spark硬核优化3 多表join/多路全连接优化

分享记录几个在实际工作中解决的几个硬核spark优化的case, 所谓硬核就是不是简单的改改sql/调调配置就能解决的, 需要深入spark内部原理, 修改/扩展spark源码才能实现的优化. 这个是第三篇, 实现一种多个输入/多个表进行join的功能.
超长预警…
背景
在实际工作中, 常常遇到将多个表连续join的功能, 没啥复杂的逻辑, 就是需要将多个表整合. 例如我们实际的广告业务中, 经常用设备ID作为主键进行分析建模等, 假设有N个设备ID为主键的表, 每个里面都是各种设备的特征/画像等数据.
正常直接多个表进行full join就行(当从业务角度能确定, 某一个表能覆盖其他表的所有主键时, 用left join更好), 但当每个表数据量级都是几十亿的时候, 或者连续join表很多的时候, 观察到执行速度比想象的慢很多, 观察其执行计划也不够优化.
这里仅以这个场景为例, 设计实现一种多个输入/多个表进行full join的功能.
问题思考
原始join的问题
先尝试构建复现问题的用例, t1/t2/t3/t4是要join的4个表, 有如下sql代码
SELECT coalesce(t1.device_id,t2.device_id,t3.device_id,t4.device_id) AS device_id
,t1_metric1
,t2_metric1
,t3_metric1
,t4_metric1
FROM
t1
FULL OUTER JOIN t2 ON t1.device_id = t2.device_id
FULL OUTER JOIN t3 ON t1.device_id = t3.device_id
FULL OUTER JOIN t4 ON t1.device_id = t4.device_id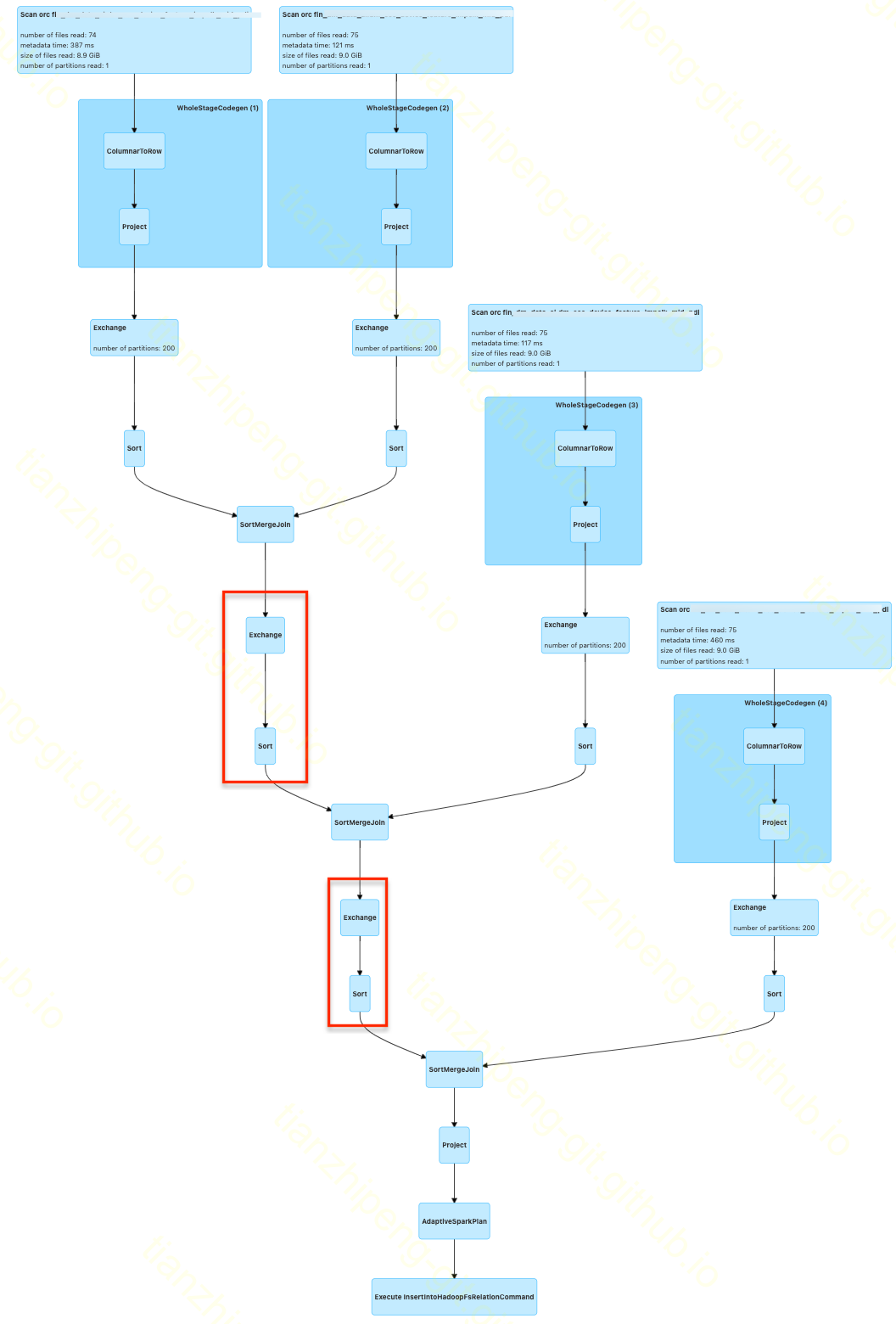
这段代码的执行计划如图, 可以看出
1. 无论join语句怎么写, 实际数据都是两两join的, 原始的join就只支持两两join
2. 整个join都是采用的SortMergeJoin来进行的, 这也符合我们的场景, 各个数据都是几亿几十亿量级, 不可能用哈希广播之类的Join方案.
3. 两两Join的结果再和第三个数据Join前, 多了一组Exchange和Sort操作(图中红框的部分), 这是我们不期望的
背景知识
Exchange和Sort是Spark物理计划执行前自动加入的, Spark会根据每个物理Exec以下几个信息进行判断:
- requiredChildOrdering 本算子要求子节点的数据排序
- requiredChildDistribution 本算子要求子节点的数据分布
- outputPartitioning 本算子输出数据的分布
- outputOrdering 本算子输出数据的排序
对SortMergeJoinExec而言, 很显然, 它要求子节点的数据, 按照等值关联键进行哈希分区, 同时要求子节点的数据按照关联键进行排序, 然后SortMergeJoinExec内部在分区排序好的输入基础上做的归并.
所以从文件来的输入(即Scan下面)接的Exchange和Sort是必要的, Spark判断Joinxec所要求的分区排序没有满足, 自动加入Exchange和Sort来处理.
但是Spark认为FullOuterJoin的情况下, JoinExec的输出是无分区, 无排序的! 所以Join之后的输出要再进行Join, 就又加入了红框部分的Exchange和Sort, 从我们这个业务角度, 这个是不需要的.
4.另外一点, 整个执行计划DAG是一个倾斜的二叉树, 执行起来类似串行的, 必须两两join完第三个才能加入进来, 整体并行度不够
关于sql join的写法
如果你注意到我上面sql join的写法, 可能会想到还有下面这种两个表join并命名新临时表 -> coalesce字段 -> 再join的嵌套写法
这个和上述连续join在执行计划上看几乎没有区别(多个几个Project算子而已).
SELECT coalesce(t123.device_id ,t4.device_id) AS device_id
,t1_metric1
,t2_metric1
,t3_metric1
,t4_metric1
FROM
(
SELECT coalesce(t12.device_id ,t3.device_id) AS device_id
,t1_metric1
,t2_metric1
,t3_metric1
FROM
(
SELECT coalesce(t1.device_id ,t2.device_id) AS device_id
,t1_metric1
,t2_metric1
FROM t1
FULL OUTER JOIN t2
ON t1.device_id = t2.device_id
) t12
FULL OUTER JOIN t3
ON t12.device_id = t3.device_id
) t123
FULL OUTER JOIN t4
ON t123.device_id = t4.device_id但是, 差点在这被坑, 但是, 这种写法, 和上述连续full join都join在t1的key上, 执行结果是有区别的, 举例来说
t1:
key1
key2
t2:
key3
t3:
key3
t4:
key3这个数据, 用上面的sql进行join结果是5行(key3有3行)!! 用这段多次coalesce的语句, 执行结果是3行(key3有1行)!!
其实我们的实际业务需求, 是这种写法的结果, 所以我的实现也是这种逻辑的. (看这代码长度都让人不爽)
小优化1
其实在做这次优化前, 对这个多表连续join做过一个小的优化方案, 对于上述join的问题4, 就是倾斜二叉树/并行度不够的问题, 可以修改sql语句使其DAG变成完全二叉 树. 伪代码示意一下:
(
t1 FULL OUTER JOIN t2
) t12
FULL OUTER JOIN
(
t3 FULL OUTER JOIN t4
) t34可以看出通过额外加一些括号, 将执行计划变成完全二叉树的样子, 这种方法不会使整体执行内容变少, 只不过改变执行顺序/并行度.
优化方案
我优化的思路就是直接开发一个新的Join执行计划, 支持多个input, 好处一个是不需要两两join的串行等待, 二是不需要额外的Exchange和Sort了.
- 首先这是一个特殊的功能, 不打算扩展到sql语言中使用(实际还不了解spark的sql解析这一块), 只在dataframe上使用就够了, 借助通过LogicalPlan构造Dataset的功能作为入口:
val x = MyFullJoin(inputs.map(x => (x._1.queryExecution.analyzed, x._1(x._2).expr)))
new Dataset[Row](spark, x, RowEncoder(x.schema))
- 构建MyFullJoin逻辑算子和负责解析这个逻辑算子的Strategy
case class MyFullJoin(inputs: List[(LogicalPlan, Expression)]) extends LogicalPlan
object MyFullJoinStrategy extends Strategy {
override def apply(plan: LogicalPlan): scala.Seq[SparkPlan] = plan match {
case p: MyFullJoin => {
Seq(MyFullJoinExec(p.inputs.map(x => (planLater(x._1), x._2))))
}
case _ => Nil
}
}
spark.experimental.extraStrategies = Seq(MyFullJoinStrategy)
- 参考SortMergeJoinExec, 编写自己的MyFullJoinExec, 下面详细介绍.
MyFullJoinExec
对spark-sql的物理节点, 首先要定义输入和输出的情况, 实现如前所述的requiredChildOrdering, outputOrdering等几个方法.
然后实现核心的doExecute方法, 根据自己的下级物理节点(SparkPlan), 构造自己的输出数据, 输出的是一个新RDD[InternalRow]. 一般doExecute内部, 都要借助RDD上的各种transform算子来实现自己的逻辑, 我这个Join, 仿照原始的SMJ逻辑, 用的是zipPartitions算子:
rdd0.zipPartitions(rdds(0), rdds(1), rdds(2))((i0, i1, i2, i3) => { // fixme zipPartitions至多支持4个输入
val iterators = Seq(i0, i1, i2, i3).map(RowIterator.fromScala)
new FullOuterIterator(iterators, keyOrdering, keyGenerators,
nullRows, resultProj, numOutputRows).toScala
})zipPartitions将多个RDD按照相同分区号进行并联处理, 接受一个Function(输入4个Iterator, 输出1个Iterator).
FullOuterIterator
FullOuterIterator是自定义的Iterator, advanceNext是他的入口类, spark框架会调用这个方法获取下一行数据.
因为要返回多个输入join之后的数据, 所以原来的JoinedRow类不够使用, 新开发一个class MultiJoinedRow(val rows: Array[InternalRow]) extends InternalRow, 内部用数组存放join的多个输入row, 取数据的时候, 根据索引去对应row里取.
因为输入的多个Iterator是已经排好顺序的, 所以FullOuterIterator的执行逻辑也很简化了:
override def advanceNext(): Boolean = {
// 如果buffer中已有数据
if (scanNextInBuffered()) {
return true
}
//获取下一个最小key, 如果所有输入都到头了, 则是null
val minKey = findMinKey()
if (minKey != null) {
//将符合这个key的都遍历出来放到buffer中
findMatchingRows(minKey)
//从buffer中取出next
scanNextInBuffered()
true
} else {
false
}
}画了个示意图:
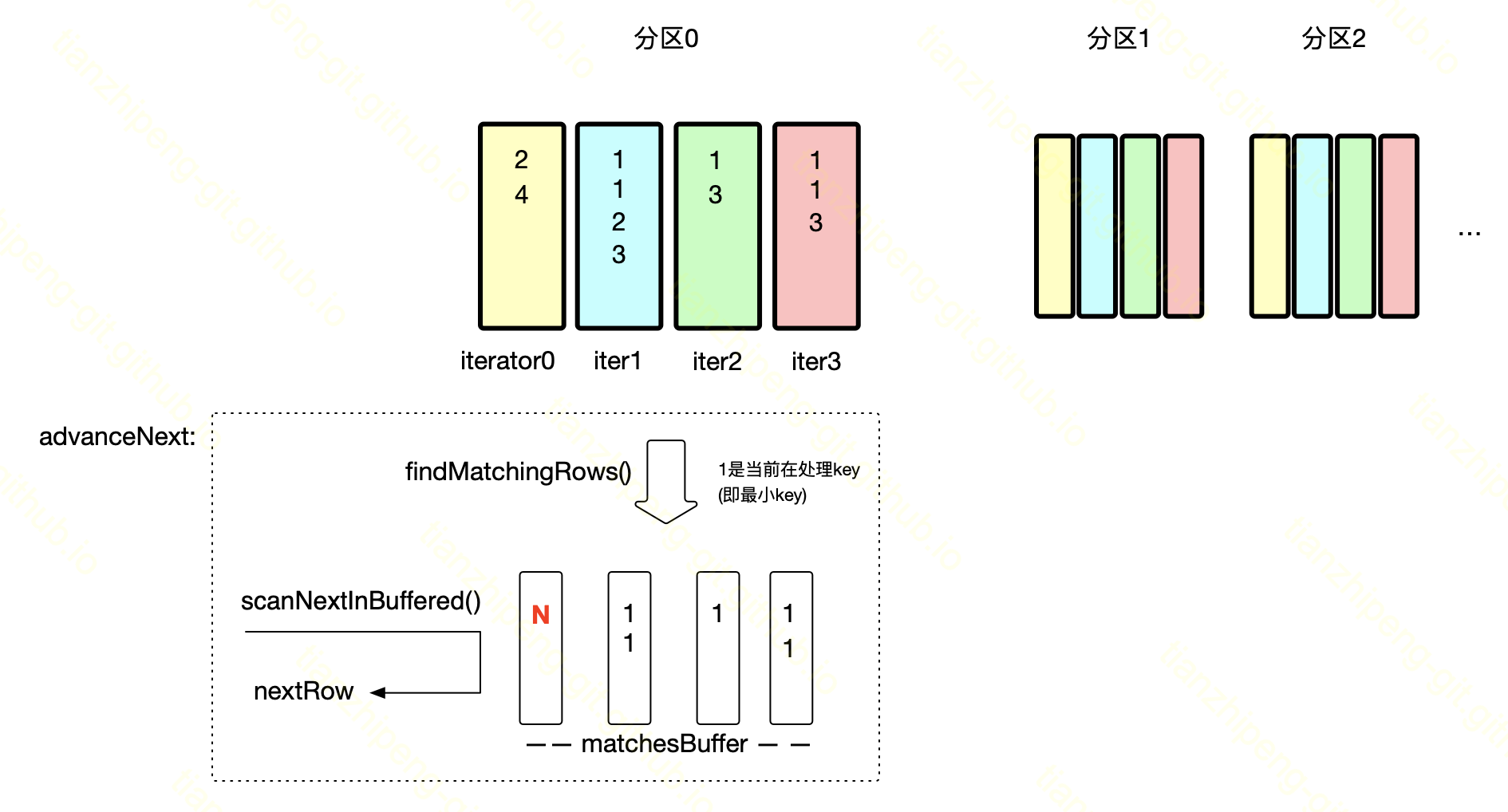
- 找到当前要处理最小key, 如1
-
将所有Iterator不断next直到不是这个key, 将从个Iterator得到的行, 分别放在对应matchesBuffer中
注意, 因为是FullJoin, 某一个输入没匹配到任何行(图中黄色那个输入没有1) 最终结果也要有, 这里的设计是将一个nullRow放到对应buffer(红色的N)
-
因为最终是迭代器, 而不是将buffer里的结果行一股脑丢出去, 所以要根据buffer一条一条返回数据, 迭代器效果
一种简单方案是为每个buffer额外保存一个当前输出位置的index, advanceNext时根据4个index从matchesBuffer中取即可.
但是借助scala和chatGpt强大的能力, 给了我一种贼精简但是不好懂的代码!
cartesianProduct
因为最终输出其实就是4个buffer的元素进行笛卡尔组合(图中例子是121*2 输出4中row的组合来), 所以让gpt帮忙生成N个数组的元素进行笛卡尔组合的代码, 要求它返回迭代器.
1 def cartesianProduct[T](xs: Seq[Iterable[T]]): Iterator[Seq[T]] = {
2 xs match {
3 case Seq() => Iterator(Seq())
4 case Seq(h, t@_*) => for {
5 i <- h.iterator
6 rest <- cartesianProduct(t)
7 } yield Seq(i) ++ rest
8 }
9 }- 3行 递归跳出条件; 如果输入xs是一个空序列,那么函数就返回一个只有一个空序列的迭代器
- 4行 如果输入xs不是一个空序列,那么就将xs的第一个元素赋值给h,并将剩下的元素(可能没有)赋值给t。
- @_*是Scala中的一个语法,用于匹配序列的剩余部分.
- h是一个可迭代的集合,t是一个序列,其元素类型也是可迭代的集合
- 5行 对h中元素进行迭代
- 6行 对cartesianProduct(t)返回的迭代器进行迭代,将每次迭代的结果赋值给rest
- 7行 将元素i和序列rest连接起来,形成一个新的序列; yield用于在for语句中将结果收集
新执行计划
经过上述代码改造后的MultiFullJoin, 实际执行的DAG图如下:
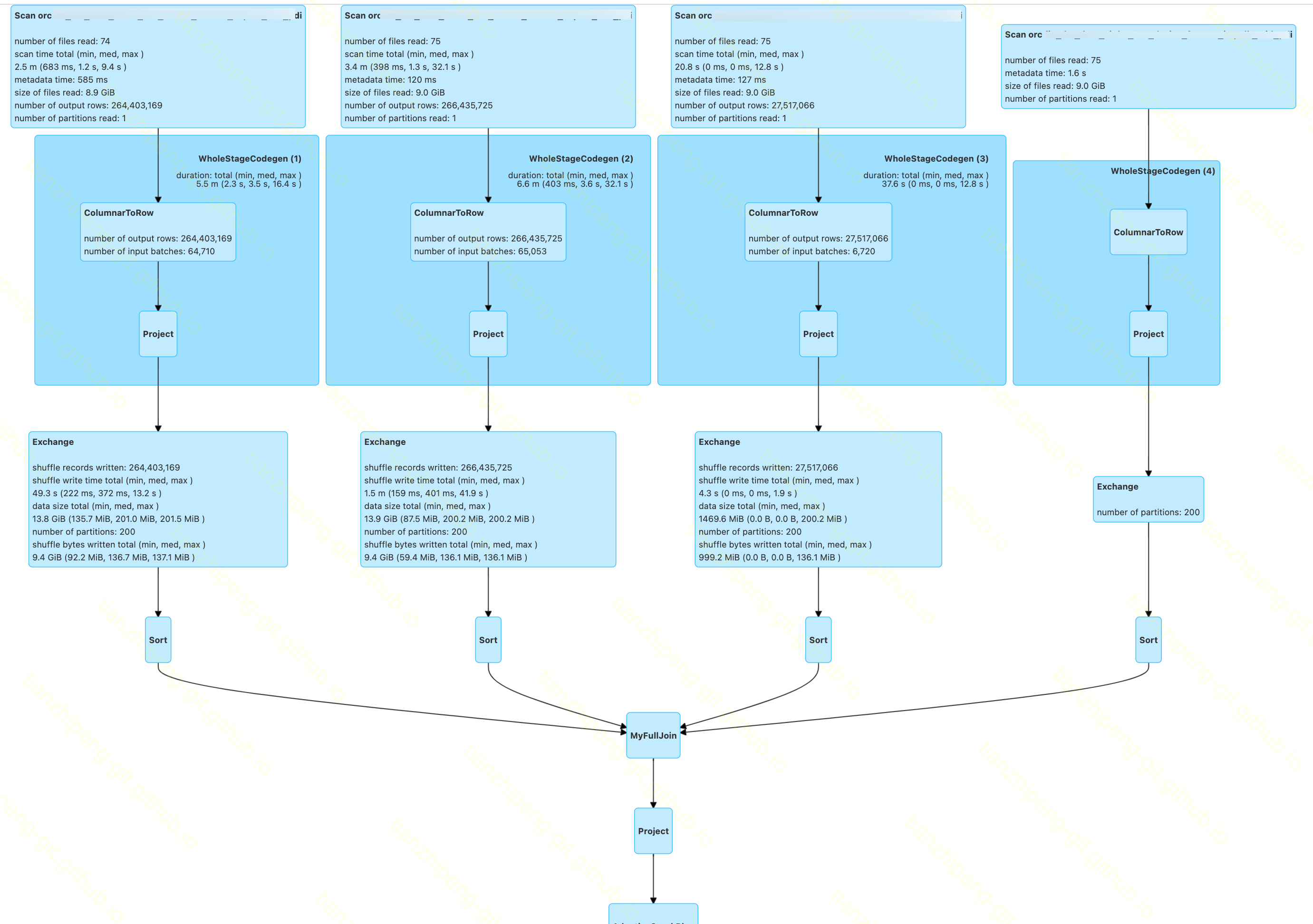
至此改造完成.
bug分析
在上述代码开发调试中遇到几个bug耗时很久, 记录一下.
找不到列
java.lang.IllegalStateException: Couldn't find a#8 in []
at org.apache.spark.sql.catalyst.expressions.BindReferences$$anonfun$bindReference$1.applyOrElse(BoundAttribute.scala:80)
我的Join算子没有对输入输出的列做任何特殊处理, 任务运行在跑task之前就报这个错误, 找不到列, 肯定不是数据的问题, 解析节点出错.
分析过程:
- 对比了我的Exec和SMJExec, 该有的都有, 不缺方法或者属性.
- 分析MultiJoin形成的dataframe:
- dataframe类有个queryExecution对象, 包含这个dataframe的
未解析的logicalPlan/解析后的analyzed计划/优化后的optimized计划, 以及规划好的SparkPlan和真实要执行的executedPlan - 发现关键处在一个Project节点上, 我的MultiJoin的执行计划中, 有一个Project算子, 字段是空的(projectList空), 字段映射没了当然报错找不到列.
- 原本的LogicalPlan没有问题, 优化后的optimized计划中, Project就有问题了.
- dataframe类有个queryExecution对象, 包含这个dataframe的
所以问题可能出在spark优化逻辑中, 查看spark优化器的规则, 初步觉得可疑的优化规则:
- RemoveNoopOperators
- ColumnPruning
- CollapseProject
接下来就没啥好说的了, 单步调试优化规则的执行, 发现确实是在列裁剪ColumnPruning中将字段搞没的:
case p @ Project(_, child) if !child.isInstanceOf[Project] =>
val required = child.references ++ p.references
if (!child.inputSet.subsetOf(required)) {
val newChildren = child.children.map(c => prunedChild(c, required))
p.copy(child = child.withNewChildren(newChildren))
} else {
p
}- 当父节点是Project, 子节点是我们MyFullJoin, 进入上述case条件.
- 根据当前节点的references和子节点的references判断必须的字段
- 将子节点的子节点, 根据必须字段列表, 进行列裁剪, 调试到这, 一剪没
Bug原因是references这个属性是根据LogicalPlan的类参数中的Expression找字段的, 我的MyFullJoin(inputs: List[(LogicalPlan, Expression)])虽然也有Expression, 但是定义在Tuple2里, 没识别到, 所以默认的references方法返回空.
解决方法很简单, 给MyFullJoin新增references方法返回正确字段即可.
输出列的时候空指针异常
org.apache.spark.sql.catalyst.encoders.ExpressionEncoder.Deserializer#apply报空指针异常. Cause by:
java.lang.NullPointerException
at org.apache.spark.sql.catalyst.InternalRow.getString(InternalRow.scala:34)
at com.tzp.xx.util.multijoin.MultiJoinedRow.getString(MultiJoinedRow.scala:125)
分析过程: 可能原因
- MultiJoinedRow的实现有问题, get字段的时候就空指针了
- 排除, 逐行检查MultiRow和原始JoinedRow, 没区别, 单测跑这个Row的实现的各个方法, 也没问题.
- 整个JoinExec的字段处理有问题, 上级几个字段, 下级几个字段, 这个Exec输入/输出是几个字段, 子的iterator几个字段
- 可能性不大, 原始的SMJExec对字段这块也没做任何处理.
- 一个现象的疑问, 可能是show导致的吧, 执行计划中, 最终project成9个StringType列了.
- 存疑
- MultiJoinedRow中 join不上的时候, 缺失的路, 确实用的
val nullRows = inputs.map(x => new GenericInternalRow(x._1.output.length))填充的- 这个GenericInternalRow有没有问题, 是否从他get东西会空指针?
- 不会, 原始join也用这个, 会判断isNullAt
- 这个GenericInternalRow有没有问题, 是否从他get东西会空指针?
- 因为row的处理过程是先保存在MultiJoinedRow,
- 然后经过
resultProj: InternalRow => InternalRow = UnsafeProjection.create(output, output)映射成unsafe了吧, - 后来又SafeProjection(A projection that could turn UnsafeRow into GenericInternalRow)转回去了
- 然后经过
- 担心是某处的isNullAt判断错误, 或者某处转化没根据isNullAt来?
- SafeProjection引用的BoundReference判断了isNullAt啊
- 不对. 有多个create方法, 实际调用的Seq[Expression]参数的, 就看expressions参数了
constructProjection = SafeProjection.create(expressions)
- 不对. 有多个create方法, 实际调用的Seq[Expression]参数的, 就看expressions参数了
- SafeProjection引用的BoundReference判断了isNullAt啊
经过原始join和自己join, debug断点到这挨个对比, 发现expressions变量不一样:
我的:
StructField(a,StringType,false)
StructField(b,StringType,true)
StructField(c,StringType,false)
...
原始:
全是StructField(b,StringType,true) 这个变量从哪生成? 从logicalPlan的output
bug原因及解决:
MyFullJoin的output少加了 .map(_.withNullability(true))
override def output: Seq[Attribute] = {
inputs.flatMap(i => i._1.output).这里
}效果不好
4个30亿的表
- 20*3+1G (200shuffle.partitions) 新的Join 1hrs, 1mins, 42sec 原始 1hrs, 7mins, 49sec
- 50*5+1G (200shuffle.partitions) 新的Join 27mins, 51sec 原始 27mins, 3sec
- 50*8+2G (400shuffle.partitions) 新的Join 24mins, 55sec 原始 25mins, 1sec
- 400*5+2G (400shuffle.partitions) 新的Join 5mins, 36sec 原始 4mins, 21sec
最终优化效果一般, 但是我觉得方案思路是没问题的, 有几点可能
- 我的Exec代码写的太次了, 某些地方不够优化
- 现在万兆网络太屌了, shuffle不太占时间了
- 在已经排序分区好的数据上, 额外执行一次Exchange和sort, 不占资源
- TODO 验证这个事:
- t1有两个一样的字段ab, 先让它按a分区排序, 再让它按b分区排序
- (t1 left join t2 on t1.a) left join t3 on t1.a
- (t1 left join t2 on t1.a) left join t3 on t1.b
没有时间再深入搞了, 感觉还是有优化空间的…
虽然没优化成功, 但是就当练习Spark执行计划的开发了:()
后记
同时将多路一起Join, 对单节点的资源的消耗肯定是比两两Join要大, Spill (memory)和Spill (disk)这两项比原始Join要大很多.
如果不用Dataframe和catalyst相关的东西, 直接用rdd来操作, 可能更加省事无bug, 但是主要是想结合sql相关的功能一起用. 转rdd再转回来, sql上的一些功能就没了.
其实这个思路还是比较简单的, 但是实现起来也搞了两三天, 因为需要从逻辑计划/物理计划/Planer/Optimizer完整的进行实现, 而且里面细节比较多, 调起来头痛.
ChatGPT在其中提供了一些帮助, 比如MultiJoinedRow这个类完全由gpt自动生成, 提示了两下, 基本ok无bug, 但是太复杂太细节的东西还是要靠自己.