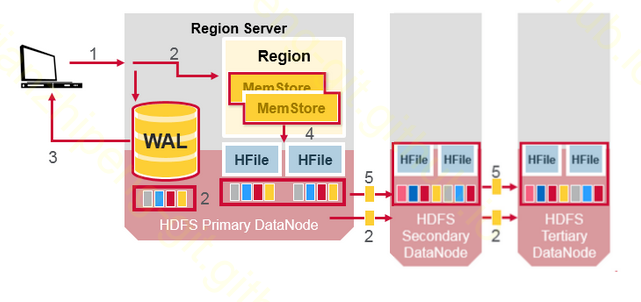
其实在这里提到HBase例子不是很典型, 因为HBase没有提供上述意义下的复制, 但是我们用的比较多, 还是聊一下.
HBase数据是分Region的, 每个Region的数据存在于三个地方. WAL日志中/RegionServer内存中/HFile文件中.
HBase的复制机制, 其实就是利用HDFS的三备份机制, 本质就是将WAL和HFile放在HDFS上, 通过WAL和HFile是能完整的还原数据的.
但是只有这个主的RegionServer在内存中维护了Memstore, 也只有他提供读写服务.
RS写WAL日志的过程, 默认是同步的, 而且WAL写到HDFS也是同步的, 所以一定是三备份都写完, 才能步骤2写到RS内存里. (是配置成异步写WAL或者跳过WAL的)
注意这里描述的是单个HBase集群内一个Region的复制, 而不是HBase提供的跨集群replication功能
实例 - Kafka半同步复制
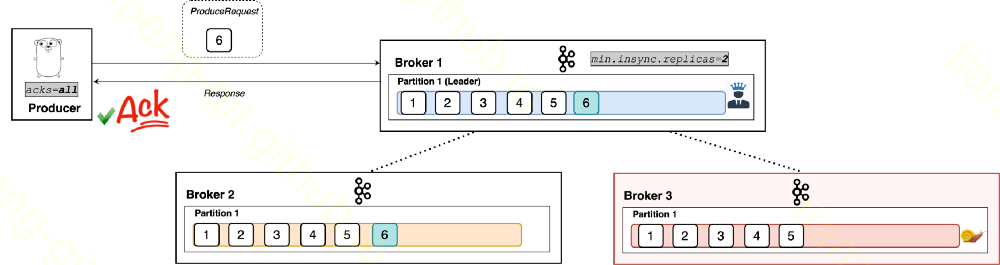
kafka的节点本身, 是没有leader/follower的概念的, 是在具体的topic的partition下, 每个partition有leader副本和follower副本. follower也相当于kafka的consumer, 订阅和同步leader副本上最新的消息.
kafka通过一下三个概念灵活的控制复制的过程:
- ISR (In Sync Replicas, 10s内跟得上的副本集合)
- ACK配置 (生产者配置的, 需要写成功几个副本. 如:0/1/2/all)
- minimum in-sync replica配置 (兜底保障, 防止ISR过少时写入成功副本不足)
在上图的例子中, 总副本数是3, ISR包含1号和2号两个副本,
- 如果生产者配置的ack=0, 不管是否写成功直接继续.
- 如果生产者配置的ack=1, 那么会等待1号leader副本写成功才会确认.
- 如果生产者配置的ack=2或all, 那么会等待1号和2号两个副本都写成功才会确认.
all不是所有副本都写完, 是所有ISR都写完. minimum in-sync replica配置, 如果写成功的ISR副本小于这个配置会报错, 即使满足了ack要求.
复制内容的几种方案
以上都在聊复制的交互流程, 那么具体复制的东西/内容是什么呢? 有几种常见方案
基于语句的复制
复制的内容是数据变更的语句, 如SQL.
实例:
- MySQL: Statement Based Replication(SBR)
传输预写式日志 WAL
复制的内容包含所有对数据库写入的仅追加字节序列, 包含哪些磁盘块中的哪些字节发生了更改.
实例:
- HDFS
- HBase?
- Kafka?
逻辑日志复制(基于行)
复制的内容是被改变的数据行, 如果一条语句改变很多行, 所有行都要记录.
实例:
- MySQL: Row Based Replication (RBR)
复制延迟问题
对于多副本的系统, 一般可以通过读写分离实现拓展性. 在写操作的节点和读操作的节点不是一个, 而且复制还有延迟(尤其是异步复制)的情况下, 会出现数据不一致的情况.
书中提到几种解决思路: TODO
- 读己之写
- 单调读
- 一致前缀读
- 分布式事务
②多主复制
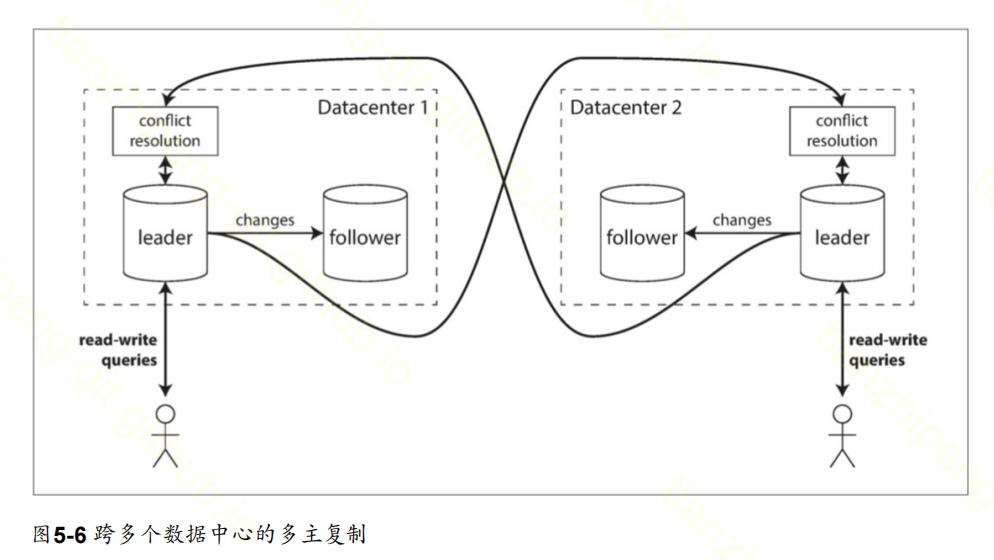
多主是只多个数据副本中有多个主节点的角色, 多主有几个有趣的场景:
- 运维多个数据中心
- 离线操作的客户端(印象笔记那种)
- 协同编辑(在线文档那种)
多主复制的最大问题是可能发生写冲突,需要解决冲突, 不同的多主系统中各有自己的冲突应对办法TODO:
- 同步与异步冲突检测
- 避免冲突
- 收敛至一致的状态
- 自定义冲突解决逻辑
实例 - MySQL双主双活
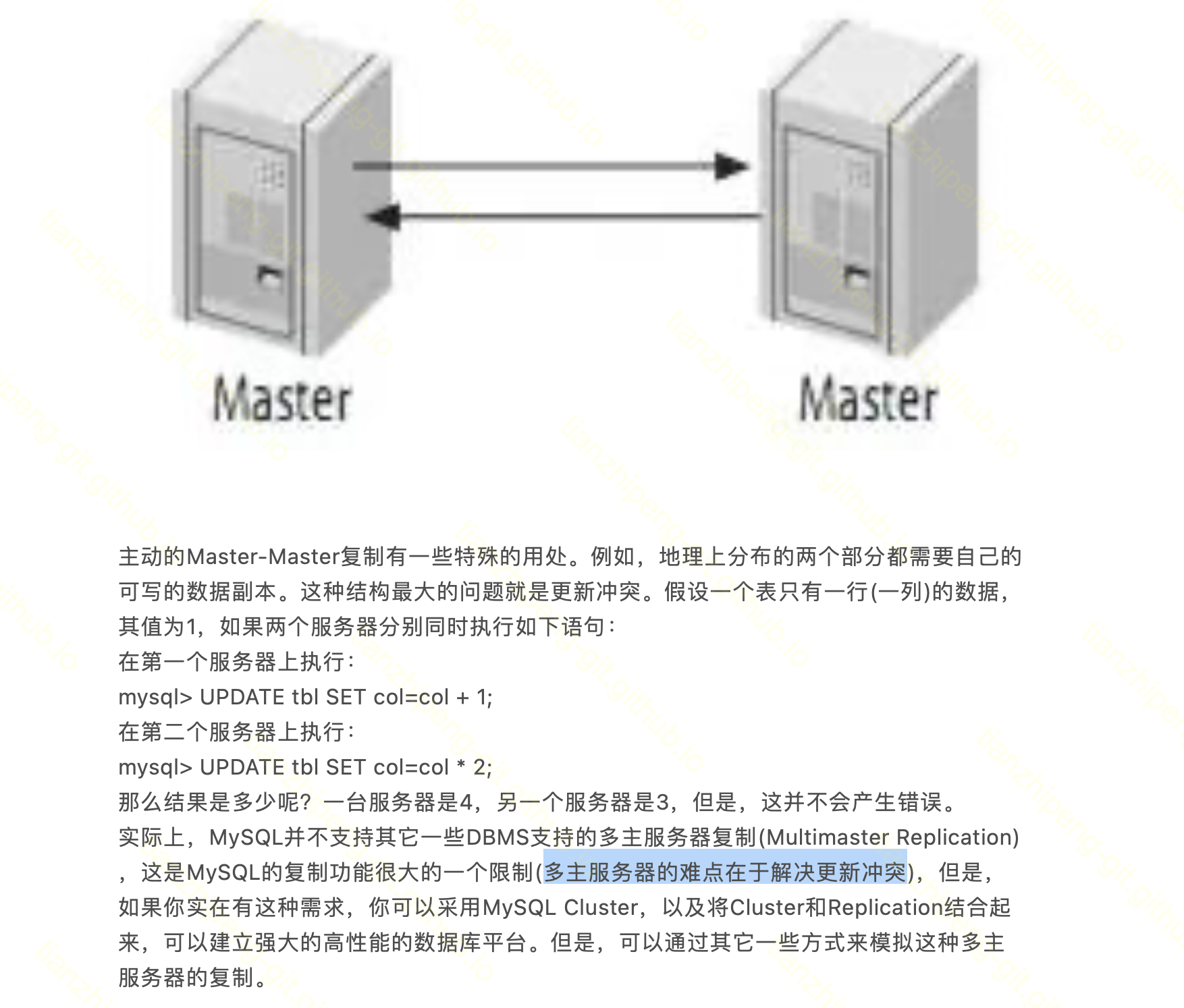
MySQL的双主双活其实不算多主复制, 它没有处理冲突.
实例 - MySQL组复制GR
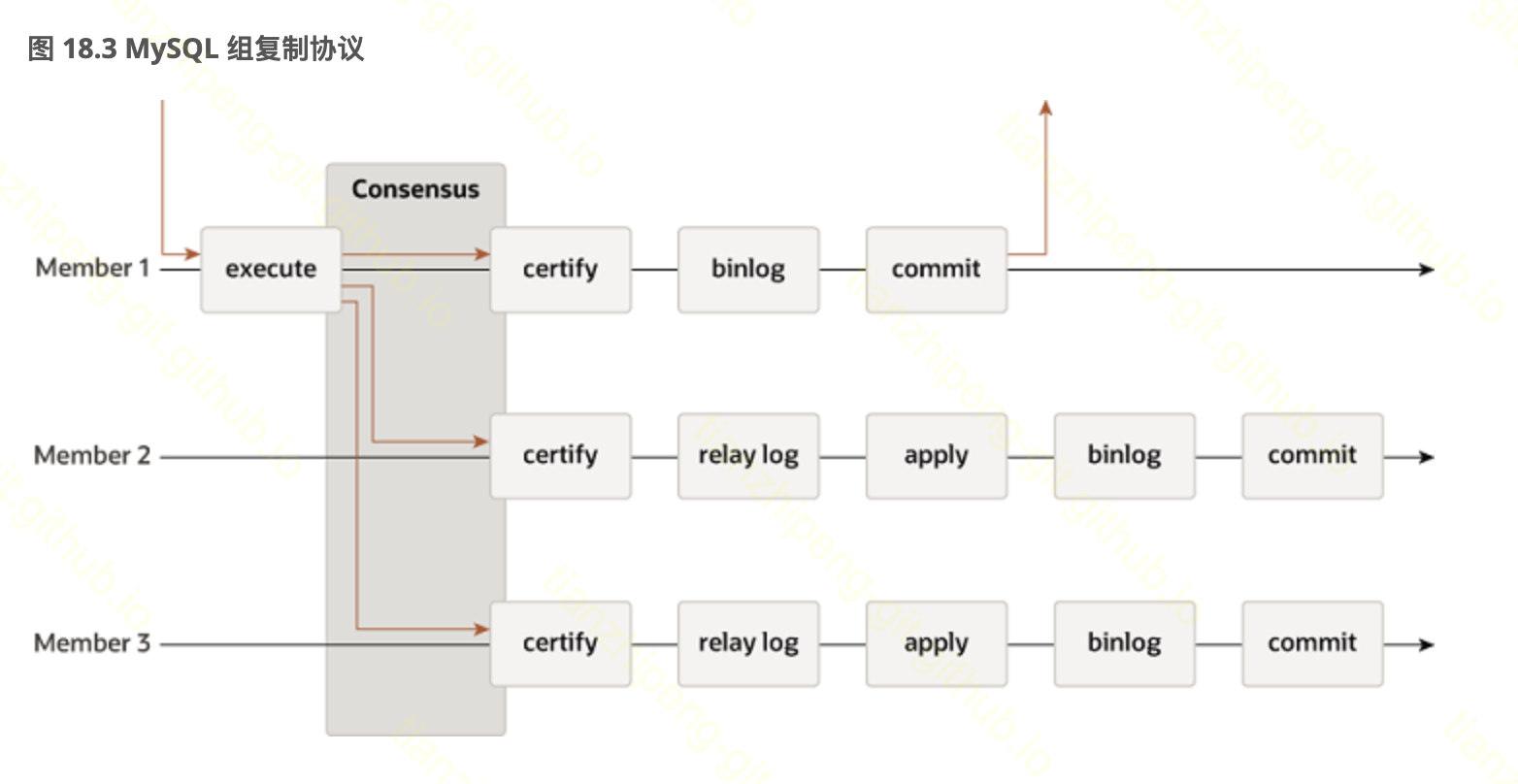
MySQL的GR组复制是多主复制, 通过一致性算法解决冲突问题.
③无主复制
单主复制、多主复制——都是这样的想法:客 户端向一个主库发送写请求,而数据库系统负责将写入复制到其他副本。主库决定写入的顺 序,而从库按相同顺序应用主库的写入.
而无主复制中任何副本都可以直接接受来自客户端的写入, 各副本间角色是平等的.
如图
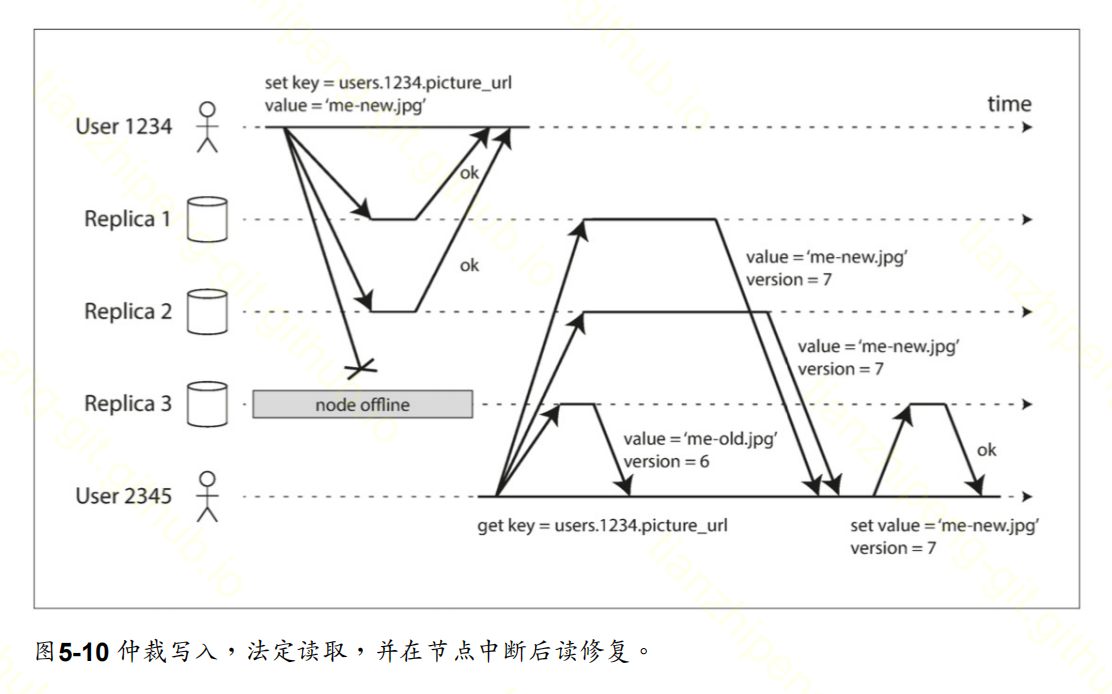
- 客户端负责向所有节点写入数据, 出现有节点故障的时候, 一般只要保证quorum个副本写入成功即可.
- 读取的时候也需要从所有节点读取, 有丢失则进行修复, 称为”读修复”.
- 也可以通过后台进行定期修复缺失的数据, 称为”反熵过程”.
可以看出, 法定人数的设计需要精心计算(书中有一些内容, 我没读懂).
无主并发写入
上述法定人数的设计, 一般情况下没啥问题, 但是如果多个客户端同时写入相同的Key, 会导致冲突, 不同执行的顺序导致不同的结果.
解决这个问题, 类似上述多主复制中的冲突的解决方案, 此外书中还提到一些额外的方案, TODO:
- 最后写入胜利(LWW)(丢弃并发写入)
- 版本向量
参考
- DDIA
- HDFS写过程 博客
- MySQL Replication
- MySQL Group Replication(GR)
- HDFS写操作
- HDFS写ack队列
- HBase写操作和复制, 原文是mapr博客文章”An In-Depth Look at the HBase Architecture“已经挂了. 还好我印象笔记保存了一个链接
- Kafka ack机制
题外话
MySQL的复制, 经历了:
- 主从复制同步 –>
- 半同步 –>
- 并行复制 –>
- NDB –>
- Galera(三方的) –>
- MyCat等(国内搞的) –>
- MGR
从MySQL复制的发展历程和它的文档中可以学到很多. MySQL的复制/集群一直是他的弱项, 除了几家大型互联网公司会运维大型MySQL集群, 这也是PG等其他关系型数据库抢占MySQL份额原因之一, 对比其他关系型数据库应该会学到更多(我只熟悉MySQL…)
博客目前34篇文章了, 18/19/20三年平均每年8篇, 21年只有2篇(离职), 22年无!!! (22年一顿忙, 还啥也没得到, 也没啥提高, 笑)