分布式训练原理 - spark-mllib传统模型

介绍分布式机器学习的基本流程, 以线性回归和随机森林为例, 研究了spark mllib的实现原理, 对比了参数服务器和TF的实现差异.
本篇只关注传统的, 非深度学习的模型的一些分布式执行原理, 对于深度学习/图像语言类的模型还不涉及. 另外全文不涉及任何一个数学公式, 主打的就是做工程的同学对模型的粗浅理解.
模型基本概念
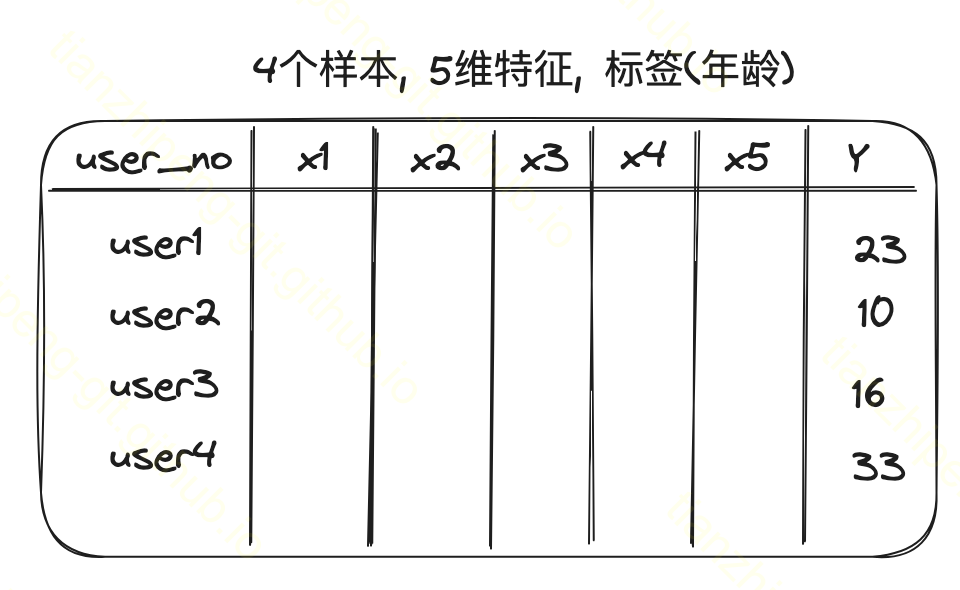
在一个基本的机器学习问题中, 我们面对的数据, 简化来讲就是这样,
- 有4条数据实例, instance, 或者说4个样本.
-
每个样本有m个特征列, 有1个标签列
这些特征列和标签列可能是离散的或者连续的
分类问题的话标签Y就是012这种离散的, 回归问题的话Y就是具体的连续的数值, 比如我图中例子来讲我们要预测一个用户的年龄
我们要根据这样的数据训练出模型, 那模型是个什么东西呢?
我总结模型就是 一个特定的结构 + 结构中的参数
接下来以两种最简单的机器学习算法进行举例说明, 稍后会介绍如何分布式训练这两个模型.
线性回归
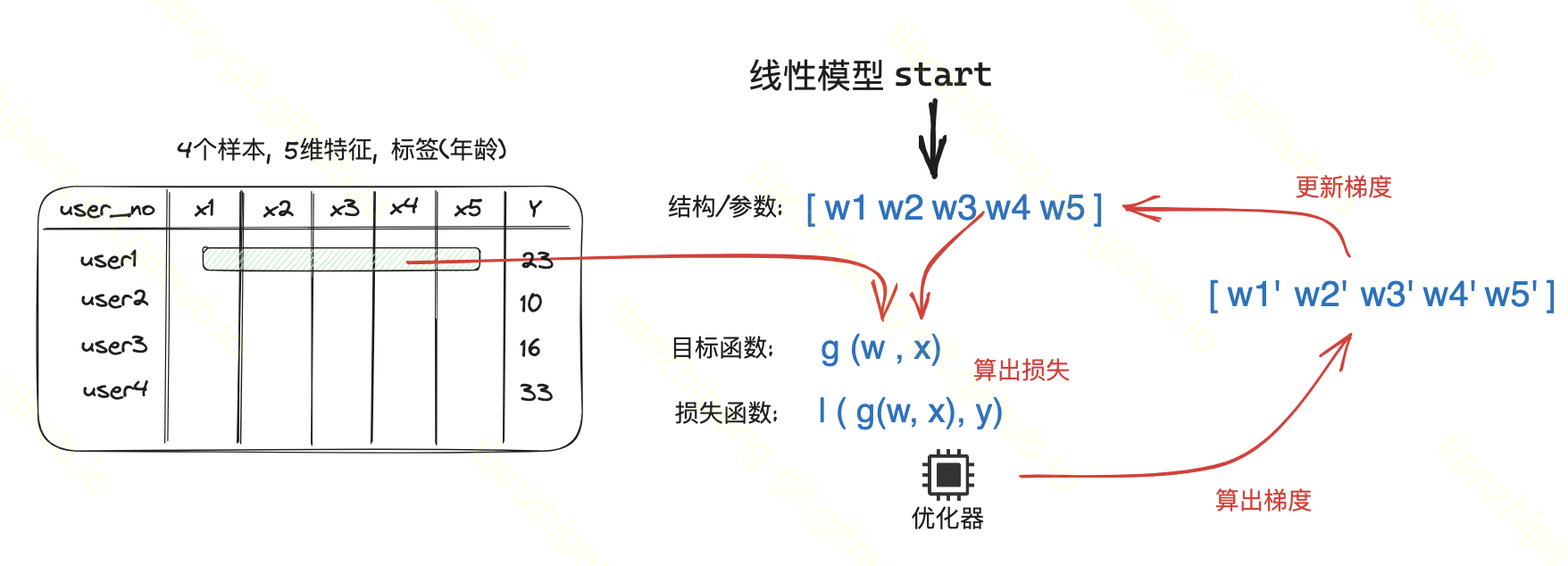
这里我画了一个线性回归单机训练过程的示意图.
对于线性回归模型, 它的模型结构很简单, 就是一个权重向量, 变量x的系数. 模型参数就这这些权重.(后面行文中参数和权重一直在混用).
训练过程
实际训练过程就是为了学习到更好的权重值.
权重向量随机初始化- 把样本的5个特征和权重向量代入
目标函数, 这个就是当前模型对于这个样本的一个预测的Y的值 - 我们根据随机初始化的向量算出来的Y, 肯定和真实Y相差很大, 这里有另一个公式, 用于评估这个效果到底多好多差, 称为
损失函数 - 为了效果更好, 我们使用优化器(比如传说中的
梯度下降), 去算出一组梯度来, 这个梯度就是对上面权重向量的调整值, 一个delta, 拿他去更新权重. (拿梯度更新过后的权重, 按理来讲会预测的更准了)
如此迭代, 就是线性模型的训练过程了.
决策树
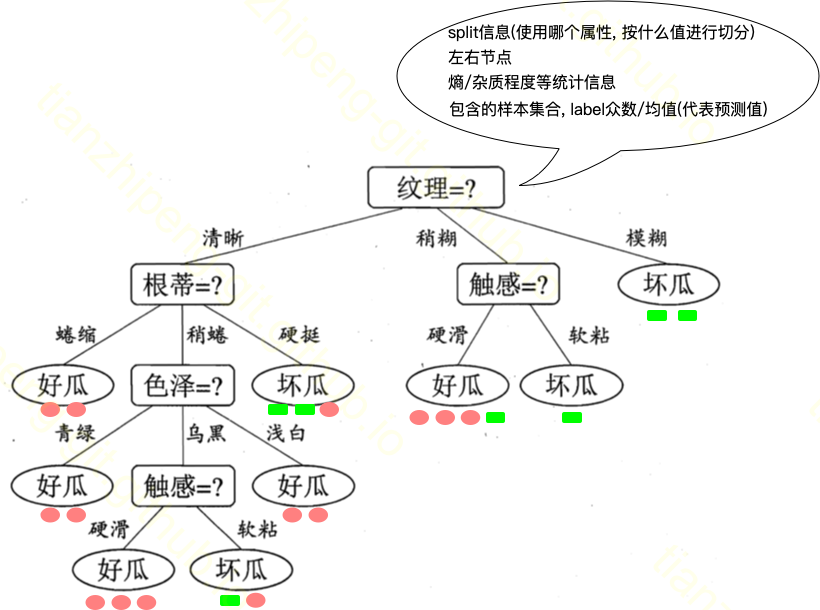
ok, 接下来我们看一下决策树和随机森林. 对于决策树这个模型来讲, 它的模型结构就是一个这样的树形的结构, 每个节点上会保存一些模型参数, 整个样本集会根据特征值分组, 落在树的叶子节点中. 上图是西瓜书里西瓜分类模型的示意图.
节点上的信息包括:
- split信息(按照那个特征属性, 什么值进行划分的) 比如这个根节点, 它是根据瓜的纹理特征进行划分, 纹理清晰分到左节点, 纹理稍糊分到中间节点, 纹理模糊分到右节点
- 左右节点id
- 熵这个概念稍后介绍
- 对于叶子节点, 它还会记录分到这个叶子的样本的情况. 像图中叶子下面, 红色的标识好瓜样本, 绿色是坏瓜样本. 比如这个叶子最后包含4个样本, 3个好瓜1个坏瓜, 按投票结果来讲这是一个好瓜节点.
这个模型做预测的时候很简单, 拿一个要预测的样本, 根据它属性从根节点往下走, 走到叶子节点就知道它是好瓜坏瓜了.
熵的概念
这个模型准不准, 就在于叶子上样本分得好不好, 或者说从一个节点往下分叉分的好不好, 叶子节点上的样本集合越纯越好.
初始时所有样本不经过分类, 混合在一个集合中, 肯定很混乱, 构建决策树的时候不断把他们划分到各个叶子节点上, 每个叶子节点上的小样本集应该是不那么混乱的集合了.
物理学上用熵来形容混乱程度, 信息论中信息熵是用来度量样本集合纯度最常用的一种指标, 他有个公式可以根据样本中各分类的样本量算出一个熵值.
假设初始情况所有样本不经过分类混合在一起的时候熵是100
- 经过A分组方案, 分组后各组加权平均的熵是10, 那么熵减少了100, 是一个不错的方案.
- 经过B分组方案, 分组后各组加权平均的熵是50, 那么熵减少了50, 就不如上面A方案.
这个熵减也称为信息增益. 决策树的构建核心就是在每个分叉的时候评估最佳分组方案, 即选一个信息增益最大的方案.
训练过程
这里模型的训练过程=树的构建过程:
- 从一个空的树开始, 接下来我们要创建节点, 节点是用来把样本进行一个分组的. (可以二叉, 也可以多叉).
-
分组方案或者叫split方案, 就是当前可以选择哪个特征做这个分组, 这个特征下我用什么阈值做这个分组, 肯定有很多种方案.
比如像图中, 可以按照
纹理,触感,色泽等属性来分, 每个属性又有多少具体的阈值划分方案.离散的特征和连续的特征都能产生多种划分方案, 各有具体方法.
- 评估这些方案在当前样本上的好坏(算信息增益)
- 选用最好的一个方案, 分叉
递归进行树的分叉操作. 直到某些终止条件(最大的树深度, 最大节点数量, 信息增益的阈值等等)
可以看出, 这个决策树模型, 不像线性回归那样有一组权重数值要不断去调整, 他就是一个建树的过程; 他内部也不像线性回归那样存的是线性回归公式中的权重, 而是一些树节点的信息.
随机森林
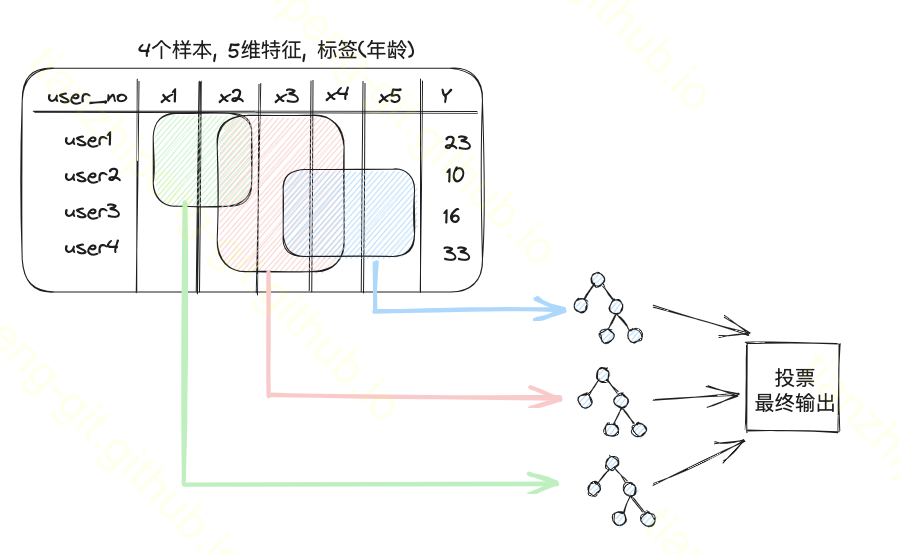
随机森林就是多棵决策树的集成模型, 能够解决决策树过拟合的问题.
他的随机就体现在随机取部分样本, 随机取部分特征来构建多棵树(我的理解是这样的, 每棵树在样本的横向和竖向都只随机取一部分).
最终模型的预测就是多棵树投票结果
为什么在这介绍了线性回归和随机森林呢, 因为接下来会详细分解他们在分布式环境下怎么训练, 大家稍等.
分布式训练核心流程
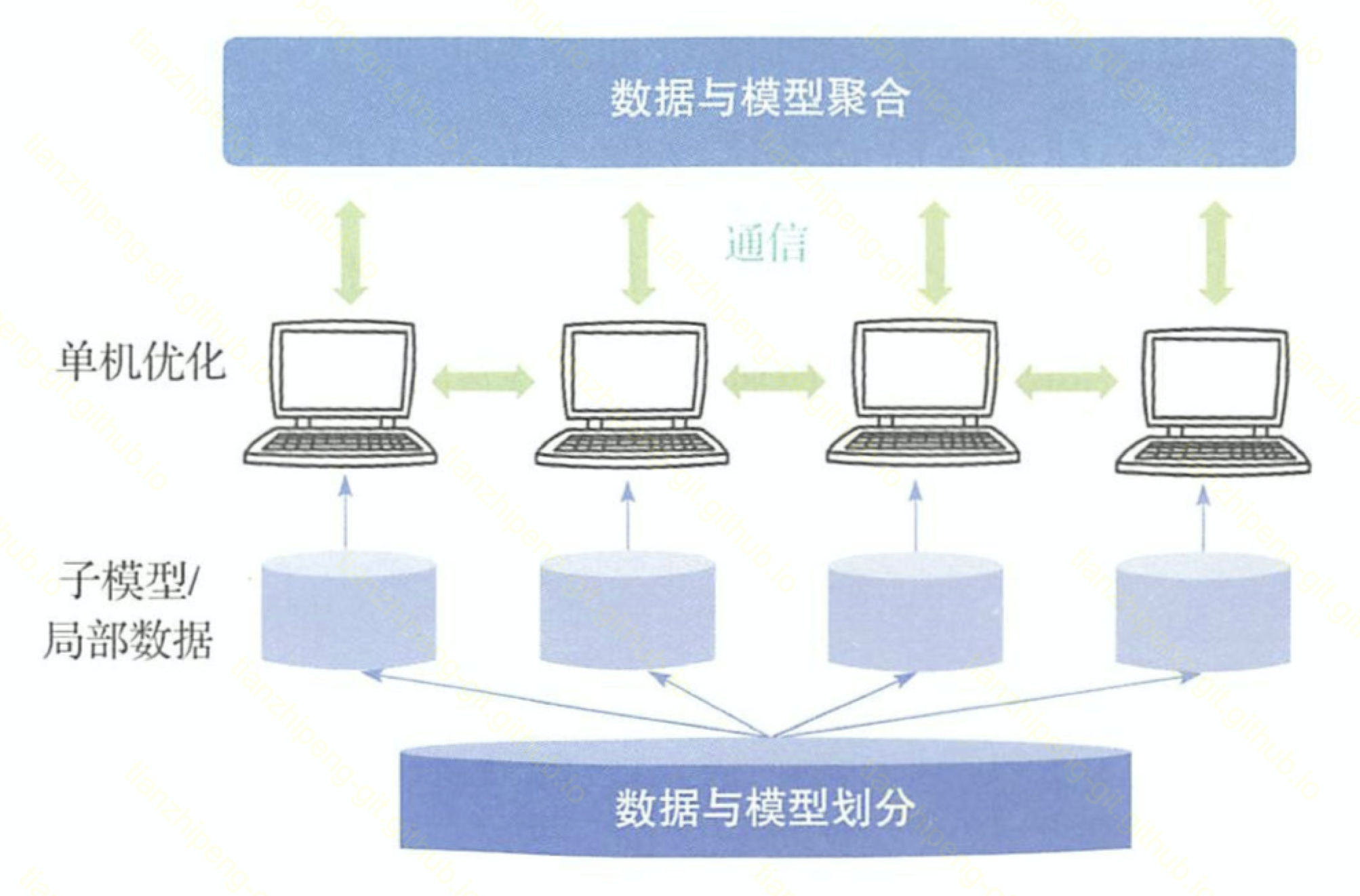
这里步入正题, 我们看分布式训练的核心流程. 其实模型训练也是对数据的处理, 所有对数据的处理都离不开映射规约的思想.
整个流程是4个关键步骤:
- 划分
- 单机计算
- 通信
- 聚合计算
和mr太像了, 当然实际上大部分机器学习不是一轮计算就够了, 上述聚合计算后, 基本还要经过通信后再进行单机计算, 不断迭代.
数据划分和模型划分接下来我们会重点讨论.
单机计算 和 聚合计算部分的难点在于算法改造, 本来是一个公式直接算的, 现在要拆成两段. 将单机算法拆成分布式算法是核心, 下面会讲两个例子.
通信部分内容也很多, 通信的方案, 通信的拓扑结构等也十分关键, 本篇不涉及.
划分和并行
重点聊一下怎么划分
数据并行
数据划分, 数据并行, 是最自然的方案. 我们各种大数据计算/大数据存储, 无一不是将数据按照一定规则分配到不同节点上, 不管叫做分区/分桶还是分片, 思想都差不多. 但是分布式模型训练和大数据中的分区又稍有不同.
我们将模型训练中的数据并行模式又分为两种:
- 样本划分(横着切): 工作节点依据各自分配的局部数据对模型进行训练
- 维度划分(竖着切): 对数据按照特征维度进行划分, 每个节点只负责部分维度
模型并行
分布式模型训练中另一种划分方式叫模型划分或模型并行, 就是根据模型结构不同, 将模型的不同部分交给不同的节点来完成训练.
模型并行模式:
-
维度划分的同时, 参数也跟着划分.
注意到上述数据维度划分的时候, 其实模型也可以跟着特征一起划分, 比如线性模型的参数和特征维度是一一对应的, 拆到不同节点负责倒也没问题, 但就是没啥意义(算损失/算梯度的时候还少不了一堆通信)
- 模型内部可分: 如随机森林, 可以一个节点训练一棵树
-
深度模型: 按层划分/跨层划分
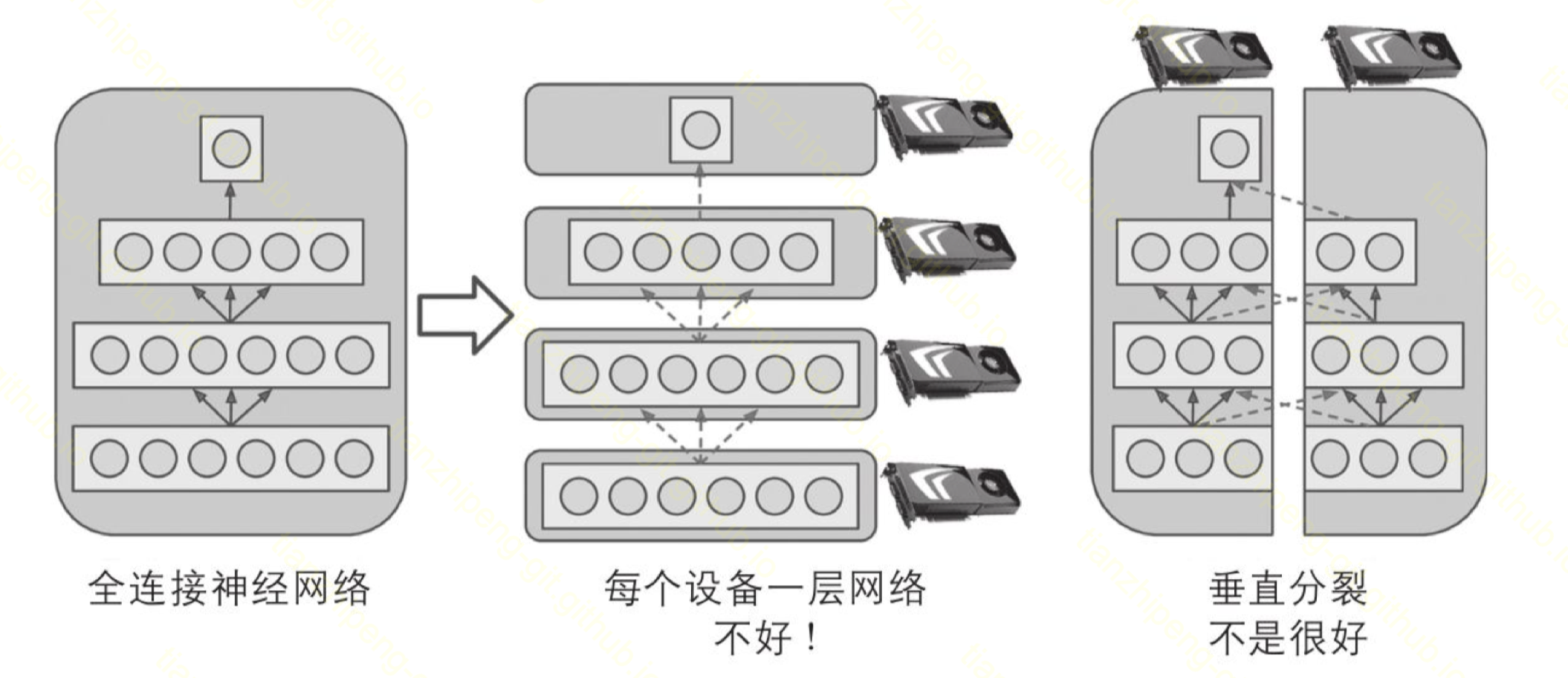
计算并行
工作节点共享一块公共内存 (例如单机多线程/单机多卡), 本质上就是上述两种模式的本地化特例, 我觉得不需要单独讨论
分布式训练框架-Spark MLlib
接下来我们结合上述分布式训练流程, 以及线性回归和随机森林两种模型的单机流程, 对比其在分布式时是如何训练的.
Spark-MLlib框架-线性回归
训练过程
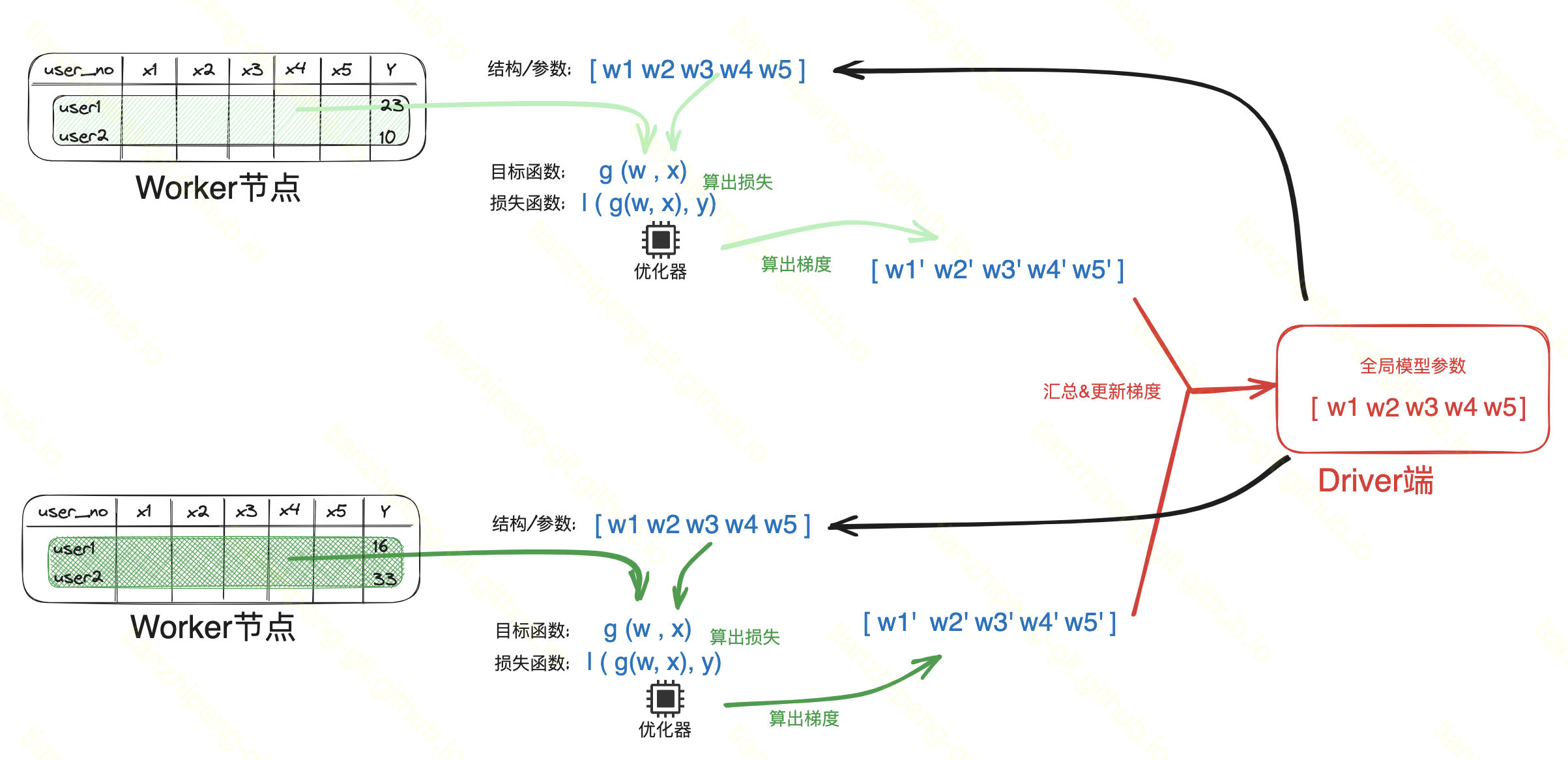
在spark mllib中提供了线性回归的模型, 训练过程如图, 很显然, 采用的是数据并行样本划分的模式.
- 单机计算: 每个区根据样本和当前权重, 计算损失, 单机SGD求解梯度(也涉及局部聚合, 是treeAggregate的reduce优化而已).
- 汇总更新梯度: 将单机梯度reduce到driver端, 汇总计算梯度, 更新全局权重 allreduce通信(treeAggregate算子)
- 广播新权重
不断迭代上述过程调整权重.
可以看出, 节点本地的权重(权重=模型参数)就是driver端全局权重的一个副本而已, 还是靠driver维护完整的模型, 没有做模型划分.
再看另一个书里截的图:
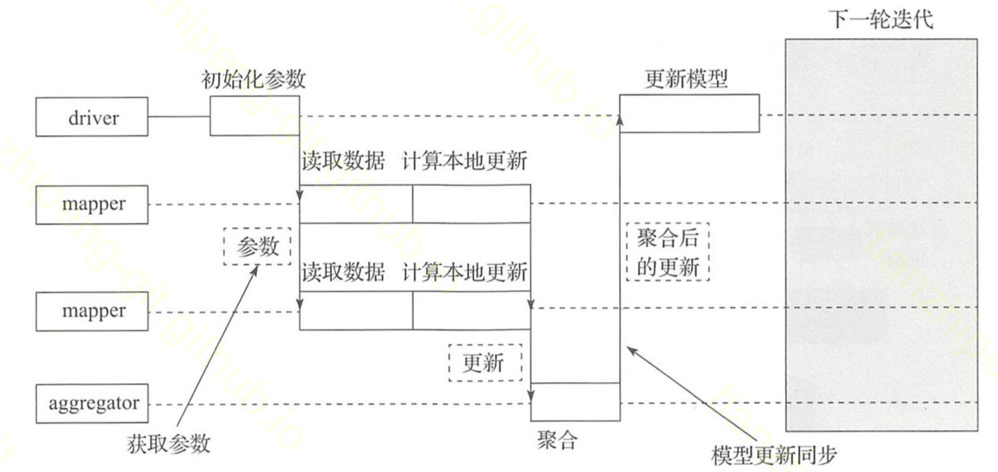
从这个图来看这个过程其实确实就是mr思路.
这个图体现了一个关键的信息在于, 各个mapper都在做本地计算, 即使某个mapper算的特别快, 或者算的特别慢, 都要等待所有mapper计算完, driver更新完了全局权重才能开始下一轮. 这也是spark基于stage的计算模式所决定的.
这是一种同步的梯度下降算法. 对于同步SGD有很多”改进”算法, 比如: 节点有一份本地权重, 和全局权重不是实时一致的, 相当于有个小模型; 再比如: 异步的, 节点不等全局权重更新完了就开始下一轮迭代(spark实现不了)
另外两个细节:
- 单机计算再汇总加和, 能这么做, 是因为从线性模型原理(公式)上讲, 梯度是可以按照样本X可以拆分的, 然后直接加和算出全局的.
- 权重更新还是和单机有区别的, 单机多次迭代, 每次都是算出一份新梯度, 更新一次权重; 分布式时是根据当前权重, 各个节点算出多个梯度一起更新到全局权重上.
源码分析
源码分析:
-
入口类是
org.apache.spark.mllib.classification.LogisticRegressionWithSGD.可以看出这个类被标记为
deprecated, 它从两方面被deprecated: 一方面, spark从基于rdd编写的mllib包, 转向为基于dataframe编写的ml包了. 另一方面, 现在spark中推荐用比SGD更好的LBFGS优化器了 -
核心训练流程在
org.apache.spark.mllib.optimization.GradientDescent类的runMiniBatchSGD方法这里直接借用一位知乎网友的代码分析吧:
while (i <= numIterations) { //迭代次数不超过上限
val bcWeights = data.context.broadcast(weights) //广播模型所有权重参数
val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i)
.treeAggregate(xxxtodo) //各节点采样后计算梯度,通过treeAggregate汇总梯度
val weights = updater.compute(weights, gradientSum / miniBatchSize) //根据梯度更新权重
i += 1 //迭代次数+1
}运行后, spark执行截图:
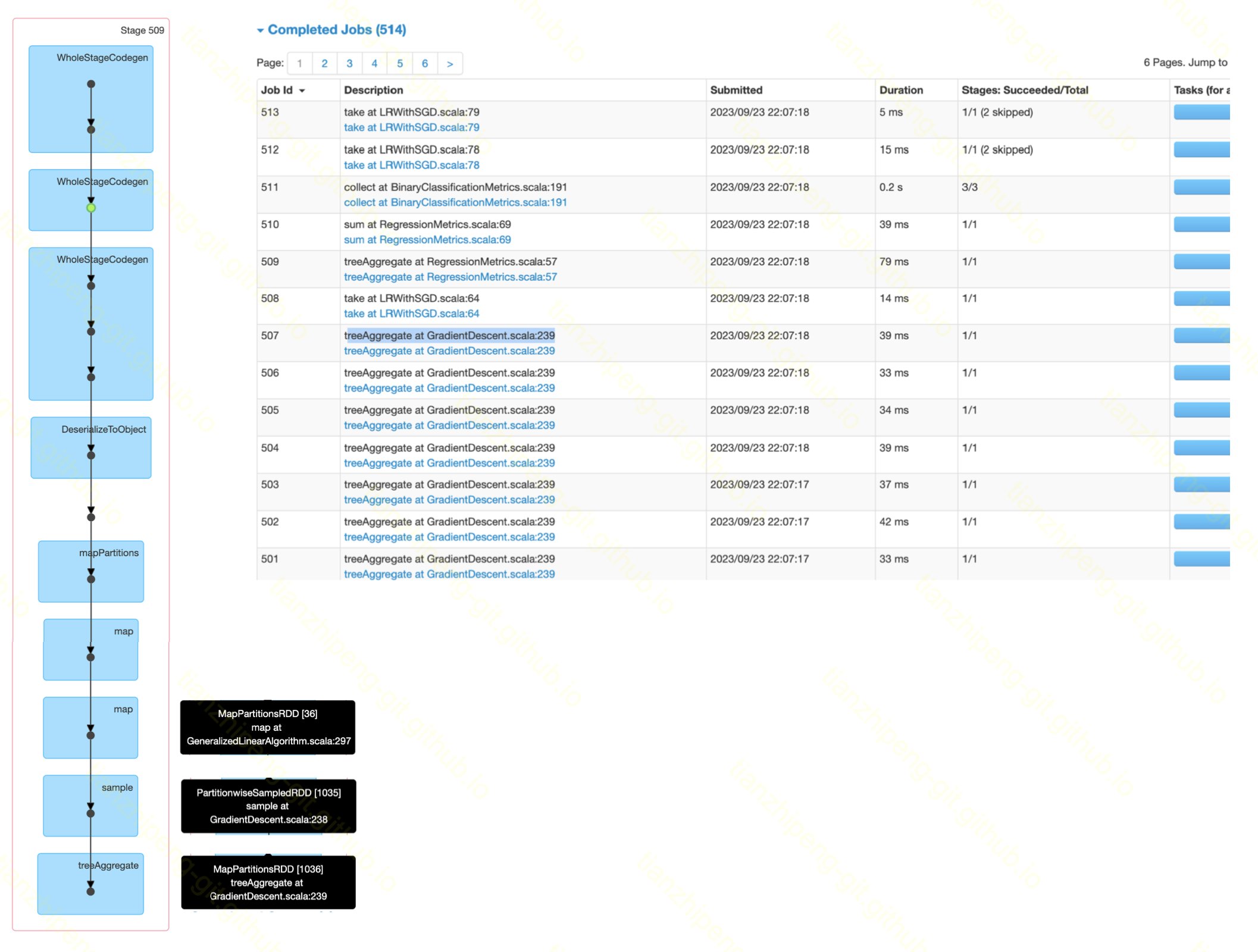
从截图中我们可以看到如下信息:
- job列表那里有很多行
treeAggregate as GradientDescent.java:239的job, 从上面也可以看出总共有五百多个job. 这符合我执行前设定的迭代次数setNumIterations(500) - 从dag图中可以看到有个
sample过程, 这是因为我们用的是spark中的批量随机梯度下降, 每次随机取一点样本算梯度. - 最后聚合是用的
treeAggregate, 他是先局部聚合最终再聚合到driver, 能减轻driver压力.
Spark-MLlib框架-随机森林
训练过程
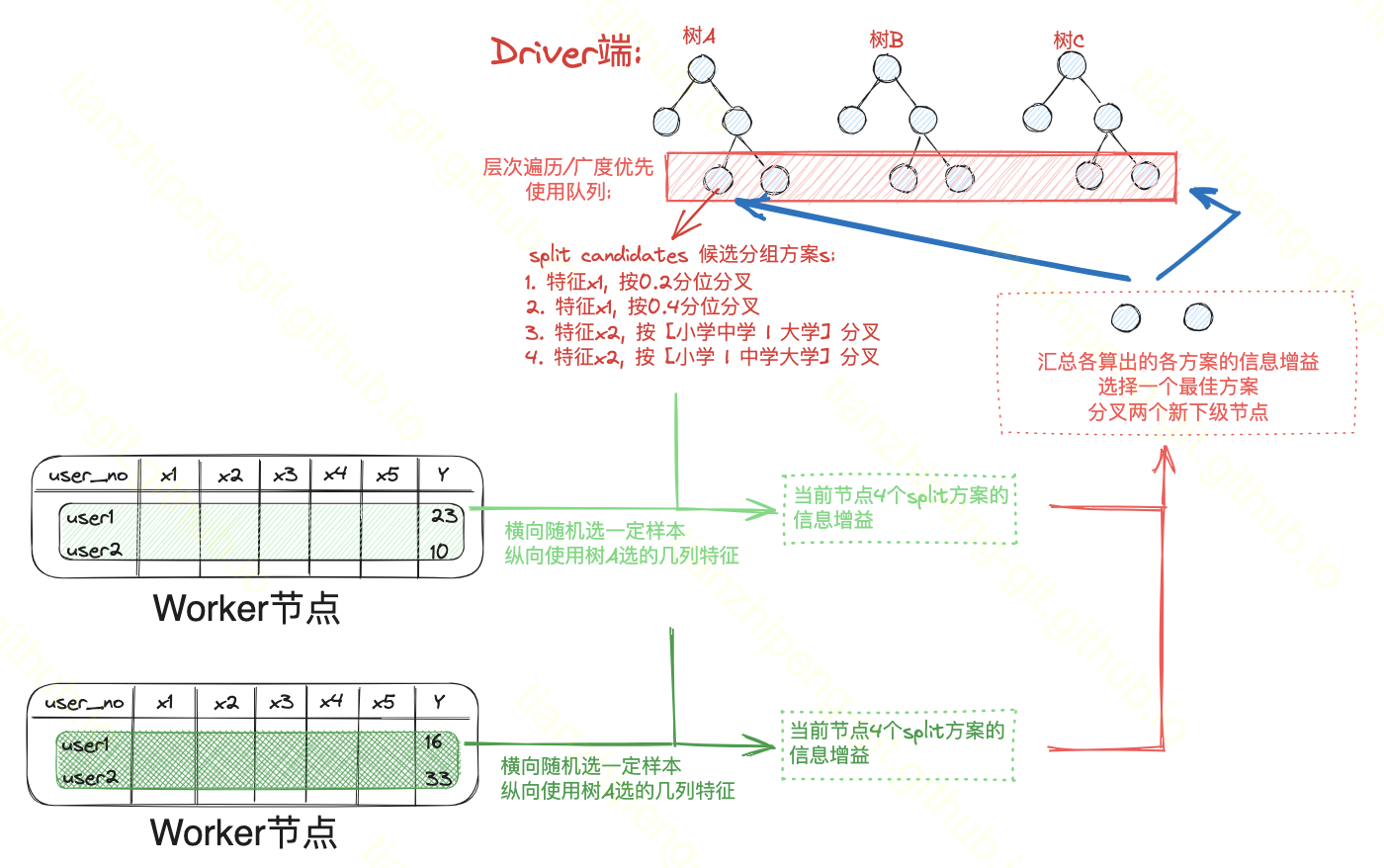
接下来我们看spark如何分布式训练随机森林的. spark中随机森林的实现和我一开始预想的不太一样, 我还以为会是一个节点负责一棵树呢/笑
实际上的他这个实现还是有一些细节在里面的:
- 首先在spark的rdd编程中, 肯定不能有递归的写法, 还好的一点是, 这个建树的递归直接可以改成迭代, 我们用一个队列就可以进行广度优先的迭代建树的写法.
- 还是driver端控制整个过程, 维护所有的树的完整信息.
- 所有树可以一块构建, 反正对于干活的worker来讲, 当前在为哪棵树做分叉都无所谓.
完整流程:
- 初始化所有树的根节点, 进入队列.
- 每次从队列里拿出一个或多个待分裂的节点
- 然后列出他们的候选分组方案
- worker节点干活(算各方案的信息增益)
- 汇总, 选最佳方案, 分叉 (分叉后新生成的两个节点要挂在父节点上, 同时要入队)
循环消费这个队列直到空.
这个训练过程是数据并行样本划分, 维度不算划分. 也不算模型并行, 完整的模型还只是在driver端, worker段只有局部节点信息.
源码分析
入口是org.apache.spark.ml.tree.impl.RandomForest类的run方法:
- 前期准备阶段
//训练前先运行一些统计信息: 样本数, 特征数, 各特征基数, 分类个数等等
val metadata = DecisionTreeMetadata.buildMetadata(retaggedInput, strategy, numTrees, featureSubsetStrategy)
//构建所有树的分叉方案(分叉方案是提前全量构造好的, 不用迭代的时候现处理, 毕竟特征啥情况是固定的; 离散和连续特征的split逻辑是不同的)
val splits = findSplits(retaggedInput, metadata, seed)- 树遍历的准备
//新的spark代码中, 遍历启用queue改用了stack, 那么遍历不算广度优先了, 不影响我们分析.
val nodeStack = new mutable.ArrayStack[(Int, LearningNode)]
//存放随机森林中各树的根节点, 比如设定3棵树, 这个数组长度3.
val topNodes = Array.fill[LearningNode](numTrees)(LearningNode.emptyNode(nodeIndex = 1))
//将所有树的根节点推入栈
Range(0, numTrees).foreach(treeIndex => nodeStack.push((treeIndex, topNodes(treeIndex))))- 迭代建树
while (nodeStack.nonEmpty) {
//选择本轮要处理的节点, 不是一次一个, 是根据内存情况, 一次处理多个. 这些节点可能来自同一棵树, 也可能来自不同树
val (nodesForGroup, treeToNodeToIndexInfo) =
RandomForest.selectNodesToSplit(nodeStack, maxMemoryUsage, metadata, rng)
//评估最佳split方案. 如果确实需要split, 本方法内部会将split出的新节点推入nodeStack
RandomForest.findBestSplits(baggedInput, metadata, topNodesForGroup, nodesForGroup,
treeToNodeToIndexInfo, splits, nodeStack, timer, nodeIdCache)
}-
最佳split方案评估
这是worker主要干活的部分. worker TODO
-
树节点的类
org.apache.spark.ml.tree.LearningNode
var id: Int,
var leftChild: Option[LearningNode],
var rightChild: Option[LearningNode],
var split: Option[Split], //本节点下级分叉方案, 子类CategoricalSplit/ContinuousSplit
var isLeaf: Boolean,
var stats: ImpurityStats //熵值, 样本的分类(预测值)运行后, spark执行截图:
TODO
Spark-MLlib框架-总结
优点:
- 样本划分很方便
- 迭代很方便(IMR). 数据分区不丢弃, cache上再每次迭代上是复用的
- spark框架负责任务调度分配, 高可用保障等
缺点:
- 只能用单一driver, 性能瓶颈问题
- 只能做数据划分, 无数据不task
- 通信手段单一: shuffle和broadcast
- 编程模型较固定:
- stage和shuffle决定, 交换数据方式有限: shuffle的话原来的数据就没了
- 大家都得在同一个阶段, 执行相同的事情, 不能分角色扮演.
- 同步, 每轮迭代都得等全局参数算好; 在spark实现不了异步的优化算法
分布式训练框架-Parameter server
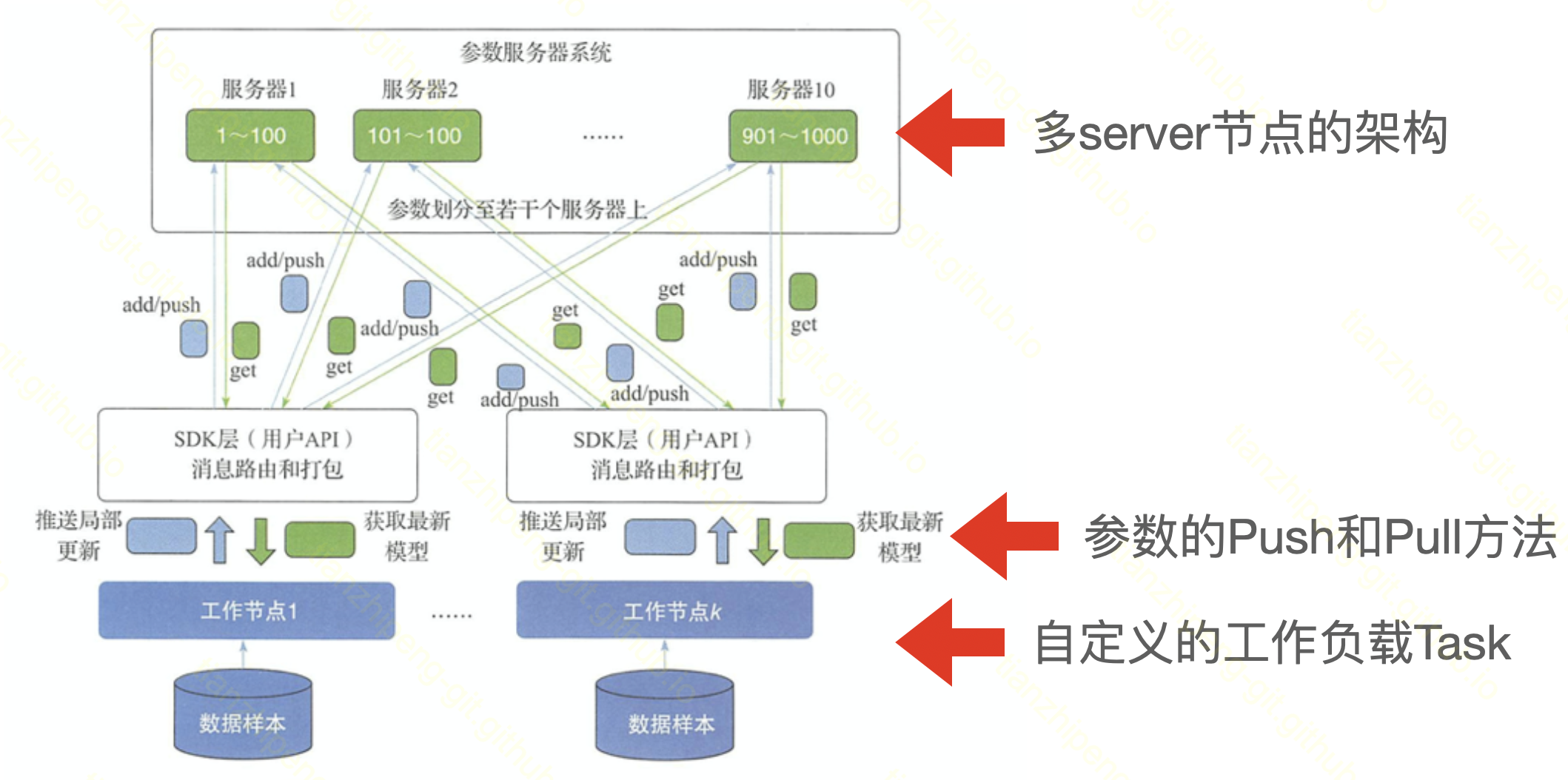
针对spark这种IMR分布训练的缺点, 大佬们设计了一种参数服务器的方案.
-
多个节点的组成的参数服务器集群, 类比为redis集群(一致性哈希), 但是他这个server不只是纯负责存储, 还要负责汇总计算.
还记得之前说分布式训练流程中, 要单机计算, 通信, 然后汇总计算吧. 这个PS server要参与计算的.
- 抽象了worker节点和PS server之间的两种通信原语,
PUSH参数和PULL参数. 具体何时PUSH/PULL, 是worker节点上task灵活自定义的. - worker节点上执行的task负载, 是灵活定义的, 或者说要自己开发的.
优点:
- 实现多server节点的架构,避免了单master节点带来的带宽瓶颈和内存瓶颈;
- worker自定义, 非常灵活
- 可以应用一些异步的梯度下降策略
缺点:
- 只提供了简单的server服务和push/pull原语, 其他的如算法逻辑, 任务调度什么的得自己实现
- 更多的是像一种思想, 很少单独出现使用了(搜到的
ps-lite项目文档和资料极少,Multiverso已经不维护了), 都在用TensorFlow这种集成框架 - m*n的通信, 可能成为瓶颈
分布式训练框架-TensorFlow
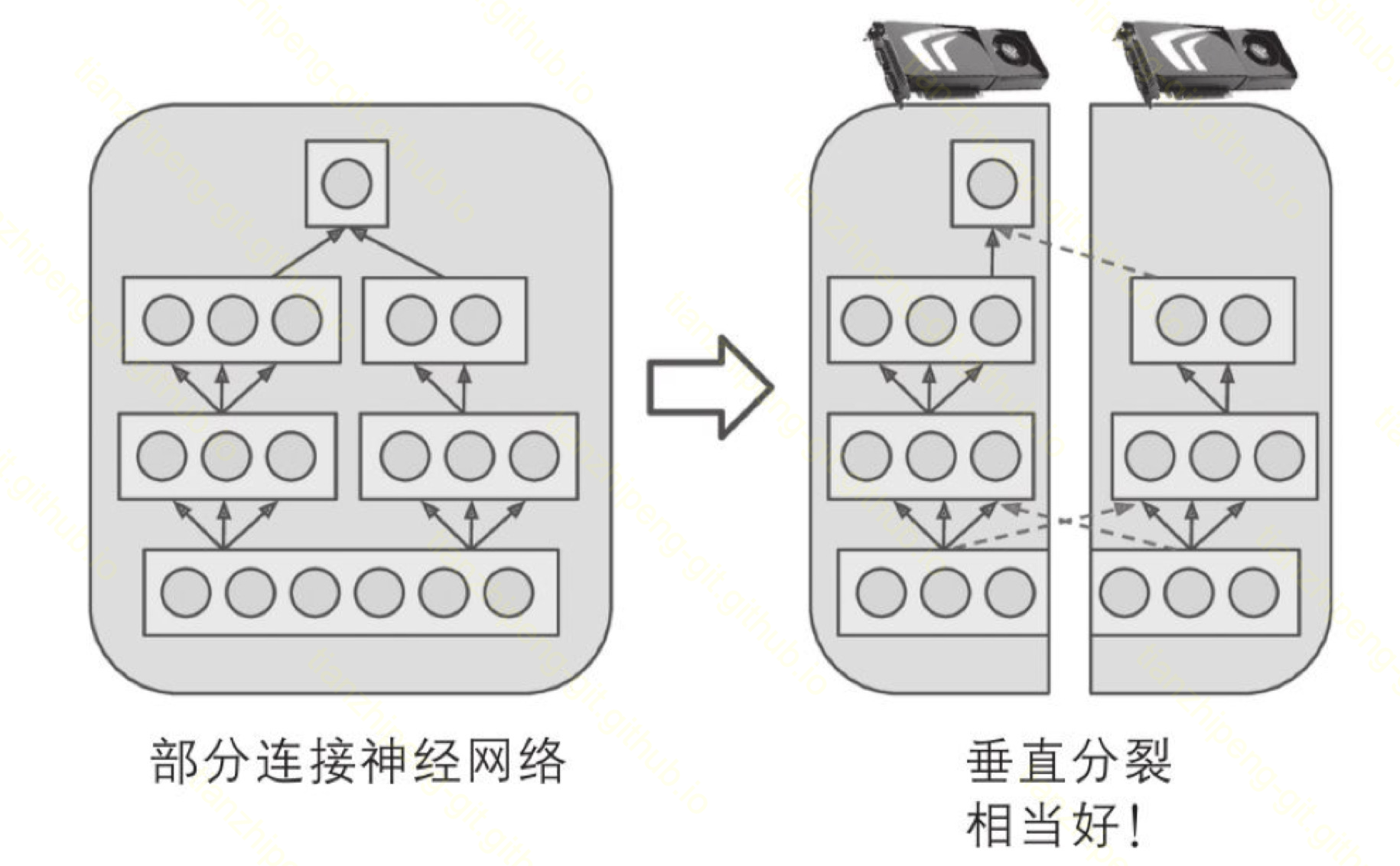
TensorFlow这块难度比较高, 他相当于把之前那些内容的集大成者, 我暂时还没看完, 留着接下来学习吧. TODO
基于计算图的任务安排:
- 不像spark的task那种死板, 可以安排不同的task
- 单机多卡, 多机并行, 灵活定义
- 划分层面: 数据划分/维度划分/模型划分都能做
- 通信层面: 可以基于PS, 可以Allreduce; 同步式/异步式
根据tf.distribute.Strategy及相关文档可以了解有关内容.
总结
为啥实践中很少用?
- 数据划分, 只有样本量特别大或者特征维度特别大才有必要, 我们好像没有.
- 模型划分之类的实现难度还比较大
- 大部分算法不能无痛改成分布式的, 有成本(coding成本, 效果成本等)
-
不是很成熟, 多机训练带来的增益, 甚至弥补不了网络传输和模型效果的代价; 1 + 1 < 2
单块强大的GPU卡 > 单机多块卡 > 多台机器
参考资料
- «分布式机器学习:算法、理论与实践»
- «Spark机器学习»
- «Scaling Distributed Machine Learning with the Parameter Server»
- «SPARK MLLIB机器学习 算法、源码及实战详解»
- spark angel tensorflow官方文档及源码