spark硬核优化2 limit优化

深入分析和解决大量级的limit速度过慢的问题, limit执行原理.
这里是回忆整理了之前的两个case写成博客, 应该是最后两篇关于spark的博客了.
分享记录几个在实际工作中解决的几个硬核spark优化的case, 所谓硬核就是不是简单的改改sql/调调配置就能解决的, 需要深入spark内部原理, 修改/扩展spark源码才能实现的优化.
长文预警, 没想到这个limit写了这么多.
limit速度为什么这么慢?
问题
limit语句在日常跑数的时候我们都经常使用, 比如想看一下数据的样子, 一般都会执行
select * from x limit 100;这个语句的执行速度一般都非常快, 秒级就看到数据展示出来了.
但是有时候有一些场景中, 我们需要limit的量级太大, 用limit就会出奇的慢, 比如从一个100亿的表中limit 1亿或者从1亿1千万的表中limit 1亿都比预想的慢的多, 执行时间小时级了.
原因
我最初关于limit的执行过程的设想是这样的:
- 直接拿第一个partition按行读, 读够了limit数量直接返回.
- 即使第一个partition内的数量不够, 再打开第二个partition继续读.
- 就算
limit-1亿, 整个过程都退化成单线程的过程, 顶多是单机read 1亿行的时间, 应该也不会慢到那种程度啊?
但实际spark执行应该不是我想象的那样. 分析为什么执行慢, 先查看对应任务spark页面, 发现在某个stage上开始单task执行了, 卡点可能在这里.
在具体分析其内部执行原理前, 我忽然发现几种limit的场景还有些不同, 这里展示了一下.
几种limit使用场景
情况一(Query 5), limit之后采集到driver端作为结果(action算子)
val df = spark.table("db1.table1")
df.count() //57 0711 4895
df.show(1000000)
== Physical Plan ==
CollectLimit (4)
+- * Project (3)
+- * ColumnarToRow (2)
+- Scan orc db1.table1 (1)
情况二(Query 6), limit之后写出表/文件
val df1 = spark.sql("select * from df limit 100000")
df1.write.csv("/user/tianzhipeng-jk/temp1107")
== Physical Plan ==
Execute InsertIntoHadoopFsRelationCommand (11)
+- AdaptiveSparkPlan (10)
+- == Current Plan ==
GlobalLimit (6)
+- ShuffleQueryStage (5)
+- Exchange (4)
+- * LocalLimit (3)
+- * ColumnarToRow (2)
+- Scan orc db1.table1 (1)
+- == Initial Plan ==
GlobalLimit (9)
+- Exchange (8)
+- LocalLimit (7)
+- Scan orc db1.table1 (1)
情况三(Query 9), limit之后继续参与后续的变换运算(limit之后作为df)
val other = spark.table("db1.table2")
other.createOrReplaceTempView("other")
val df2 = spark.sql("select * from other a left join (select * from df limit 1000000) b on a.deviceid=b.deviceid")
df2.show(100000)
== Physical Plan ==
AdaptiveSparkPlan (34)
+- == Final Plan ==
CollectLimit (21)
+- * Project (20)
+- * SortMergeJoin LeftOuter (19)
:- * Sort (7)
: +- AQEShuffleRead (6)
: +- ShuffleQueryStage (5), Statistics(sizeInBytes=88.7 MiB, rowCount=1.66E+6)
: +- Exchange (4)
: +- * LocalLimit (3)
: +- * ColumnarToRow (2)
: +- Scan orc db1.table2 (1)
+- * Sort (18)
+- AQEShuffleRead (17)
+- ShuffleQueryStage (16), Statistics(sizeInBytes=53.4 MiB, rowCount=1.00E+6)
+- Exchange (15)
+- * Filter (14)
+- * GlobalLimit (13)
+- ShuffleQueryStage (12), Statistics(sizeInBytes=106.8 GiB, rowCount=2.05E+9)
+- Exchange (11)
+- * LocalLimit (10)
+- * ColumnarToRow (9)
+- Scan orc db1.table1 (8)
可以看出, 主要区别还是limit之后是作为结果收集到driver还是作为df参与后续计算, 从里面可以看出不同场景对应的物理执行计划算子是不同的
limit对应的物理执行计划算子
结合上面执行计划中的算子搜索了一番, 发现其源码都位于org/apache/spark/sql/execution/limit.scala, 这个源文件中包含所有limit相关的物理执行计划算子.
-
CollectLimitExec:
Take the first limit elements and collect them to a single partition. This operator will be used when a logical Limit operation is the final operator in an logical plan, which happens when the user is collecting results back to the driver.
取前面的若干个限制元素,并将它们收集到一个单独的分区。这个运算符将用于逻辑计划中的最后一个逻辑限制操作,当用户将结果收集回驱动程序时会发生这种情况。
-
CollectTailExec:
Take the last limit elements and collect them to a single partition.This operator will be used when a logical Tail operation is the final operator in an logical plan, which happens when the user is collecting results back to the driver.
取最后的若干个限制元素,并将它们收集到一个单独的分区。这个运算符将用于逻辑计划中的最后一个逻辑尾部操作,当用户将结果收集回驱动程序时会发生这种情况。
- BaseLimitExec: 下述LocalLimitExec/GlobalLimitExec算子的基类.
-
LocalLimitExec:
Take the first limit elements of each child partition, but do not collect or shuffle them.
取每个子分区的前若干个限制元素,但不进行收集或洗牌。
-
GlobalLimitExec:
Take the first limit elements of the child’s single output partition.
取子节点的单个输出分区的前若干个限制元素。
-
TakeOrderedAndProjectExec:
Take the first limit elements as defined by the sortOrder, and do projection if needed. This is logically equivalent to having a Limit operator after a SortExec operator, or having a ProjectExec operator between them. This could have been named TopK, but Spark’s top operator does the opposite in ordering so we name it TakeOrdered to avoid confusion.
val df3 = spark.sql(“select * from other a left join (select * from df order by score limit 1000000) b on a.deviceid=b.deviceid”)
这些物理算子, 在SparkPlanner的策略中被配置:
- SpecialLimits策略中, 根据一些条件, 将逻辑计划转为CollectLimitExec或TakeOrderedAndProjectExec等物理算子
- BasicOperators策略中, 在不满足上述条件情况下的limit逻辑计划, 转为LocalLimitExec和GlobalLimitExec物理算子
根据上面场景举例, 我们只分析这3个Exec的原理
- 结果收集到driver: CollectLimitExec
- 作为df参与后续计算: LocalLimitExec和GlobalLimitExec配合
CollectLimitExec/LocalLimitExec/GlobalLimitExec原理
CollectLimitExec的doExecute方法
val locallyLimited = childRDD.mapPartitionsInternal(_.take(limit))
new ShuffledRowRDD(
ShuffleExchangeExec.prepareShuffleDependency(
locallyLimited,
child.output,
SinglePartition,
serializer,
writeMetrics),
readMetrics)
}
singlePartitionRDD.mapPartitionsInternal(_.take(limit))分为三步:
- 对于子RDD(上游RDD), 使用mapPartitionsInternal, 对每个partitions执行取前1亿行的操作
- 将第一步输出RDD进行shuffle, 混洗成一个单分区RDD(SinglePartition)
- 对单分区RDD再做一次取前1亿行的操作
好家伙, 破案了, 这个limit要执行多少次数1亿行的操作啊, 确实会比前文我设想的单机读1一行慢多了:
假使100个分区, 相当于先并行的进行了100次数1亿行的操作, 重点是要将这些100*1亿的数据shuffle到一个分区, 再在这个分区上执行1次数1亿行的操作, 光shuffle到一个分区这一步就是不可接受的了.
还好的一点是, 没人会想要limit-1亿之后, 把1亿行show展示在console上, 否则这肯定执行不出来啊?
再看一下LocalLimitExec/GlobalLimitExec
这两个类里面基本都没有代码, 其doExecute方法继承自基类:
protected override def doExecute(): RDD[InternalRow] = child.execute().mapPartitions {
iter => iter.take(limit)
}
雾草, 这个还上述CollectLimitExec如出一辙啊, 也就是LocalLimit在每个分区取1亿. GlobalLimit最终再取一亿, 中间借助spark-sql的Exchange算子做shuffle, 在GlobalLimit定义了
override def requiredChildDistribution: List[Distribution] = AllTuples :: Nil
AllTuples也是单分区的啊, 逻辑几乎一模一样, 真坑啊
CollectLimitExec真实原理和limitScaleUpFactor增量式limit
在研究过程中, 发现一个spark中关于limit的参数spark.sql.limit.scaleUpFactor, 在仔细研究后发现, 刚才的分析有一个地方出错了!!
SparkPlan类的executeTake
上述配置被加载到SQLConf.limitScaleUpFactor, 它只在一个地方被调用, 就是SparkPlan类的executeTake方法.
SparkPlan类就是我们所有物理执行算子的基类, 我一般都只关注其doExecute方法, 子类实现的时候一般也只覆盖doExecute方法, 那这个executeTake是干嘛用的呢?
executeTake方法注释中写道Runs this query returning the first n rows as an array. 看起来就是获取dataframe前几行数据用的, 和limit几乎很像, 当然executeTake是把这几行数据作为数组返回的, 是driver端使用的.
其核心代码逻辑如下:
val childRDD = getByteArrayRdd(n)
val buf = new ArrayBuffer[InternalRow]
val totalParts = childRDD.partitions.length
var partsScanned = 0
while (buf.length < n && partsScanned < totalParts) {
//-- ① --
var numPartsToTry = 1L // 本轮要尝试扫描的partition数量, 初始是1.
if (partsScanned > 0) { // 已经扫过了一些partition, 但是还没凑够n行数据, 那么这轮扫描的partition数量要加倍
val limitScaleUpFactor = Math.max(conf.limitScaleUpFactor, 2)
if (buf.isEmpty) {
numPartsToTry = partsScanned * limitScaleUpFactor
} else {
val left = n - buf.length
numPartsToTry = Math.ceil(1.5 * left * partsScanned / buf.length).toInt
numPartsToTry = Math.min(numPartsToTry, partsScanned * limitScaleUpFactor) //根据缺少的行数 和 放大系数共同决定一个本次part数
}
}
//-- ② --
val parts = partsScanned.until(math.min(partsScanned + numPartsToTry, totalParts).toInt)
val sc = sparkContext
//这里有三个要点
// 1. runJob的最后一个参数可以指定本个job在rdd的哪些partition是执行, 可以不在所有part上执行
// 2. runJob的第二个参数`func: Iterator[T] => U`直接返回的it.next(), 这个it是第一行getByteArrayRdd处理好的数据行
// 3. runJob的返回值是一个内存数组, driver端的
val res = sc.runJob(childRDD, (it: Iterator[(Long, Array[Byte])]) =>
if (it.hasNext) it.next() else (0L, Array.emptyByteArray), partsToScan)
//-- ③ --
var i = 0
while (buf.length < n && i < res.length) {
val rows = decodeUnsafeRows(res(i)._2)
if (n - buf.length >= res(i)._1) {
buf ++= rows.toArray[InternalRow]
} else {
buf ++= rows.take(n - buf.length).toArray[InternalRow]
}
i += 1
}
partsScanned += partsToScan.size
}主体是一个循环, 每轮循环会读取一定量的partition里的行. 循环内代码大概3步:
- 决定本轮要尝试扫描的partition数量. 是根据
缺少的行数和放大系数共同决定的. 简单理解可以看做第一次扫描1个partiton, 第二次扫描2个partition, 第三次扫描4个partition(不重复的) - 第二步使用runJob将要扫描的parition的行读取到driver.
- 第三步将limit所需数量的行, 解码放入buffer
这种增量式的limit, 和我之前构想的类似, 不需要shuffle, 而且比我设想的更好, 有个增量设计, 虽然也只能是单线程的.
那么这个executeTake何时被使用呢? 在limit中不涉及么? 通过idea查看executeTake方法被调用的地方:
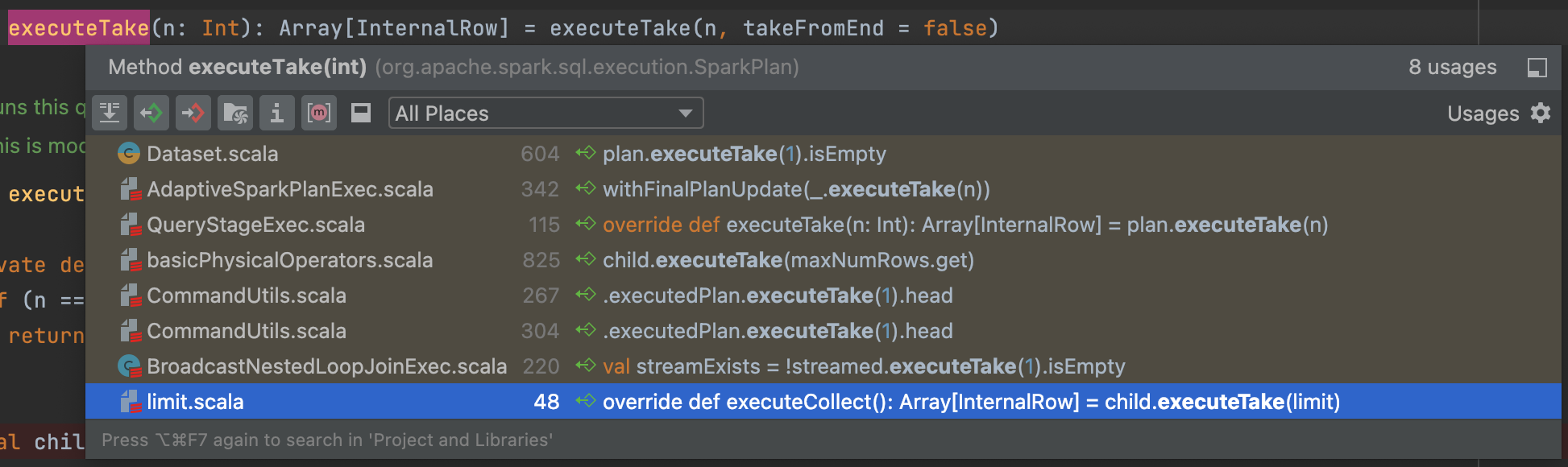
可以看出是在很多框架内部的各类工具性质的地方被使用, 它们可能偶尔需要用的rdd的几行数据, 则调用这个. (eg. 读取带header的csv时)
但是, 可以看出图中最后一行, 它在limit.scala中被使用了!!
CollectLimitExec.executeCollect
追踪过去可以看到在CollectLimitExec中
override def executeCollect(): Array[InternalRow] = child.executeTake(limit)
呃呃, 又多个executeCollect方法, 它调用了上述的executeTake… 不想再追踪代码了, 为了探究在实际使用limit的时候是用的CollectLimitExec的doExecute还是executeCollect方法, 我直接本机debug加断点执行了一下:
-
无limit直接show df
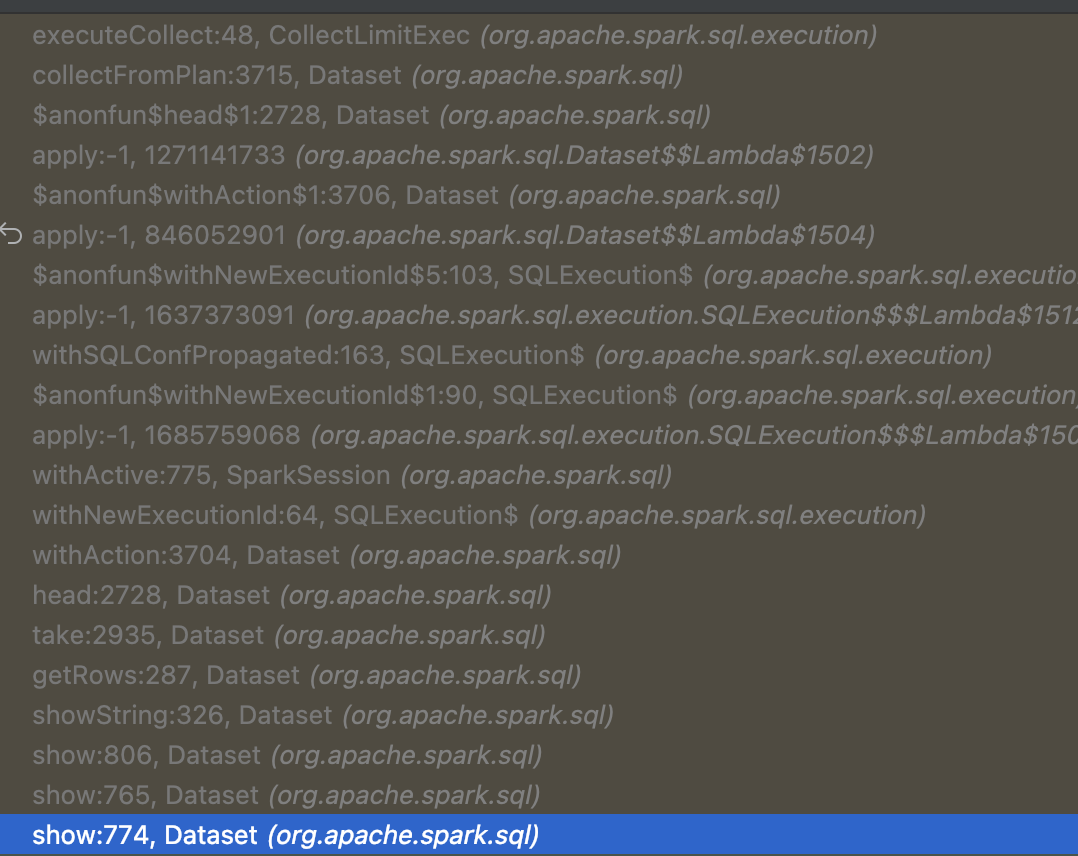
-
limit之后show
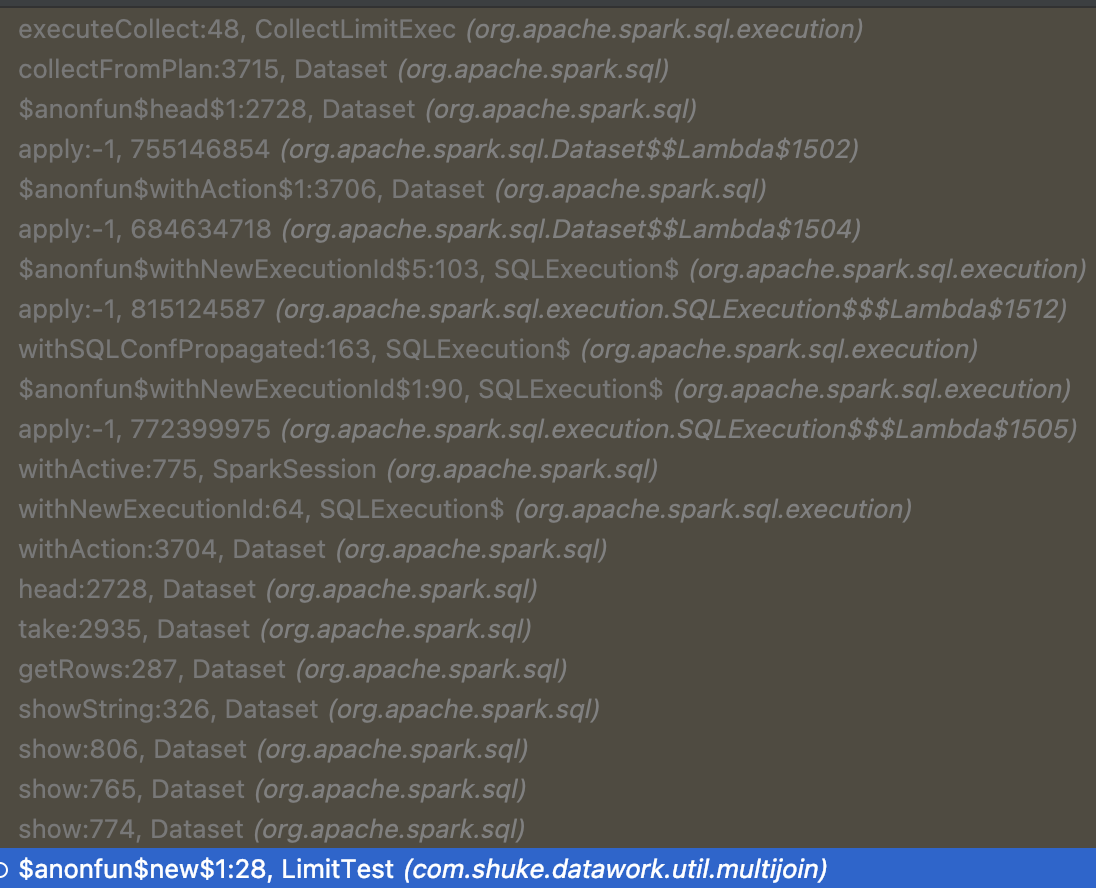
可以看出, 确实使用的是executeTake的增量式limit逻辑!
但是这个逻辑仅仅在如下情况下能用, 其他的场景像是limit之后作为df, 肯定是用不上了.
- 框架内部工具, 偶尔会执行rdd.executeTake获取几行数据.
- CollectLimitExec算子, 也就是limit之后collect到driver端的情况.
解法
其实分析了一大波limit为什么这么慢, 对于解决这个问题好像帮助不大, 即使是改进的增量式limit, 依旧是单机limit, 速度还是慢. 接下来, 我根据需求的3种不同情况, 设计了对应的解决方案.
以下解决方案, 都是并行的, 都不涉及数据shuffle, 速度那是比原来的快的多.
不精确limit-1亿方案
有些时候其实只是需要limit控制一下数据量, 不是精准的1亿, 多几万少几万个也没关系的话, 就有一些不精准但快速的解决办法.
以下我写的三种都是利用随机数的方案, 首先我们要确定总数据量级和要抽取的数据量级, 比如分别是100亿和1亿, 那么我们要抽取的比例就是1/100.
-
TABLESAMPLE
SELECT * FROM test TABLESAMPLE (50 PERCENT)根据文档TABLESAMPLE有三种参数写法, 百分比(👆), 分数(
TABLESAMPLE(BUCKET x OUT OF y))和行数TABLESAMPLE(x ROWS).⚠️⚠️⚠️ 不要以为用这个行数的写法就能直接实现快速的limit, 它本质上还是调用上述spark内部的limit实现的, 速度还是很慢. 前两种随机抽取的是真并行的, 很快.
//org.apache.spark.sql.catalyst.plans.logical.Sample //org.apache.spark.sql.execution.SampleExec //org/apache/spark/spark-catalyst_2.13/3.2.0/spark-catalyst_2.13-3.2.0-sources.jar!/org/apache/spark/sql/catalyst/parser/AstBuilder.scala:1200 ctx.sampleMethod() match { case ctx: SampleByRowsContext => // 注意这里, 如果是TABLESAMPLE(x ROWS), 直接解析成Limit逻辑节点了!!! Limit(expression(ctx.expression), query) case ctx: SampleByPercentileContext => val fraction = ctx.percentage.getText.toDouble val sign = if (ctx.negativeSign == null) 1 else -1 sample(sign * fraction / 100.0d)从一个57亿的表随机抽约1亿的执行时间: 2.3 min
- df.sample(0.01)和rdd.sample(0.01)
-
rand
select * from x where rand() < 0.01
精确limit-1亿方案
如果真的一定要正正好好1亿条数据, 那么也有一些快一点的方案
直接分区take
假设我们的数据各分区量级均匀, 那么我们在每个分区取一部分, 合起来等于总需求量就好了. 比如最终要1亿, 一共50个分区, 那么每个分区取200万就可以.
implicit val encoder = RowEncoder(df.schema)
df.mapPartitions((a)=>a.take(2853557))
从一个57亿的表随机抽约1亿的执行时间: 3.1 min
当然这种用法就担心分区不均匀, 某个分区不够200万, 但实际工作中很少遇到, 所以效果实际不错.
分区count/分区take
如果担心上面各分区直接take200万不太放心, 可以优化一下, 先统计各分区条数, 分配一下总共1亿在各分区取多少, 然后再take
// ① 统计每个分区内行数
val x = df5.mapPartitions((a) => {
val pid = TaskContext.getPartitionId()
Iterator((pid, a.size))
})
val countByPart = x.collectAsList()
print(countByPart) //[(0,400), (1,400), (2,400), (3,400), (4,400)]
// ② 分配各分区应该take的数量. 随便写个呆呆的算法.
var limit = 900
val takeByPart = new Array[Int](countByPart.size)
for (a <- 0 until countByPart.size) {
val take = if (limit > 0) {
Math.min(limit, countByPart.get(a)._2)
} else {
0
}
limit = limit - take
takeByPart(a) = take
}
print(takeByPart.mkString("(", ", ", ")")) //(400, 400, 100, 0, 0)
val takeByPartBC = spark.sparkContext.broadcast(takeByPart)
// ③ 分区take结果
val result = df5.mapPartitions((a) => {
val pid = TaskContext.getPartitionId()
val take = takeByPartBC.value(pid)
a.take(take)
})
assert(result.count() == 900)精确且真随机1亿方案
哈哈, 其实这里就是玩一下蓄水池抽样而已. 当然可能也有实际场景需求:
假设我们要从100亿中精确取1亿, 且保证每条数据被取出的概率是一样的, 而不是从前面拿出100条来.
上述sample和random确实是随机的, 但是不能保证输出数量的可控, 又要随机, 又要概率一样, 输出数量固定, 那不就是蓄水池抽样了.
实现起来也很简单, 总量M, 抽取N, 被选中的概率是N/M, 那么跟上面分区count/分区take的写法类似:
- 分区count统计每个分区的总量
xi - 那么每个分区应该抽取的数量就是
xi * N/M - 再mapPartitions处理, 每个分区内进行蓄水池抽样, 取
xi * N/M条.
// ① 统计每个分区内行数
val x = df5_r.mapPartitions((a) => {
val pid = TaskContext.getPartitionId()
Iterator((pid, a.size))
})
val countByPart = x.collectAsList()
print(countByPart) // [(0,379), (1,402), (2,605), (3,403), (4,211)]
// ② 分配各分区应该take的数量. xi * N/M
val limit = 900
val total = df5_r.count()
val takeByPart = new Array[Int](countByPart.size)
for (a <- 0 until countByPart.size) {
val take = ((countByPart.get(a)._2 * limit) / total).toInt
takeByPart(a) = take
}
print(takeByPart.sum)
print(takeByPart.mkString("(", ", ", ")")) //(170, 180, 272, 181, 94)
val takeByPartBC = spark.sparkContext.broadcast(takeByPart)
// ③ 分区内蓄水池抽样
val result = df5_r.mapPartitions((stream) => {
val pid = TaskContext.getPartitionId()
val k = takeByPartBC.value(pid)
val reservoir = new Array[Row](k)
val random = new Random()
var i = 0
while (i < k && stream.hasNext) {
reservoir(i) = stream.next()
i += 1
}
while (stream.hasNext) {
val j = random.nextInt(i + 1)
if (j < k) reservoir(j) = stream.next()
i += 1
}
reservoir.iterator
})
print(result.count())参考
- spark源码, org/apache/spark/sql/execution/limit.scala
- 文中英文翻译由chatgpt提供
- Query 5 limit后show的执行截图
- Query 6 limit后写出的执行截图
- Query 9 limit后join的执行截图
- Query 2 limit前sort的执行截图