spark硬核优化1 布隆过滤器大join优化

借助布隆过滤器解决两个大表join的性能问题. 这里是回忆整理了之前的两个case写成博客, 应该是最后两篇关于spark的博客了.
分享记录几个在实际工作中解决的几个硬核spark优化的case, 所谓硬核就是不是简单的改改sql/调调配置就能解决的, 需要深入spark内部原理, 修改/扩展spark源码才能实现的优化.
布隆过滤器解决两个大表join
场景
-
广告请求数据
我们的业务是程序化广告场景, 在这个业务中, 媒体侧(头腾快百)会将要展现广告的机会实时通过api发送给广告主(通过DSP或者自有RTA的形式), 广告主返回竞价信息. 这个过程产生的数据我们称为
广告请求数据, 广告主侧可以保存下来. 由于广告主对接多家媒体的很多app, 这个广告请求的量级是相当大的, 每天达到千亿万亿条. -
广告曝光数据
另外, 媒体app中如果真的将某条广告展现给用户了, 媒体还会将展现的信息实时通过api发送给广告主, 这个数据我们称为
广告曝光数据, 这个量级是每天亿级别的. -
转化漏斗
在做分析的时候, 一个非常场景的是做转化漏斗分析. 即从不同维度去看, 从初始的这些广告请求数据, 有多少量级成功转化为曝光数据, 曝光之后有多少转化为点击, 点击转化为注册登录, 等等. 在做这个分析的时候, 我们需要将广告请求数据和广告曝光数据进行join.
但是从刚才讲到的量级来看这两个表都非常大, 每天都是TB级, 为了节省资源加快计算, 我们之前做了如下改进.
-
前期尝试的优化
- 任务拆分
按天拆分,
1天请求 join 1天曝光, 再拆分媒体,A媒体1天请求 join A媒体1天曝光, 拆分之后再join, 量其实也很大 - 传统的调整参数, map join等等手段.
- 同时我们为了节省资源, 我们只关注转化为曝光的请求, 也即改为
曝光 left join 请求
- 任务拆分
按天拆分,
我们观察到这两份数据有一个特点, 左表(曝光)的量级是右表(请求)的1/1000, 请求数据中绝大多数都没必要参与计算的, 有什么方法能够对请求过滤一下, 只shuffle部分请求, 从而加快计算呢?
布隆过滤器介绍
思考?
假设我们有百亿千亿个32位的字符串(md5hex), 然后给定一个要查询的md5hex字符串, 如何判断它是否在这个集合中呢? 我随便写一些思路
- 逐个遍历判断?
- 用一个哈希set/字典结构来判断? 所需要的内存是单机能够承受的么?
-
用一种bitset(位图)的结构, 将所有字符串哈希&取余得到一个索引, 用索引位置的0或者1表示是否存在于这个集合中.
一个字符串确实是占用1个bit位了, 但是总共哈希空间要多大啊? 哈希碰撞了怎么办?
这个bitset的思路虽然有些问题, 但是也引出了接下来的布隆过滤器的方案.
布隆过滤器BloomFilter
A bloom filter is a probabilistic data structure that is based on hashing. It is extremely space efficient and is typically used to add elements to a set and test if an element is in a set. Though, the elements themselves are not added to a set. Instead a hash of the elements is added to the set.
布隆过滤器是一种基于哈希的概率数据结构。它具有极高的空间效率,通常用于将元素添加到集合中并测试元素是否在集合中。不过,元素本身并没有添加到集合中。相反,元素的散列被添加到集合中。
人话解释一下, 布隆过滤器是一种集合, 可以用来判断一个元素是否存在于一个集合中, 空间效率极高.
上述百亿千亿的字符串, 如果直接放在内存, 可能要几百个G, 但是在布隆过滤器, 顶多也就几个G, 几个G是单机内存(尤其是在spark的executer中)可以接受的

简单介绍一下BloomFilter的过程, 不是本文重点.
- BloomFilter内部也有一个bitset空间, 初始都是0
- 将每个初始元素(图中x,y,z), 进行k=3次哈希, 得到3个位置, 将3个位置置为1
- 初始元素都处理好之后, 这个bitset空间有很多位置被xyz置为了1
- 对于一个新元素w, 要判断w是否存在于这个集合中, 也将w进行3次相同的哈希得到3个位置
- 如果这3个位置都是1, 那么w大概率存在于这个集合中
- 如何这3个位置有任何一个是0, 那么w一定不存在于这个集合中
这个算法需要调整bitset空间的大小, 哈希次数k等参数, 是一个概率数据结构.
有一定的假正率, 没有假负率. (召回率100%, 精度<100%)
对于我们的场景, 提前过滤请求减少shuffle数据量这个需求来讲, 多漏过一些假正的请求不影响正确性, 只要没有假负就好了, 恰好满足需求.
实现
自己实现
既然有了这个思路, 接下来考虑如何在spark中实现这个过程, 我不需要在sql语言层面改动, 只要支持两个dataframe使用bloomfilter过滤再join就可以了. 我的设计思路是这样的:
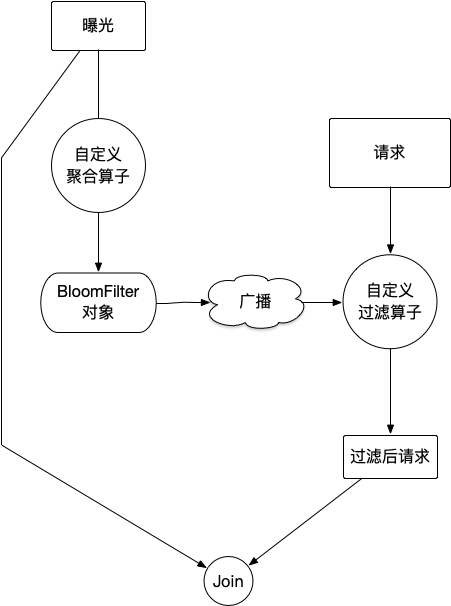
这个实现方案有一些要点:
- Bloomfilter的实现: 自己写一个太吃力不讨好了, 之前研究druid的时候, 看过druid中bloomfilter是使用datasketches包中的实现的, 可以用这个.
- 聚合算子: bloomfilter结构支持merge, 所以可以先单partition内部聚合成bloom结构, 然后多个bloom结构merge合并为一个.
- 广播: 采用广播的方案将制作好的Bloomfilter传递给下一步使用. 因为我们对错误率/精度的要求不高, 但是内存占用希望小一点, 这个bloom结构要广播到所有执行节点内存中.
- 过滤: 过滤同上考虑内存问题, 使用map_partitons类的算子, 每个executor只在内存中加载和保留一份bloom结构, 不要每次都重新加载.
大神的提交
在实现上述方案的过程中, 搜索到已经有大神们想到了这个优化方向. 其中
- 京东分享了一个博客但是没有代码开源
- facebook分享提到了这个方案
- ebay的Yuming Wang为社区提交了一个PR
既然已经有大神实现了, 我就不重复造轮子了, 上述只有那个PR是开源有代码的, 所以就尽量复用大神的逻辑.
当时这个PR还没有被合并, 在spark3.3版本后被合并了
我研究了其中的代码, 直接摘了关键部分copy到我们项目中.
这里是我构造的BloomFilterJoin的入口方法:
def leftjoin(spark:SparkSession,
mainSide: DataFrame, mainSideKey: String,
buildSide: DataFrame, buildSideKey: String,
estimatedNumItems:Long = 40000000L
): DataFrame = {
//聚合
val aggFunc = new BloomFilterAggregate(
XxHash64(Seq(mainSide(mainSideKey).expr), 42L),
Literal(estimatedNumItems)
)
val namedExprs = Array(Alias(aggFunc.toAggregateExpression(), "my_bf_agg")())
val aggregate = ConstantFolding(ColumnPruning(Aggregate(Nil, namedExprs, mainSide.queryExecution.analyzed)))
val bloomFilterSubquery = ScalarSubquery(aggregate, Nil)
//过滤
val filter = BloomFilterMightContain(bloomFilterSubquery, new XxHash64(Seq(buildSide(buildSideKey).expr)))
val logical = Filter(filter, buildSide.queryExecution.analyzed)
//最终join
val r = new Dataset[Row](spark, logical, RowEncoder(logical.schema))
val joint = mainSide.join(r, mainSide(mainSideKey) === r(buildSideKey), "left")
joint
}其实和之前说的一样, 也是分为三步: 聚合出Bloomfilter, 过滤, 实际join. 接下来按顺序介绍一下.
聚合
聚合部分(BloomFilterAggregate类)的核心代码:
// 创建聚合缓存, 这里的BloomFilter用的是org.apache.spark.util.sketch.BloomFilter
override def createAggregationBuffer(): BloomFilter = {
BloomFilter.create(estimatedNumItems, numBits)
}
// 单条数据放入BloomFilter
override def update(buffer: BloomFilter, inputRow: InternalRow): BloomFilter = {
val value = child.eval(inputRow)
if (value == null) {
return buffer
}
buffer.putLong(value.asInstanceOf[Long])
buffer
}
// 两个BloomFilter合并操作
override def merge(buffer: BloomFilter, other: BloomFilter): BloomFilter = {
buffer.mergeInPlace(other)
} 过滤
过滤部分(BloomFilterMightContain类)的核心代码:
//反序列化BloomFilter
@transient private lazy val bloomFilter = {
val bytes = bloomFilterExpression.eval().asInstanceOf[Array[Byte]]
if (bytes == null) null else deserialize(bytes)
}
//使用BloomFilter判断一行是否应该被过滤掉
override def eval(input: InternalRow): Any = {
if (bloomFilter == null) {
null
} else {
val value = valueExpression.eval(input)
if (value == null) null else bloomFilter.mightContainLong(value.asInstanceOf[Long])
}
}ScalarSubquery?
这里有个关键的问题, 聚合的结果(BloomFilter对象), 是如何传递给过滤操作的, BloomFilterMightContain中是直接反序列化bloomFilterExpression.eval()的?
从我的串联代码可以看出, 他反序列化的对象是val bloomFilterSubquery = ScalarSubquery(aggregate, Nil)
原来大神利用了spark中的ScalarSubquery功能, 而不是像我想的那种利用广播去做, 这个还是挺方便的!
ScalarSubquery: A subquery that will return only one row and one column(返回一行一列的子查询). This will be converted into a physical scalar subquery during planning.
spark也有子查询啊, org/apache/spark/sql/catalyst/expressions/subquery.scala, org/apache/spark/sql/execution/subquery.scala, 子查询结果是如何传输的呢?
Expression or 执行计划
大神设计的另一个简便快捷的地方在于, 上述BloomFilterAggregate类和BloomFilterMightContain类都是继承自Expression, 他们不是逻辑计划而是表达式!
这样的好处就是, 可以直接复用现有的Aggregate和Filter的逻辑计划和物理计划, 无需重写相关的code了.
Expression体系: “不需要执行引擎, 可以直接进行计算的单元”
在实际使用中可以看到, 我借助Aggregate和Filter把这些expression组织成了逻辑计划, 然后用val r = new Dataset[Row](spark, logical, RowEncoder(logical.schema))将逻辑计划转为Dataframe, 非常方便.
效果
如此改造后的BloomFilterJoin, 实际执行的DAG如图:
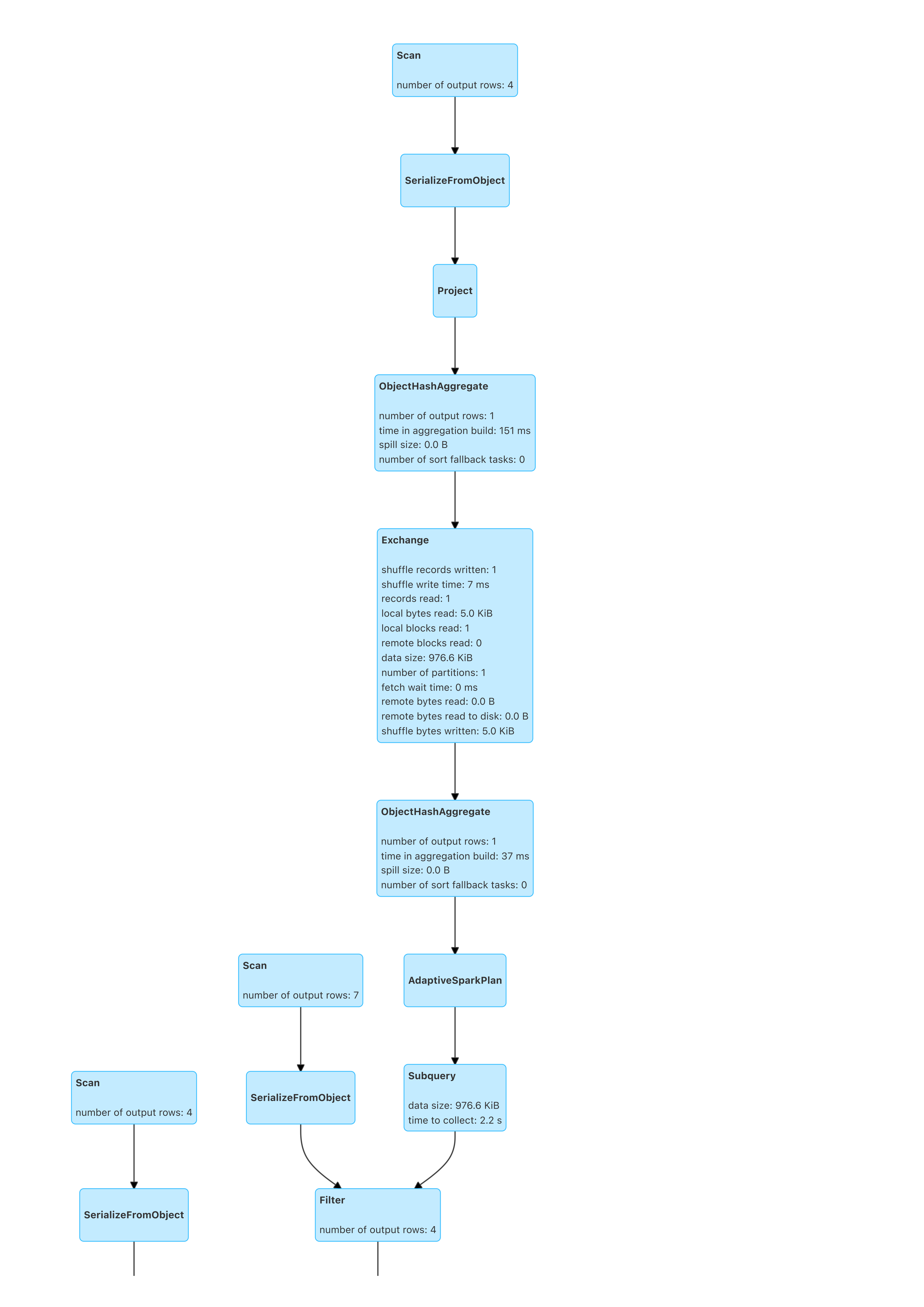
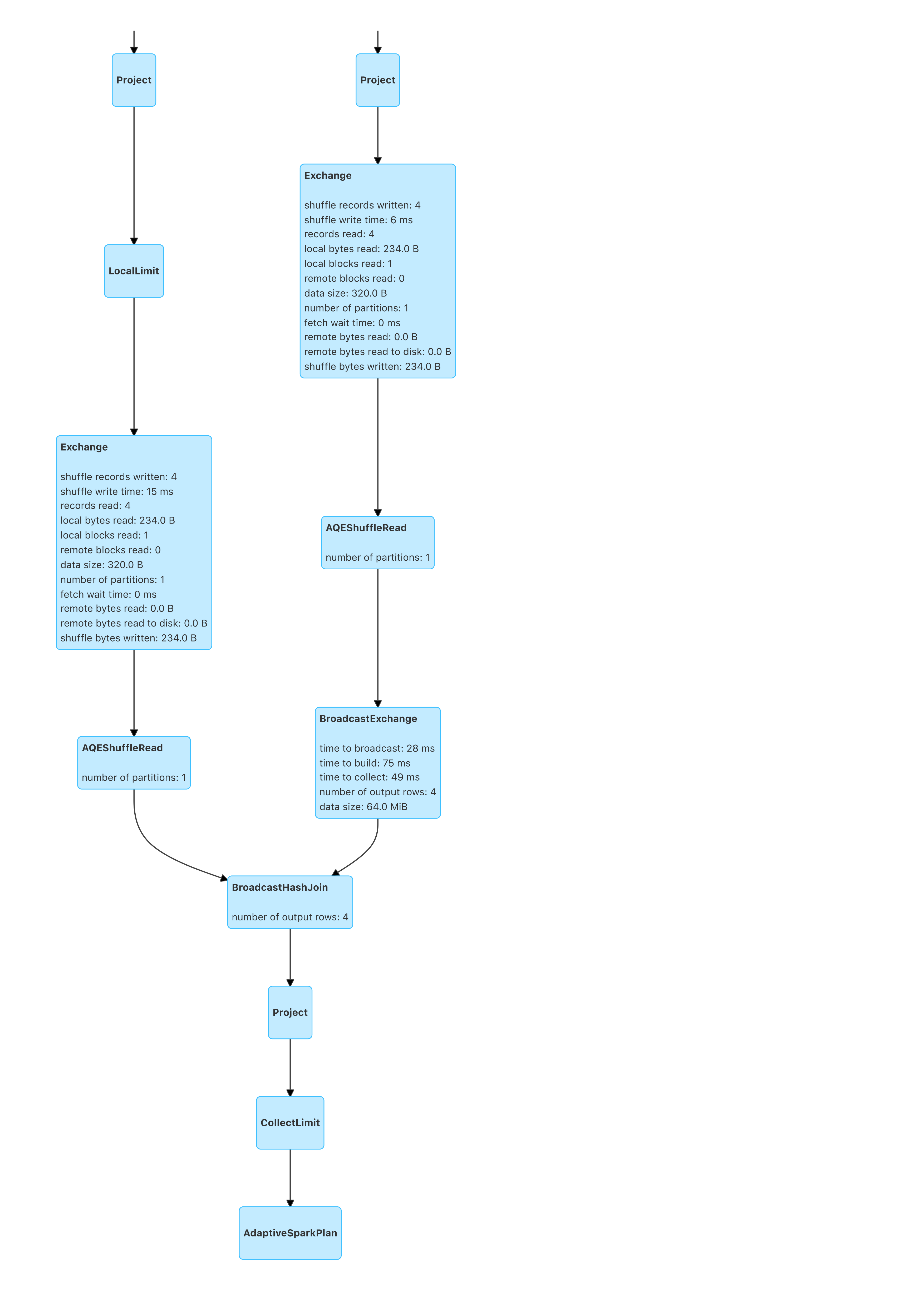
实际优化效果: 原本4个小时的任务压缩到40分钟左右!!